Deep learning has been very successful when working with images as data and is currently at a stage where it works better than humans on multiple use-cases. The most important problems that humans have been interested in solving with computer vision are image classification, object detection and segmentation in the increasing order of their difficulty.
While there In the plain old task of image classification we are just interested in getting the labels of all the objects that are present in an image. In object detection we come further and try to know along with what all objects that are present in an image, the location at which the objects are present with the help of bounding boxes. Image segmentation takes it to a new level by trying to find out accurately the exact boundary of the objects in the image.
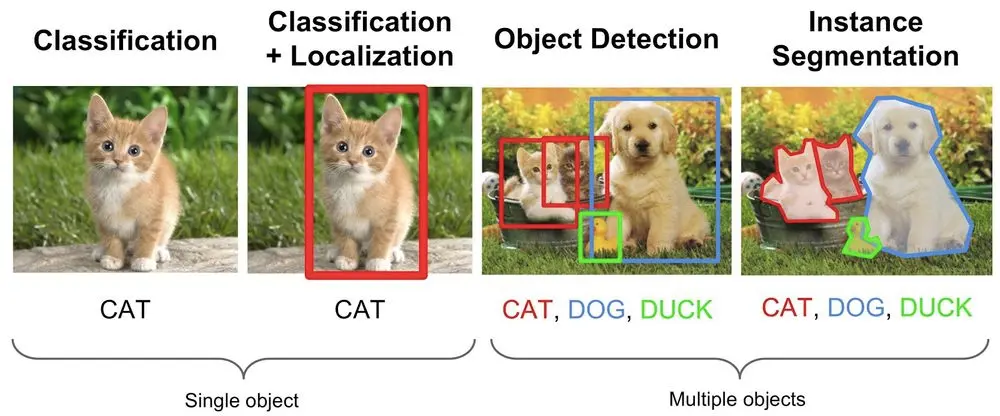
We know an image is nothing but a collection of pixels. Image segmentation is the process of classifying each pixel in an image belonging to a certain class and hence can be thought of as a classification problem per pixel. There are two types of segmentation techniques

There are numerous advances in Segmentation algorithms and open source datasets. But to solve a particular problem in your domain, you will still need human labeled images or human based verification. In this article, we will go through some of the nuances in segmentation task labeling and how human based workforce can work in tandem with machine learning based approaches.
To train your machine learning model, you need high quality labels. For a successful data labeling project for segmentation depends on three key ingredients.
There are many open source and commercially available tools on the market. At objectways, we train our workforce using Open CVAT that provides a polygon tool with interpolation and assistive tooling that gives 4x better speed at labeling and then we use a tool that fits the use case.
Here are the leading tools that we recommend for labeling. For efficient labeling, prefer a tool that allows pre-labeling and assistive labeling using techniques like Deep Extreme Cut or Grab cut and good review capabilities such as per label opacity controls.
While it is easier to train a resource to perform simple image tasks such as classification or bounding boxes, segmentation tasks require more training as it involves multiple mechanisms to optimize time, increase efficiency and reduce worker fatigue. Here are some simple training techniques
In Machine Learning, there are different techniques to understand and evaluate the results of a model.
Pixel accuracy: Pixel accuracy is the most basic metric which can be used to validate the results. Accuracy is obtained by taking the ratio of correctly classified pixels w.r.t total pixels.
Intersection over Union: IOU is defined as the ratio of intersection of ground truth and predicted segmentation outputs over their union. If we are calculating for multiple classes, the IOU of each class is calculated and their mean is taken. It is a better metric compared to pixel accuracy as if every pixel is given as background in a 2 class input the IOU value is (90/100+0/100)/2 i.e 45% IOU which gives a better representation as compared to 90% accuracy.
F1 Score: The metric popularly used in classification F1 Score can be used for segmentation tasks as well to deal with class imbalance.
If you have a labeled dataset, you can introduce a golden set in the labeling pipeline and use one of the scores to compare labels against your own ground truth. We focus on following aspects to improve quality of labeling
We have discussed best practices to manage complex large scale segmentation projects and provided guidance for tooling, workforce upskilling and quality management. Please contact sales@objectways.com to provide feedback or have any questions.


Learn how computer vision for quality inspection helps detect defects, improve product accuracy, and maintain quality control in production lines.

Learn how computer vision in transportation enhances safety, efficiency, and sustainability through real-time traffic insights and smart mobility systems.
