Choosing a data labeling tool for your AI project is a lot like picking the right equipment for a construction job. You wouldn’t rely on light-duty tools to construct a high-rise building, nor would you bring in industrial machinery for a small home project. Having the right tools makes all the difference.
Similarly, every successful AI model starts with high-quality, accurately labeled data. Data labeling involves tagging raw data so machine learning algorithms can understand it. It lays the groundwork for how innovative, accurate, and reliable your model will be. When data quality falls short, the impact is pretty serious. In fact, studies show that companies can lose up to $12.9 million due to poor data quality.
That’s why choosing the right data labeling tool matters. Organizations often face a tough decision between using flexible, cost-effective open-source tools or investing in proprietary platforms that offer built-in support, scalability, and automation.
Determining the right option can lead to better results and faster innovation. On the other hand, the wrong choice, though, can slow things down and make things more expensive. In this article, we’ll explore the key differences between open-source and proprietary data labeling tools, share real-world examples, and highlight key factors to help you choose the right solution for your project.
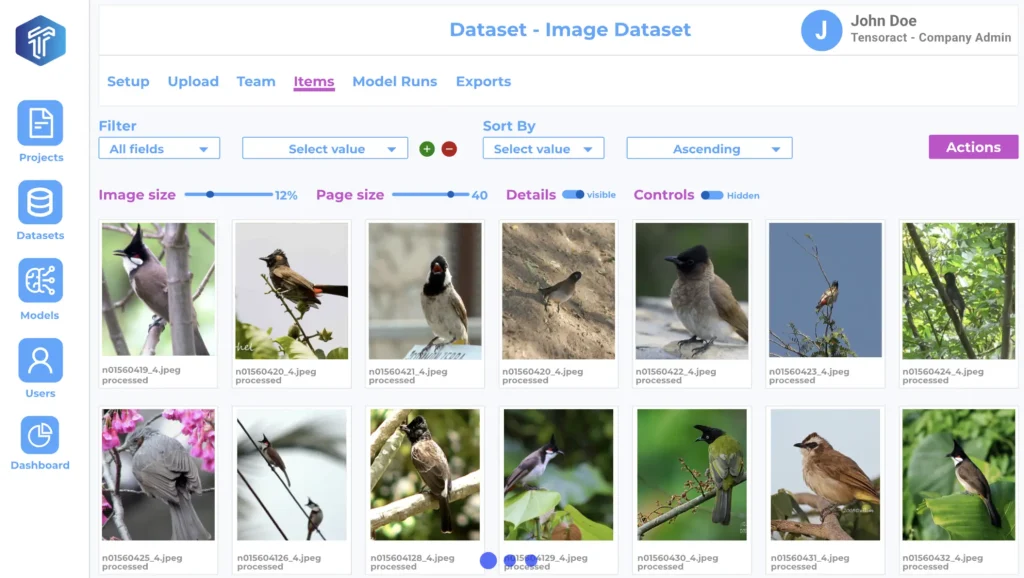
A Glimpse of a Data Labeling Tool. (Source)
Many of these tools use a human-in-the-loop approach, combining automation with human reviews to ensure accuracy. This teamwork helps create high-quality training datasets – the foundation for AI innovations like computer vision models, large language models, and generative AI models.
Data labeling tools are primarily classified into two key categories. Here’s a closer look at each of them:
When you compare open-source and proprietary data labeling platforms, it’s clear that both have their own unique advantages. Open-source tools give you more flexibility and control, but they usually need more technical skills to set up and maintain. Proprietary platforms are easier to use and come with built-in features like automation and support, but they’re less customizable.
As shown in the table below, the best choice depends on what your team needs. That’s why many organizations end up looking for a mix of both.

Differences Between Open-Source and Proprietary Data Labeling Tools
Now that we have a better understanding of what an open-source data labeling tool is, let’s explore some real-world examples where using open-source tools can provide the most value.
