AI agents are the next wave of artificial intelligence systems and are far more advanced than the typical AI chatbots most of us are familiar with. But what exactly is an AI agent or an LLM agent? You can think of them as your very own online butler, who can tell you what the weather is, reschedule your travel plans, and notify you when everything is done.
They can plan, reason, and interact with external tools, such as APIs, search engines, or calendars, to complete complex tasks that require multiple steps without having to break a sweat. As these agents become part of our daily lives, it’s important to evaluate how they work.
A seemingly sound output might hide inefficient steps, faulty logic, or unsafe shortcuts. For instance, an AI agent booking a trip might say it did, but behind the scenes, it could’ve chosen long layovers, a far-off hotel, or the wrong calendar time.
If we can capture every step an AI agent takes, their internal thoughts, tool calls, and real-world observations, we can bring a new level of transparency and control to AI behavior. That’s what AI agent trajectory evaluation aims to do. It is a crucial method that tracks how an agent thinks and acts in a step-by-step manner.
In this article, we’ll break down what agent trajectories are and how they’re used in AI agent evaluation. We’ll also discuss how Objectways helps businesses evaluate and improve their AI agents. Let’s get started!
An AI agent’s trajectory is a step-by-step record of what the agent sees, thinks, and does to complete a given task. It captures everything from the agent’s initial observation to its final result. This includes every decision, action, and the feedback it takes and receives along the way from its environment. If we review the full trajectory an AI agent took, we can get a better understanding of how it thinks and works. This is especially useful when fine-tuning AI agents for specific tasks.
For example, a sales team using an AI agent to shortlist promising clients needs more information than just the final list. They need to see how the agent picked the clients in that list. A clear step-by-step AI agent trajectory (like filtering by industry, checking LinkedIn activity, or ranking by funding) can build trust and refine the whole process.
An AI agent’s trajectory consists of several interconnected elements. Here are some of the key elements:
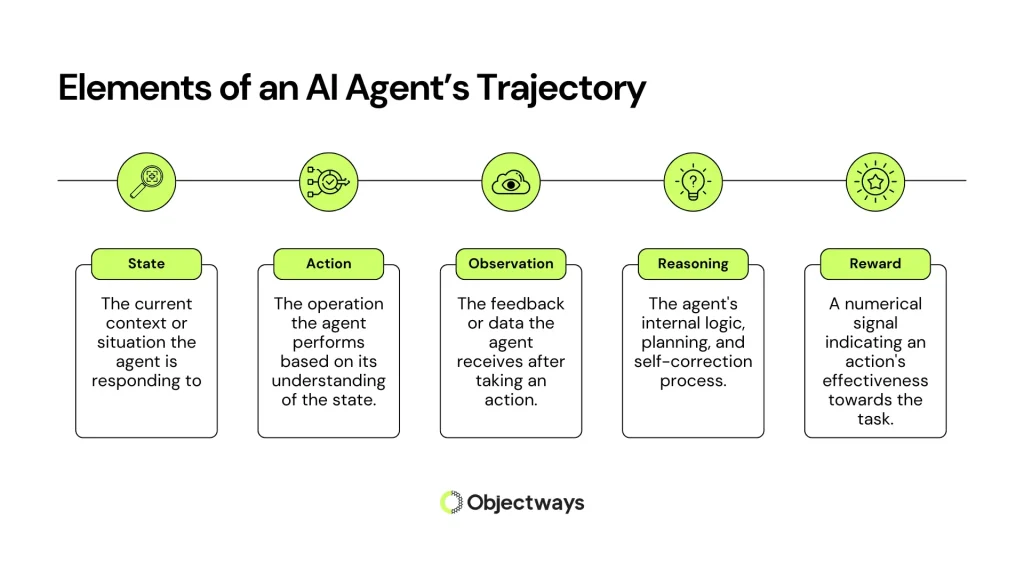
Elements of an AI Agent’s Trajectory
Analyzing how an AI agent thinks and acts throughout a task helps uncover the reason behind the success or failure of its final output. If we can understand where reasoning fails or where tools are not used properly, we can fine-tune or adjust AI models using better examples and targeted feedback.
This step-by-step agent evaluation, from how the agent plans, the tools it uses, and how it reacts to information, gives us a complete picture of its decision-making process.
