Despite the benefits that artificial intelligence (AI) solutions offer, it’s an unfortunate fact that 85% of AI projects fail. One of the main reasons for this is poor data quality. When the data used to train AI models is incomplete, irrelevant, or biased, it leads to inaccurate predictions and failures. High-quality data labeling plays an important role here – it helps make sure that data is tagged properly, so AI models can understand and learn from it correctly. It’s a classic case of “garbage in, garbage out” – if the data you feed an AI system isn’t good, the results won’t be either.
You can think of data as the foundation of AI. Just like a house won’t stand strong without a solid base, AI systems can’t perform well without reliable, high-quality data. No matter how advanced an AI algorithm is, it can’t do its job if it doesn’t have the right information to work with. In fact, this is true for all types of data – whether it’s text, images, audio, or video. If the data is messy, poorly labeled, or incomplete, the AI model won’t be able to learn correctly and will output unreliable results.
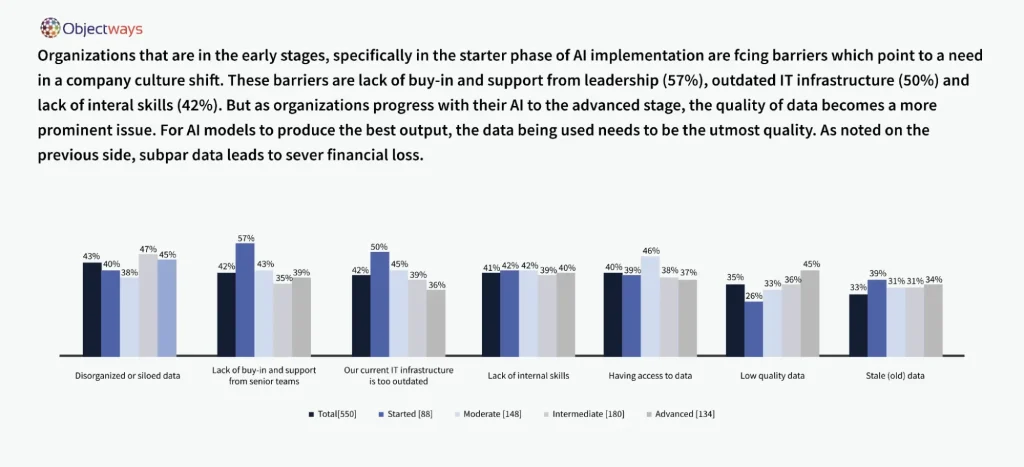
An infographic showing the growing importance of data quality. (Source)
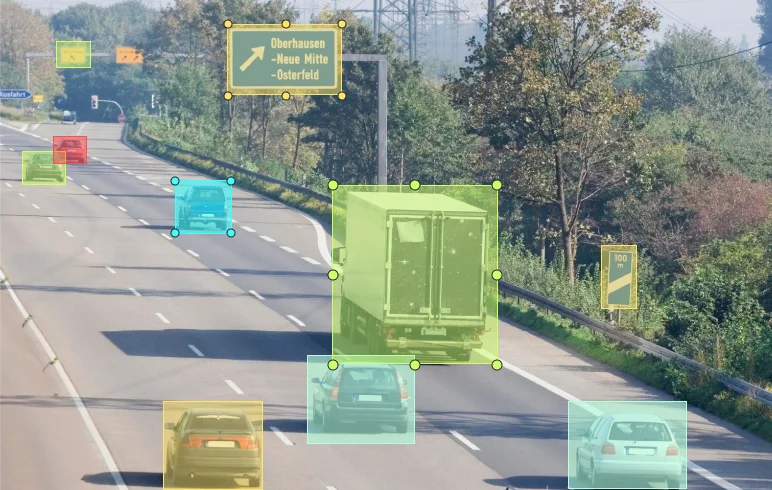
Different branches of AI, like natural language processing (NLP), computer vision, and generative AI, rely on specific types of data. For instance, NLP models need well-labeled text data to understand language nuances, such as sentiment, syntax, and context. Similarly, computer vision systems rely on diverse and precise image annotations, as well as specialized data types like LiDAR 3D point cloud annotations for applications such as autonomous driving and spatial mapping. If these datasets aren’t of the highest standard, even the best AI models will struggle to perform.