Not all AI projects require massive datasets or large teams. In academic or personal projects, especially those using transfer learning and pre-trained models, the amount of annotated data needed can be considerably smaller.
For example, a student working on an object detection task might only need to annotate around 300 images. In these simpler use cases, it makes more sense to use lightweight, open-source tools that are easy to set up and free to use.
Tools like LabelStudio and MakeSense are ideal for this. They support essential annotation types like bounding boxes and polygons, offer user-friendly interfaces, and don’t require heavy technical infrastructure – making them perfect for small-scale projects with limited resources.
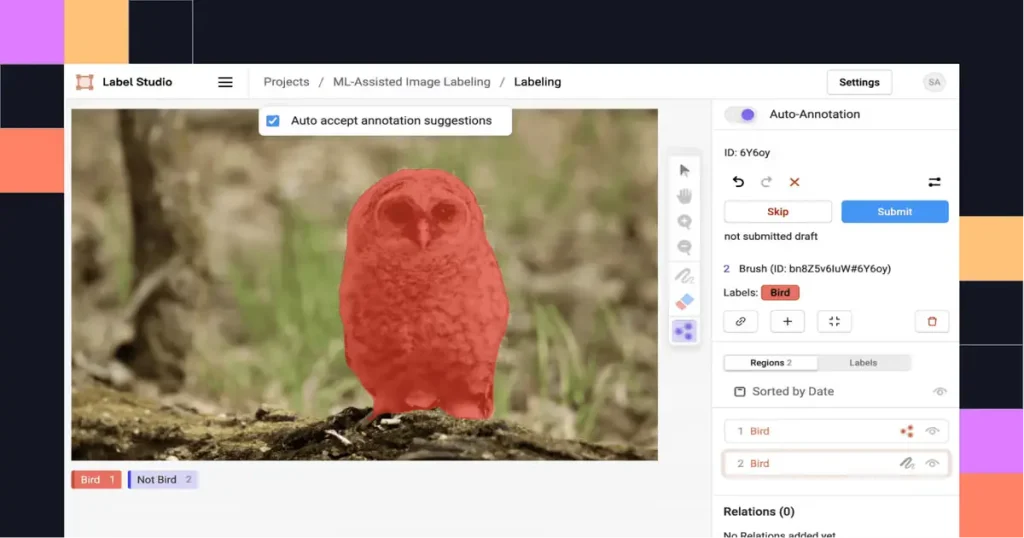
A Look at LabelStudio (Source)
Early-stage startups often operate with small teams and limited budgets. Their main goal is speed – getting prototypes up and running without added complexity. At this point, datasets are typically small or highly specific, like a few hundred user queries. The perfect data labeling tool should be easy to set up, help teams iterate quickly, and keep the focus on validating ideas.
For instance, a startup developing an AI-powered customer support chatbot might need to annotate text data to detect user intent, extract key information, or flag urgent messages. Open-source tools like Doccano and LightTag handle these tasks well.