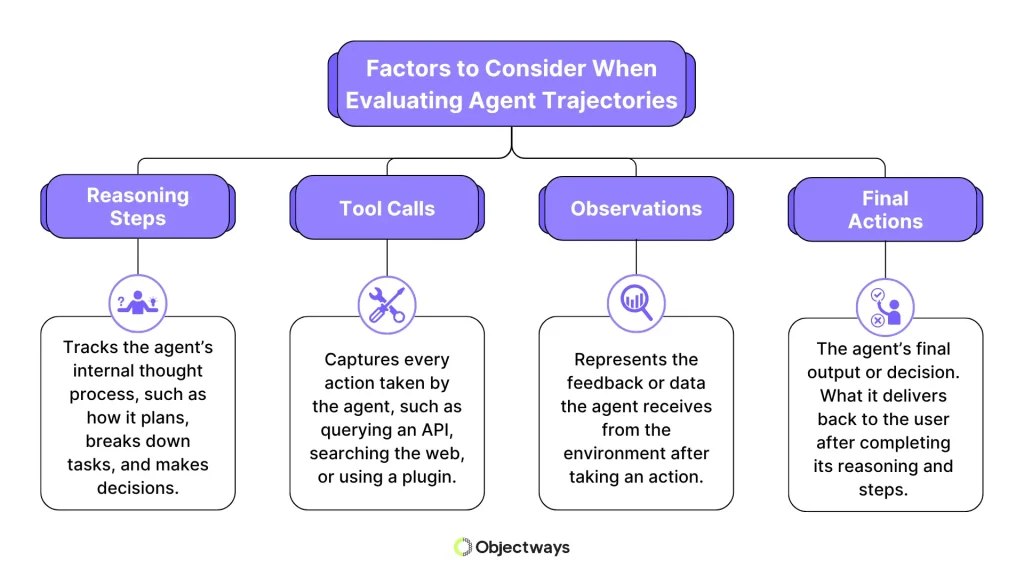
Factors to Consider During Agent Evaluation
To better understand agent evaluation in action, let’s consider a customer support scenario where an AI agent is asked to handle a delivery issue. The prompt given to the AI agent is: “Help the customer John with his delayed order.” Let’s walk through the AI agent’s trajectory step by step.
Reasoning steps are the agent’s initial chain of thoughts or plans that guide the system in deciding what to do with the input.
At the start, the AI agent might think: “Start by finding John’s recent orders. Then, check if the order has been shipped and see where it is currently located. If there’s a delay, figure out the reason and whether a refund is applicable. Finally, write a personalized message for John.” This step helps us see if the agent is thinking clearly or making random guesses.
Then comes the tool calls. These are the external actions an agent takes to get or use information from outside sources.
For instance, after the initial reasoning steps, the agent might check the CRM (customer relationship management) tool to find John’s recent orders. The agent might also request the shipping provider for updates and look up company policies about delays and refunds. This step lets us see if the agent is using the right tools in the right way.
After each tool call, the agent gets feedback or data from the tools it used. Feedback, also known as observations, enables the agent to plan the next course of action.
In John’s case, the data from the CRM might show that his last order was placed five days ago. Similarly, the shipping tool could say it’s delayed due to the weather. The policy database might say, “Orders delayed more than 3 days qualify for a 10% refund.” These pieces of information guide the agent’s next move and help reviewers see if it’s responding accurately to real-world data.
Even though the focus of AI agent evaluation is on the agent’s decision-making steps or trajectory, the final action it takes is still important.
The agent might finally say: “Hi John, your order was delayed due to severe weather. It should arrive in two days. As an apology, we’ve given you a 10% refund.” If more assistance is needed, it could also say: “Would you like me to connect you to a customer support representative?” Looking at this final step, along with the earlier steps, helps us check if the response is accurate, thoughtful, and follows company policy.
To understand how an AI agent works and how to improve it, we can use a mix of human judgment and measurable data. Next, let’s take a closer look at some common AI agent evaluation approaches.
