Before AI became widely adopted, coaches would spend hours replaying slow-motion footage to study athletes’ movements. Today, those same movements can be analyzed in real time, thanks to computer vision.
Computer vision is a branch of artificial intelligence (AI) that enables machines to interpret the world much like humans do by analyzing images and videos. When it comes to Vision AI, there are many tasks that help systems understand visual information in different ways.
For example, object detection identifies and locates objects in an image, while image classification determines what those objects are. Pose estimation goes a step further by helping machines understand how an object, whether a person, an animal, or even a robotic arm, is positioned and moving in space.In the case of human pose estimation, an AI system identifies key points such as the head, shoulders, elbows, and knees, and connects them to create a digital skeleton. This enables machines to analyze and interpret human movement with remarkable precision, supporting applications in areas like sports training, healthcare, and motion analysis.

Athlete Pose Estimation Using Computer Vision. (Source)
In this article, we’ll explore how pose estimation in computer vision works, the techniques behind it, and where it’s heading next. Let’s get started!
Pose estimation in computer vision is the process of teaching machines to understand how an object is positioned and moves in space. It works by detecting key points on the object and mapping their spatial relationships.
When applied to humans, known as human pose estimation, these key points represent body parts such as the head, shoulders, elbows, and knees. By connecting them, the system creates a digital skeleton that helps computers interpret posture, gestures, and motion.
Pose estimation can be categorized into two main types based on how movement is represented:
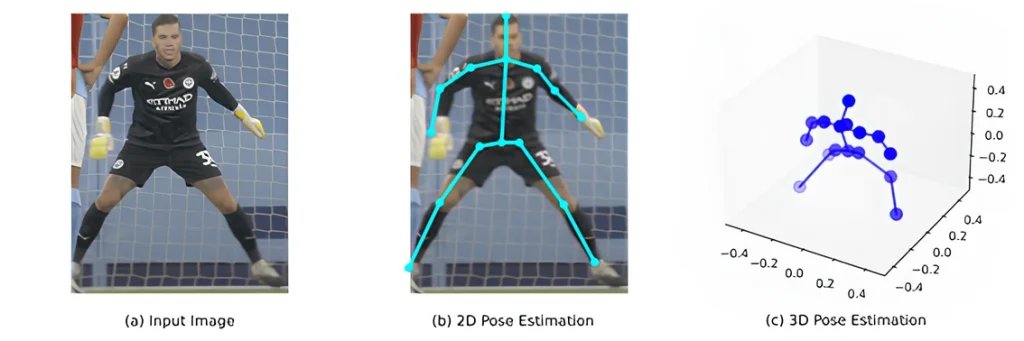
2D Vs 3D Pose Estimation in Computer Vision. (Source)
The difference between 2D and 3D pose estimation is easier to see in action. Consider a basketball player practicing a jump shot; he jumps and releases the ball midair. With 2D pose estimation, the system can trace his arms, legs, and torso to study coordination and timing.
However, 3D pose estimation provides depth. It shows how much the player’s knees bend, how the torso rotates, and whether the overall form looks balanced. Coaches and trainers can use these details to fine-tune the player’s jump technique and identify movements that may cause strain or injury.
Once you understand how 2D and 3D pose estimation work, the next step is deciding which one fits your AI project. The decision depends on how much detail you require, the resources you have, and the type of problem you’re trying to solve.
In many situations, 2D pose estimation is the easier and faster option. It uses less computing power and runs smoothly on most hardware. This makes it a good choice for a wide range of use cases, such as fitness tracking and gesture recognition.
On the other hand, if your project requires more detail, then 3D pose estimation is the better choice. This method captures depth and movement in three dimensions.
It gives a more complete view of posture, angles, and movement patterns, which is beneficial for robotics, safety systems, and detailed motion analysis. However, it often requires more computing power, multiple camera systems, and sensors that can measure depth.
Now that we have a better understanding of what pose estimation is, let’s take a closer look at the key methods that have shaped pose estimation in computer vision.
Early techniques for pose estimation in computer vision worked similarly to solving a puzzle with stick figures. Here, researchers used pictorial structure models that treat each body part as a puzzle piece and try to place them in the right spot based on what they saw in an image.
Over time, this approach improved with probabilistic graphical models, which used probabilities to estimate where each joint was likely to be by considering how nearby parts connect and move together. These early methods proved that machines could read human movement, but they struggled with the challenges of the real world.
For instance, a sideways turn, a crouch, or a hidden arm could confuse the system because these movements alter body shape, hide joints, or cause overlaps that make it harder to identify and link each part correctly.
As classical methods reached their limits in handling complex, real-world movements, researchers turned to deep learning for a more flexible solution. Unlike earlier rule-based models, deep learning–based pose estimation learns directly from data.
By analyzing large collections of images and videos, these systems automatically discover patterns in how joints connect and move, even under challenging conditions like occlusion or poor lighting.
They learn how joints connect, how movement changes with different angles, and how to recognize the body even when the lighting is poor or parts are hidden (occlusion). Such a data-driven approach has improved the accuracy and adaptability of pose estimation.
It allows systems to handle the complexity of real-world movement and track people reliably in everyday environments, not just controlled settings.
When only one person is in an image or video, pose estimation is pretty straightforward. The system follows a single set of joints, connects them into a digital skeleton, and tracks how that person moves.
However, things get complicated when more than one person appears in the same image or video. The AI system now has to do more than just track a single body. It must first detect where each person is, then figure out which joints belong to which body.
Overlapping arms and legs can make this harder because the AI system needs to match every limb to the correct person. Once that’s done, it has to build and track several digital skeletons at the same time. This step is crucial for real-world use, where many people often move, interact, and cross paths.

