Most AI projects begin with collecting data, such as images, videos, or sensor readings, but data collection is only the first step. For collected data to be useful, it needs to be organized, labeled, and made readable by machines.
Specifically, for computer vision, a branch of AI that deals with visual data, the process starts with data sourcing and annotation. Data sourcing refers to collecting raw images and videos, while annotation involves labeling those visuals with meaningful tags or markers for model training. This helps computer vision models learn to recognize patterns within images.
Traditionally, annotation has been a manual task. But data annotation can be time-consuming and error-prone. Even the smallest mistakes can cause serious issues in applications like healthcare. Auto-annotation helps address this by using algorithms to generate labels automatically. For example, some computer vision tools can autotag common objects, such as a tree or a car, in images.

Bounding Boxes Generated Through Auto-Annotation. (Source)
Such auto-annotation techniques are making it easier to adopt computer vision applications. For instance, they can detect early signs of crop stress or track livestock health in farms. Similarly, manufacturers can use them to support visual inspection tasks by labeling product defects quickly.
In this article, we explore how a computer vision annotation tool automates labeling, the value it delivers, and why human expertise is still essential. Let’s get started!
Manual annotation is a crucial part of building computer vision models, but it’s also very time-consuming. As AI projects become popular, manually labeling everything slows down the entire process. To speed up the process, annotation tools now come with automation features that help teams label faster without starting from scratch.
One common auto-annotation feature is pre-labeling. It uses AI models to suggest initial annotations like bounding boxes or segmentation masks based on what it’s seen before. These labels give teams an early start, especially when working with large volumes of unlabeled data.
Another helpful tool is autotagging, which applies general labels such as “vehicles” or “retail” to images. They make it easier to group, search, and organize large datasets during the early stages of model development.
Also, some computer vision annotation tools are starting to use models like Grounding SAM that are able to find objects in an image from simple text prompts. For example, typing the word person will highlight all people in the image.
When more precision is needed, these tools can create segmentation masks that outline the entire shape of an object at the pixel level. This is especially useful in fields like medical imaging, where detail is critical, and autonomous driving, where accurate object boundaries are essential for safety.
While such tools can automate many labeling tasks, human labelers are still kept in the loop. This is because some predictions may miss boundaries, blur object edges, or assign the wrong label entirely. So, most workflows include a review stage, where human annotators double-check the results and make corrections as needed.
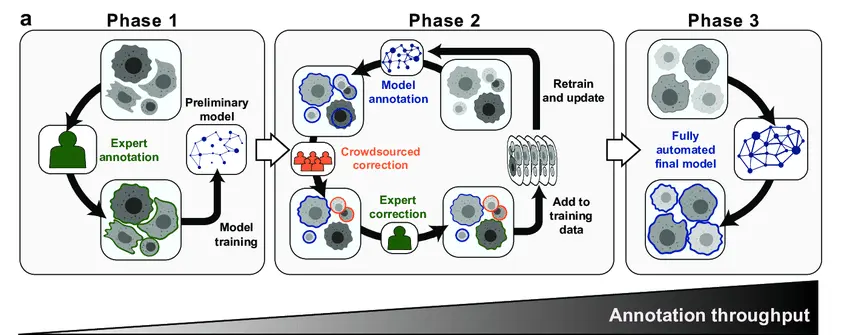
A Workflow That Combines Automated Labeling with Human Annotator Reviews. (Source)
Computer vision annotation tools like TensorAct Studio can ease the burden of manual annotation by introducing automation into data labeling workflows. Here are some advantages that auto-annotation brings to computer vision projects:
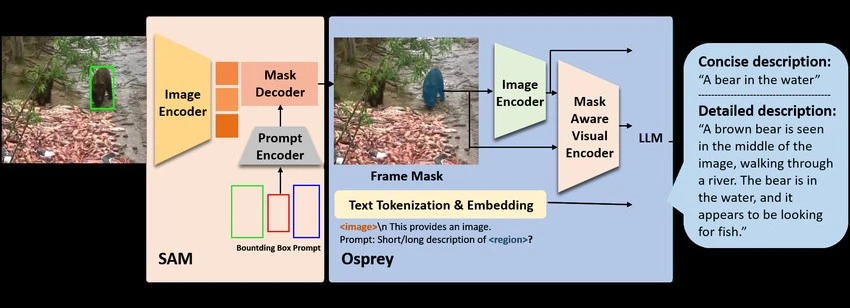
An Example of Auto-Annotation Being Used to Label Data Quickly. (Source)
Now that we’ve covered how auto-annotation works and its benefits, let’s walk through an example of how it supports complex, large-scale mapping tasks in real-world environments.
Autonomous vehicles use high-definition (HD) maps to get details about the environment. These include lane markings, road dividers, intersections, and traffic signs. These HD maps help vehicles understand road conditions and make safe decisions while driving. But creating them takes time, effort, and a lot of manual labeling work.To make this process faster and more scalable, researchers have developed an AI-based system that automates the creation of detailed, city-scale maps for autonomous vehicles. It combines sensor data, deep learning models, and human-in-the-loop workflows to label features like lanes, traffic signs, and road boundaries. This system can process over 30,000 kilometers of road data per day, with more than 90% of the annotations generated automatically.
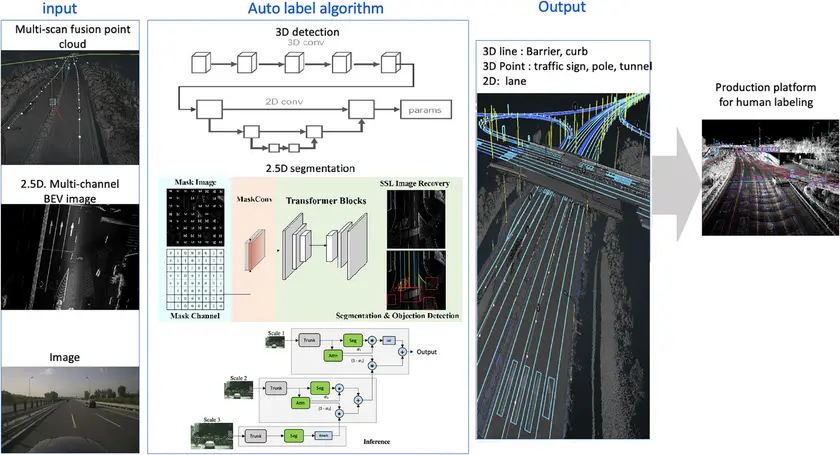
An Auto-Annotation Pipeline Being Used to Generate HD Map Labels. (Source)
While this approach improves both speed and consistency, some areas can still be improved. For instance, the accuracy may drop in unfamiliar settings, especially when road layouts or conditions differ from the training data. Adapting the pipeline for a new city can take additional effort. In addition, capturing high-quality sensor data is resource-intensive, which can slow down large-scale deployment.
While computer vision annotation tools with automation features bring many benefits to the labeling process, they also come with certain limitations. Here are some challenges to consider:
Now that we have a better understanding of how auto-annotation can improve Vision AI projects, let’s look at when to use automated annotation workflows versus human-in-the-loop workflows.
Auto-annotation works well when the data looks similar across images, such as objects placed in the same way or scenes that don’t change much. In these situations, it can label large datasets quickly and reduce the need for manual work.
One interesting example is large-scale image classification. In autonomous driving, for instance, AI systems can automatically label features like lane markings, vehicles, and traffic signs across thousands of video frames.
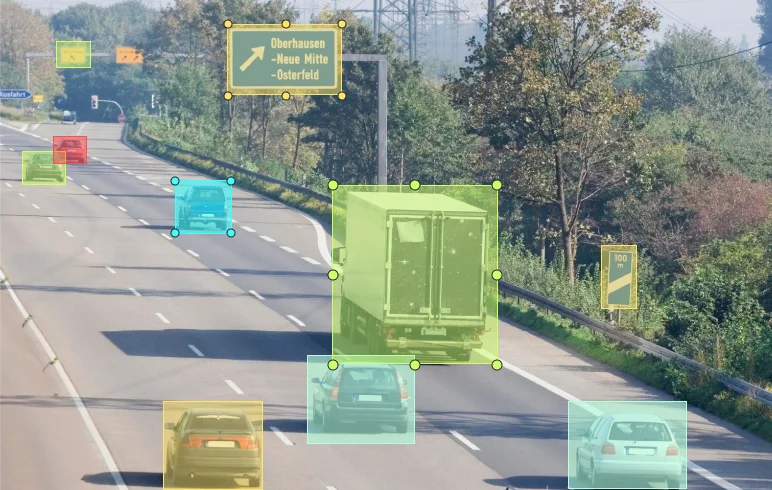
It also performs well in environments with high visual consistency (similar lighting, angles, or scenes). For example, in retail or logistics, products often appear in standard layouts, such as shelves with rows of barcodes or boxed goods. Automated tools can recognize these repeated patterns and generate accurate labels, helping teams save time on routine tasks.