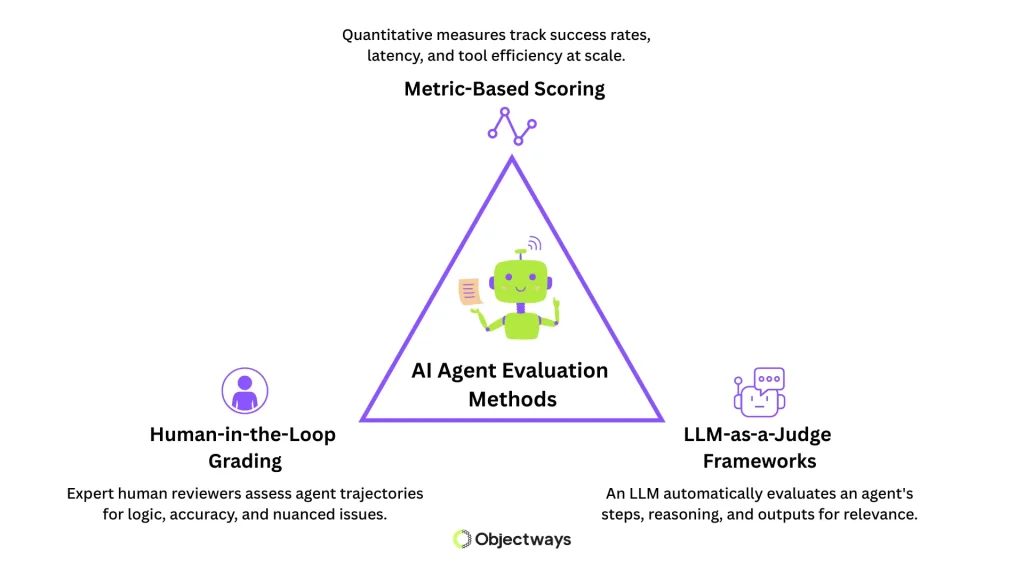
AI Agent Evaluation Methods
Human-in-the-loop grading is one of the most reliable ways to evaluate agents, especially on complex tasks. In this approach, human feedback is built into the evaluation process. People can review the agent’s work, mark important moments, flag errors in reasoning or execution, and give scores using clear rubrics. This method can identify problems like repeated reasoning, missing context, or fabricated information, things that automated tools might miss.
Using large language models (LLMs) to review how other AI agents perform is a growing trend in AI agent evaluation. An LLM can check if the agent used the right tools, made logical decisions, and gave a useful final answer by reviewing the task and each step taken.
While this method is fast and can handle many tasks at the same time, it doesn’t always catch the finer details. For example, an LLM might mark an answer as correct because the final result looks right, while a human reviewer would notice that the reasoning along the way had mistakes.
Another way to measure an AI agent’s performance is through clear, data-driven metrics. Reviewers can look at things like how often the agent’s tool calls succeed, how frequently it hallucinates, how many unnecessary steps it takes, or how long it needs to finish a task. This kind of evaluation is especially important for large-scale AI systems, where speed, consistency, and accuracy matter most.
Now that we have a better understanding of what an agent trajectory is and how to evaluate agents using it, let’s explore some real-world uses of AI agent evaluations.
AI agents often do well on simple, controlled tasks, but they tend to struggle in real-world situations that require planning, reasoning, or the use of external tools. A recent study addressed this issue by training AI agents on full trajectories of step-by-step reasoning and action, rather than just the final expected output. They put together over 50,000 high-quality trajectories across 16 real-world tasks, spanning five key skill areas: reasoning, math, programming, web browsing, and embodied AI.
These trajectories captured the complete, step-by-step thought processes and actions of well-performing AI agents. Using this data, they trained and fine-tuned Meta AI’s open-source model, Llama-2, and developed a new AI agent called SAMOYED.
By learning from detailed agent trajectories instead of just outputs, SAMOYED improved its ability to handle new situations. In fact, it outperformed several existing models in standard benchmark tests. This shows that training AI agents on how to think can make them more reliable in real-world situations.