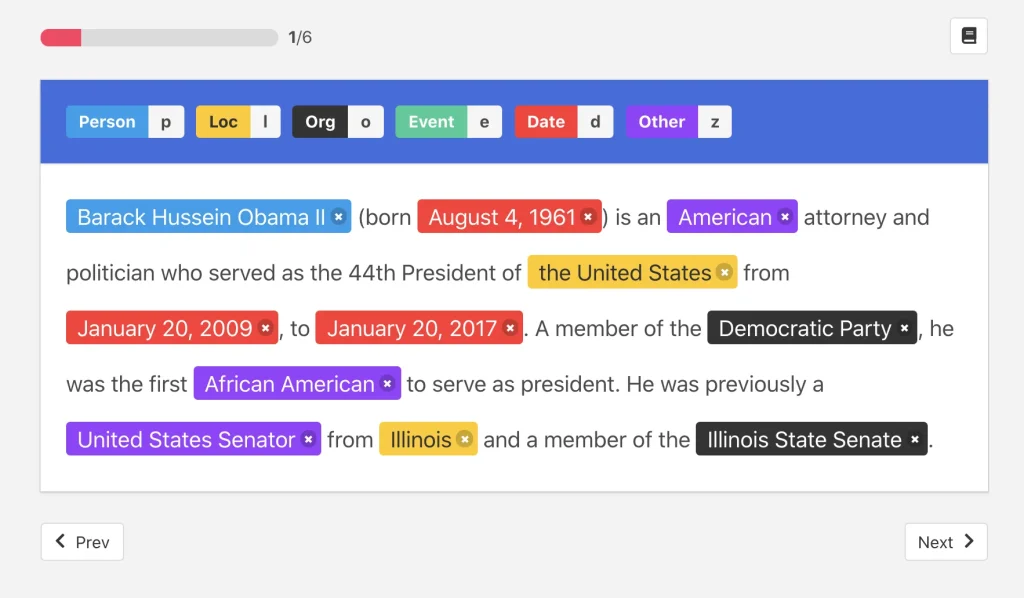
An example of using Doccano for text annotations. (Source)
Academic projects and prototypes usually deal with smaller datasets and focus on learning or experimentation. But real-world, production-grade AI projects need to handle larger volumes of data and deliver reliable, efficient results.
Next, let’s look at a couple of examples where proprietary data labeling platforms might be the better choice.
Healthcare projects that use AI often require high precision. Let’s say a company is developing a model to detect skin lesions. They might be working with thousands of high-resolution images, where even the smallest details, like asymmetry, slight color changes, or irregular borders, can be crucial.
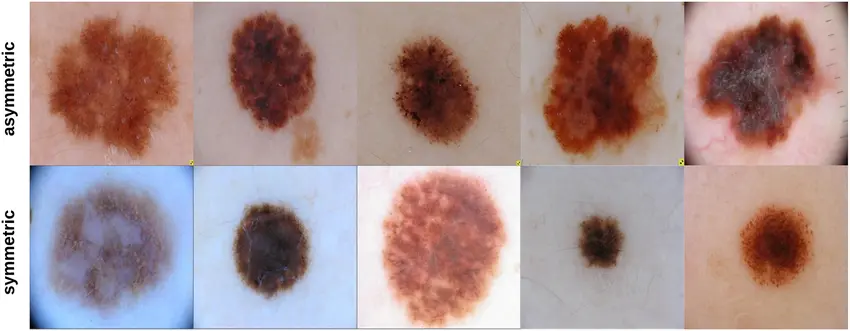
An example of data labeled for dermatology-related applications. (Source)
In this case, they need an annotation tool that can handle both the scale and sensitivity of the project. On top of that, regulations like HIPAA add strict requirements for data privacy and security.
This is where a platform like TensorAct Studio is especially useful. It supports detailed image annotation for tasks like classification and segmentation, along with secure data handling and customizable workflows.
With AI-assisted labeling, version control, and built-in quality checks, teams can manage complex tasks efficiently – without compromising on accuracy or data compliance. Whether in healthcare or any other industry where precision and security matter, TensorAct Studio provides the control and flexibility needed to deliver reliable, high-quality results.
Another area where a proprietary tool like TensorAct Studio proves reliable is e-commerce. Online retail platforms manage millions of product images that must be accurately labeled and continuously updated. This goes far beyond basic tagging – it demands fast, high-precision annotation at scale.
During peak times like seasonal launches or sales events, companies may need to classify tens of thousands of images by attributes such as color, category, material, and brand – often within just a few days. Errors or delays in labeling can disrupt product search, weaken recommendations, and impact sales.
TensorAct Studio is built to handle this level of demand. When accurate product data directly affects customer experience, a dependable proprietary platform delivers the speed, precision, and integration needed to keep everything running smoothly.