Using AI for Barcode Detection in Retail Settings. (Source)
Automation is great for routine tasks, but only to a certain extent. In some cases, where accuracy or context really matters, a human-in-the-loop approach is still the better option.
For example, in high-risk fields like healthcare, even small labeling errors can lead to serious consequences. Identifying tumors from medical scans requires expert knowledge and precision. Manual annotations are preferred here.
Similarly, in the legal sector, legal or financial documents often contain complex language and layered meaning. Human annotators are better equipped to understand tone, intent, and implications, ensuring accuracy and meeting regulatory standards.
Manual labeling is also necessary when it comes to tasks that involve subjective interpretation. Understanding emotional tone, sarcasm, or cultural references in text or images requires context that AI tools often miss. In these cases, trained annotators can provide the nuance needed to label data correctly and avoid misclassifications.
Creating high-quality training data for computer vision models starts with the right annotation workflow. Techniques like automation can speed up the labeling process, especially for repetitive tasks and for large volumes of data, but it isn’t always perfect. Human expertise is still required to review and refine labels, making sure data meets the accuracy standards required for reliable model training.
Partnering with experienced professionals can make all the difference, and you’re in the right place.
At Objectways, we offer data annotation services across image, video, text, audio, and LiDAR data, backed by trained annotators, robust quality control, and compliance with leading industry standards to ensure accurate, consistent results for AI projects of any size. We also provide AI consulting services to help turn your AI vision into reality.
Auto-annotation is now a key part of any computer vision annotation tool, enabling faster, scalable labeling through features like autotag and segmentation mask generation. With advanced models such as Grounding SAM, these tools offer greater accuracy and flexibility across different datasets.
While automation accelerates routine work, challenging cases like small objects or low-quality images still require human expertise. The most effective workflows combine automation with skilled reviewers to ensure precision, handle edge cases, and apply domain knowledge.
At Objectways, we help teams create smarter annotation workflows by combining AI tools with expert human-in-the-loop oversight. This approach guarantees high-quality data by balancing automation with careful human review.
Reach out to us today to see how we can support your next AI project with reliable, high-quality data.
A computer vision annotation tool is software used to label visual data like images or videos. These tools support features like bounding boxes, segmentation masks, and keypoints. They often include automation features such as pre-labeling, QA checks, and integration with machine learning workflows.

See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.