Multi-Person Pose Estimation in Computer Vision. (Source)
Pose estimation plays an important role in many fields. It helps systems understand human movement with high accuracy and is being used in a wide range of real-world scenarios. Next, let’s walk through some real-world applications of pose estimation and computer vision.
In baseball, even the smallest details can change the outcome of a game. For instance, a fraction of a second in timing or a slight shift in a pitcher’s arm angle can decide whether a pitch is a strike or a miss.
In the past, analyzing these arm movements required expensive motion-capture tools or wearable sensors, which were difficult to use outside controlled environments. However, pose estimation and computer vision offer a reliable and less invasive solution.
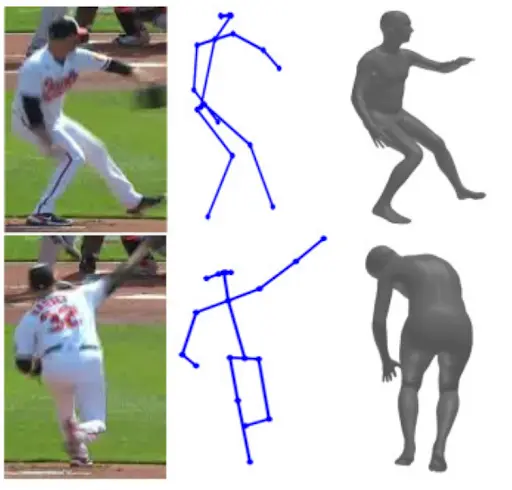
Using Pose Estimation in Baseball Analytics. (Source)
For example, recent research has introduced PitcherNet, a system that uses pose estimation on regular broadcast footage. It identifies the pitcher, reconstructs their body in 3D, and calculates details such as pitch velocity, release point, and delivery style, all from the same video viewers watch at home. This provides practical insights for coaches to improve team performance, and also gives data-driven analysis for fans at home, making the game a bit more exciting than it already was.
Doctors and physicians can closely monitor patients recovering in a hospital after an injury or surgery. Yet the recovery journey often continues once they’re home. Tracking that progress outside the clinic is now possible thanks to advances in pose estimation and computer vision.
For example, research shows that OpenPose, a widely used pose estimation model, can reliably measure the range of motion of the knee after total knee arthroplasty. It delivers accuracy comparable to radiography.

Leveraging Posture Detection for Physical Rehabilitation. (Source)
OpenPose works by detecting key body points through a regular camera and mapping them into a digital skeleton. This allows it to analyze movement and posture precisely enough to support at-home rehabilitation.
When it comes to interactive technology, pose estimation and computer vision can track the human body in detail and turn movement into input commands for a computer system. It works by identifying key points on the hands, arms, and body, then connecting them into a digital skeleton. You can easily manipulate a cursor or a character in a computer game by simply moving your own limbs.
A Virtual Avatar Created Through Posture Detection. (Source)
A good example is Meta’s Oculus Quest headset. It tracks 21 key points on each hand, allowing users to pinch, point, or grab objects in virtual reality space without holding a controller.
This creates a natural and responsive experience that feels closer to real interaction. The same approach can also power touch-free controls in workplaces, improve accessibility for people with mobility challenges, and build learning tools that respond directly to how a person moves.
Here are some common challenges and limitations of pose estimation:
Overcoming these challenges starts with having better data. Models perform best when they’re trained on high-quality, diverse, and well-annotated datasets that reflect real-world conditions.
That’s where Objectways can help; we provide the image data and annotation expertise teams need to build computer vision and pose estimation systems that are accurate, reliable, and ready for real-world use.
Pose estimation is moving from the lab to the real world, becoming a key part of how machines understand human movement. With the global market for vision-based technologies projected to grow from $17.8 billion in 2024 to $58.3 billion by 2032, pose estimation is on track to become a core part of future AI systems.
One major step forward is combining video data analysis with extra inputs from devices like depth sensors, motion detectors, and wearable devices. This gives systems a clearer view of how the body moves, even in low light or when parts of the body are hidden from the camera.
Generative AI is also changing how pose estimation models are trained. Instead of manually collecting every example, researchers can now create new synthetic data that shows rare or unusual body posture movements, like emergency gestures. This speeds up training, reduces cost, and helps models handle a wider variety of real-world situations.
A newer approach called cooperative inference is gaining attention, too. It enables several devices in a network to share the work of processing movement data. This makes real-time 3D pose estimation possible on smaller devices such as smartphones and wearables without relying on powerful hardware.
Pose estimation has evolved from simple stick figures to advanced systems that track human movement in real time, powering innovations in robotics, healthcare, retail, and safety. Reliable results depend not just on strong models but on diverse, high-quality data that bridges the gap between research and real-world applications.
Are you looking to build pose estimation systems that perform well in real-world conditions? You’ve come to the right place. At Objectways, we deliver high-quality image data and expert annotations that help AI teams train more accurate, adaptable models. Reach out to learn how we can support your next AI project.


Learn how computer vision for quality inspection helps detect defects, improve product accuracy, and maintain quality control in production lines.

Learn how computer vision in transportation enhances safety, efficiency, and sustainability through real-time traffic insights and smart mobility systems.