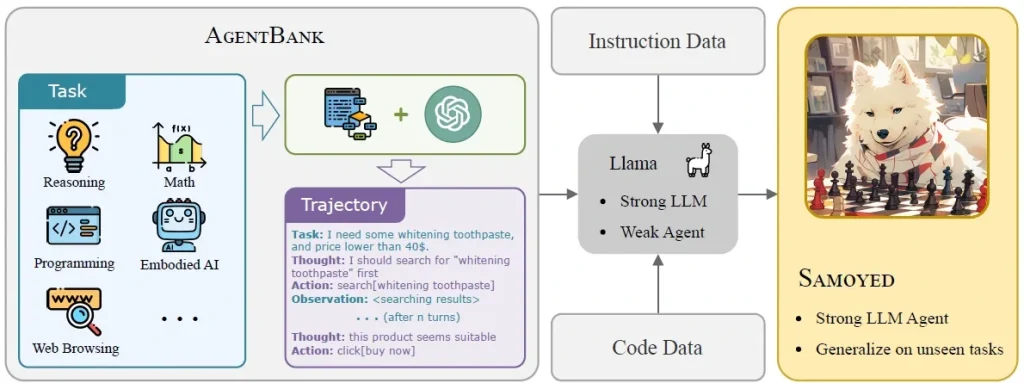
A Look at How the AI Agent, SAMOYED, Was Trained. (Source)
Aircraft are complex machines, and flying them is no easy task, even in a simulator. Whether it’s a human pilot or an automated system, managing speed, fuel, and gravity is essential for executing precise maneuvers like takeoff and landing. To practice such skills, some beginner pilots use flight simulators like Kerbal Space Program (KSP).
A Flight Simulator: Kerbal Space Program (Source: Steam)
In an interesting study, fine-tuned LLM agents were used as autonomous pilots in the KSP simulator. Instead of using reinforcement learning, where an agent learns by trying actions and receiving rewards or penalties based on them, here, real-time flight data was converted into text prompts. This helped the model think in natural language and decide the next course of action.
Each prompt and response formed a trajectory that showed the agent’s decision-making and reasoning process. The team studied these trajectories to find ways to improve its performance.
For instance, when reviewing specific flight paths, they found that incorrect hints within the prompts made the AI pilot miss its target. However, when they used neutral prompts that helped the model’s reasoning, the flight paths became much more accurate.
By identifying and fixing such small issues in the agent trajectories, the team reduced the AI pilot’s reaction delays, enhanced navigation accuracy, and boosted overall performance.
Evaluating how an AI agent thinks, acts, and uses tools is essential to building systems that are trustworthy and aligned with real-world expectations. But doing this at scale isn’t easy. It requires high-quality data, transparent processes, and expert guidance.
Objectways helps businesses to bridge that gap. Our expert reviewers can closely follow the detailed trajectories of AI agents, identify issues in logic or execution, and tag them for deeper analysis and correction. This hands-on approach helps teams track, review, and improve agent behavior through in-depth agent trajectory analysis.
Beyond AI agent evaluation, we also help turn agent trajectories into high-quality training data. This allows technical teams to fine-tune their AI agents using methods such as behavior cloning (training agents to mimic successful examples) or prompt optimization (refining prompts to guide better outputs).
We also design custom AI agent evaluation setups with personalized scoring systems for industries with strict regulations, such as healthcare and finance. Contact us to build or fine-tune AI agents with greater accuracy and control.
New agentic systems, like ChatGPT Agents and AI browsers such as Fellou and Comet, show how AI agents can reason, use tools, and adapt in real time. But the next stage of progress will likely depend on building agents that are explainable, responsible, and aligned with human values.
As these systems take on more complex, multi-step tasks, like planning a trip or summarizing live events, our agent evaluation methods need to evolve alongside them. Trajectory-based evaluation is key, since it lets us look beyond just the final answer to understand how the agent actually reached it – step by step, and whether it made good, ethical AI choices along the way. Still, in sensitive areas where trust really matters, humans will need to stay closely involved to make sure everything is accurate, compliant, and accountable.
As AI agents take on more complex tasks, how we evaluate them becomes crucial. By following how they think, reason, and act at each step, we get a clearer sense of what’s working, where they fall short, and how they can be improved.
This kind of visibility makes it easier to boost performance and build trustworthy agentic systems. Of course, evaluating agent trajectories at scale isn’t simple – it means managing large amounts of data, maintaining consistent label quality, and knowing when to bring in human expertise.
At Objectways, we bring together the right people and proven workflows to help teams track, review, and improve how their AI agents behave, step by step. Reach out today to discuss how we can help with your agent trajectory evaluation workflows.
AI agent evaluation is a process of checking how an AI agent thinks, acts, and makes decisions, not just if its final answer is right. It involves checking its reasoning steps, how it uses tools, and how well it adapts to different situations.


Explore AI data governance and how quality, security, privacy, and availability in training data define the reliability and compliance of next-gen AI systems.

Explore what NVIDIA GTC 2026 revealed about physical AI, the data gap in robotics, and how egocentric data improves real-world performance.