So far, we’ve discussed scenarios that involve image or text annotation, but some AI projects rely on more complex data types, like LiDAR. LiDAR (Light Detection and Ranging) uses laser pulses to create detailed 3D maps of the environment. It’s a key technology in autonomous vehicles, helping them detect objects, measure distances, and understand their surroundings with high precision.
Annotating LiDAR data, especially in the form of 3D point clouds, is far more complex than labeling images or text. Generally, developers working on Level 4 autonomous vehicles must label millions of data points to identify features like lane markings, curbs, moving vehicles, and pedestrians, all in 3D space and often aligned with camera footage.

Annotating LiDAR data to train models for deployment in self-driving cars. (Source)
This level of detail is difficult to manage with open-source tools. Proprietary platforms like TensorAct Studio offer the advanced capabilities needed for these tasks – such as 3D annotation tools, sensor fusion, machine learning integration, and version-controlled workflows. For safety-critical applications like autonomous driving, proprietary tools deliver the accuracy, scalability, and control required to build reliable systems.
If your AI project doesn’t fit within the scenarios we’ve walked through so far, a hybrid data labeling approach might be the right fit. This means using both open-source and proprietary tools – switching between them as your project evolves, like a hybrid car switching between electric and gas.
Open-source tools might work well in the early stages. They’re flexible, cost-effective, and great for experimenting or handling large datasets when things are still taking shape.
But as your project moves toward production, the project’s needs can change. You may need faster, more accurate labeling that meets strict quality and industry standards. That’s where proprietary tools can be brought in.
Here are some other key factors to consider when choosing a data labeling tool:
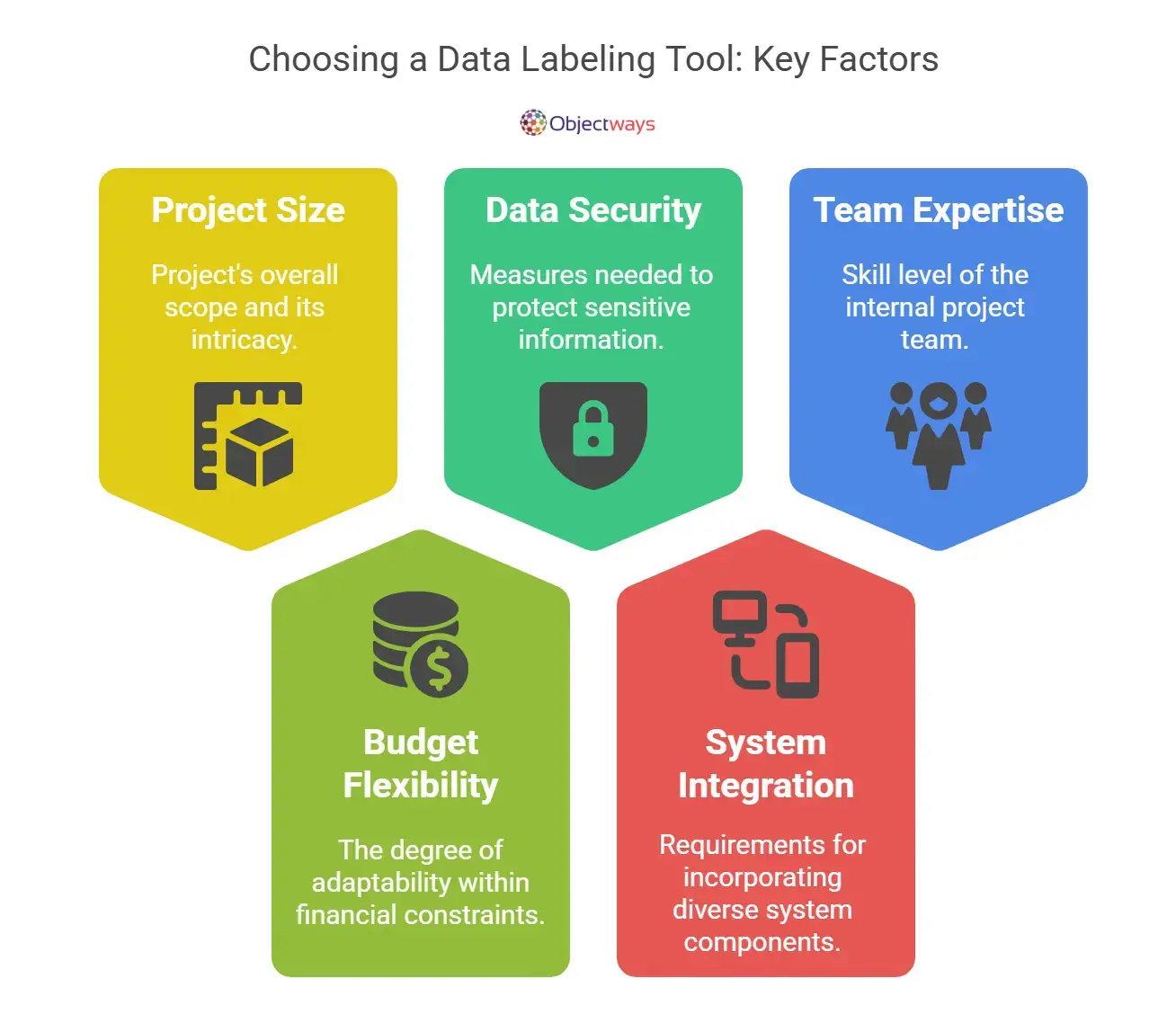
Key Considerations to Make When Selecting a Data Labeling Solution.
Choosing between open-source, proprietary, or hybrid data labeling solutions isn’t a one-size-fits-all decision. It’s a lot like picking the right climbing gear – the gear that works for one terrain might not suit another. Some projects demand complete control and flexibility. Others need speed, built-in support, and structured workflows.
Ultimately, the right solution shapes your AI pipeline’s quality, consistency, and long-term reliability. It’s not just about data labeling; it’s about building trust in your AI solution.
At Objectways, we help teams make these decisions with clarity. Whether starting from scratch or refining a complex deployment, we support your goals with accurate data labeling services and adaptable AI solutions.
Have a vision for your perfect AI solution? Contact us today!

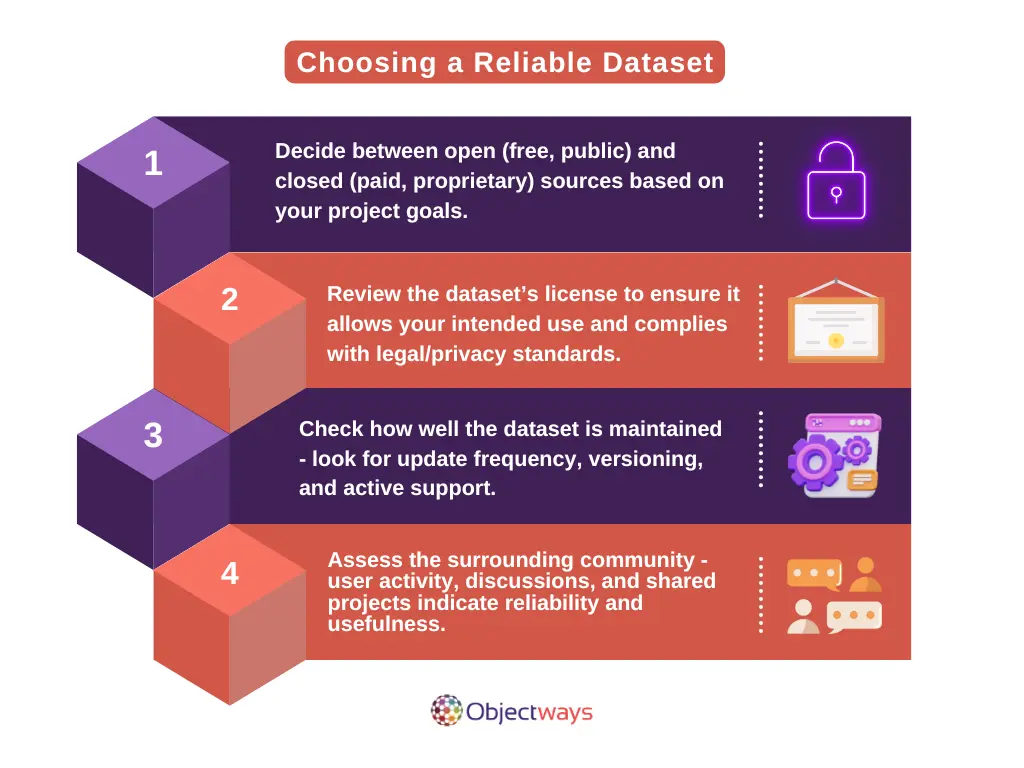
Choosing the right dataset is one of the most important steps in building an object detection model that performs well. Just like you need a...
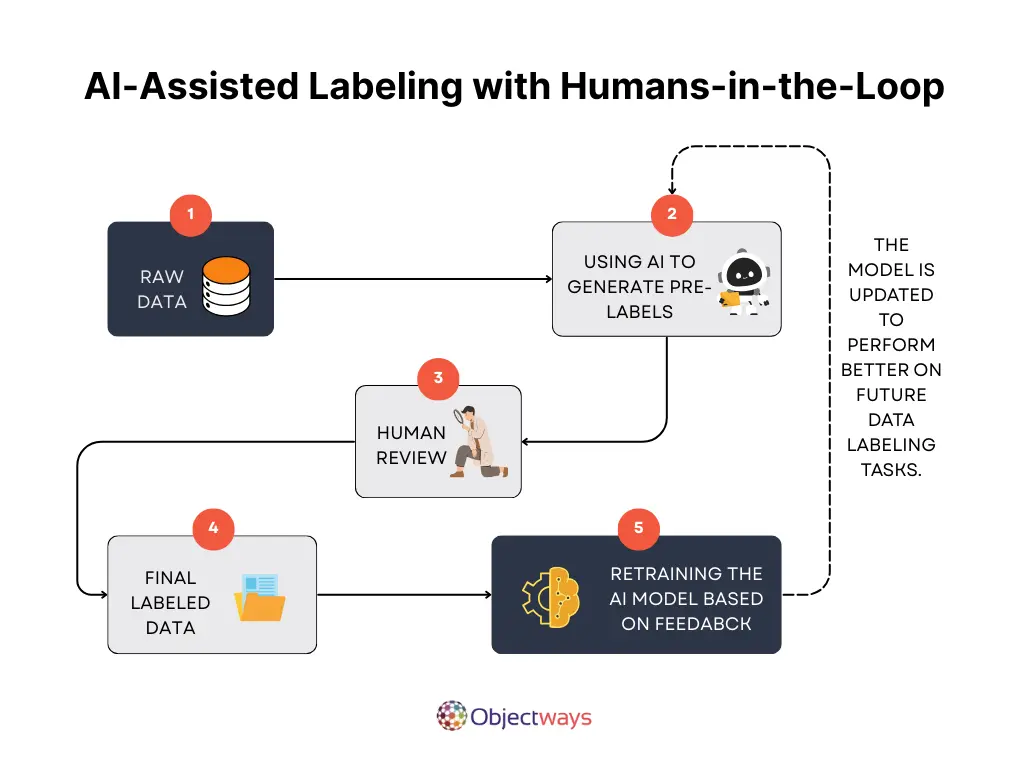
One of the most important parts of any AI project, that often gets overlooked, is preparing the data needed to train a model. This process...