Regardless of the field – whether it’s autonomous vehicles or healthcare – data integrity and high-quality data are the secret ingredients that fuel the success of AI applications with real-world impacts.
Every human being is unique and skilled at different things; many of these traits are based on one’s genetic makeup or DNA. Similarly, every AI system has its own genetic code or the data it learns from. Just like DNA determines how we grow and evolve, data is the blueprint that shapes an AI model’s ability to learn, adapt, and make decisions. The process of learning from data helps AI models to identify patterns. You could compare it to how our genetic code directs the development of our abilities and characteristics.
Data quality and integrity are the core of this learning process. If our DNA is damaged or flawed, it affects our growth. In the same way, if the data an AI model is trained on is inconsistent, incomplete, or unreliable, the system’s decisions will be inaccurate.
For example, research has shown that smaller, high-quality datasets can often work better than large, unorganized ones. As shown below, a language model trained on just 30% of a dataset performed just as well, and in some cases better, than one trained on the full dataset. So why does this matter? It’s all about using better data. High-quality datasets help models learn more effectively, which means faster training, lower costs, and less effort, all while still achieving great results.
As a matter of fact, model training time is usually tied to the size of the dataset, so using just 30% of the data could reduce training time by as much as 70%. Let’s assume training on the full dataset takes 10 hours, the smaller dataset might only take 3 hours. This showcases how smaller, high-quality datasets can save time and resources.
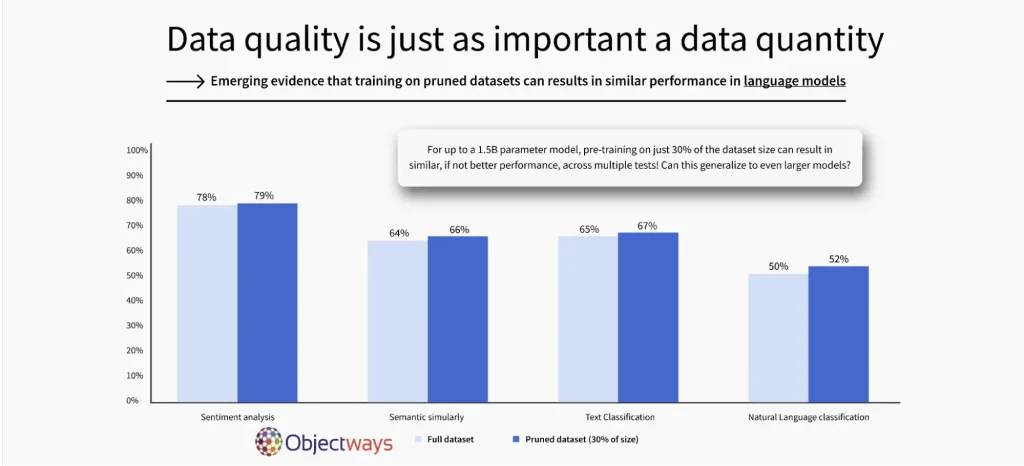
High-quality data drives AI success, even with smaller datasets. (Source)
To put it simply: High-quality data is what lets AI thrive. Just as our bodies need healthy genes for optimal functioning, AI requires data that is accurate, consistent, and representative.
Diversity in data, much like genetic diversity, is also vital. Different genetic traits make it possible for humans to adapt to various environments. Meanwhile, diverse datasets enable AI models to perform well in different contexts. Whether it’s recognizing objects in various lighting conditions or understanding multiple languages, diverse and well-labeled data gives AI solutions the adaptability they need to succeed. Ultimately, like DNA defining our unique characteristics, data quality determines the performance and success of AI models.
When AI systems are fed bad data, the results can be more than just inaccurate. They can also damage trust, making people hesitant to rely on AI systems.
A well-known example is from 2015 when Google Photos mistakenly labeled pictures of a Black couple as “gorillas.” The AI model categorizing pictures wasn’t trained with enough diverse data to accurately recognize people of all skin tones. Think of it like teaching a child to recognize fruits but only showing them round ones like apples and oranges. When they see a pineapple, they might not recognize it as a fruit at all. It’s the same with the AI model – it didn’t have enough varied examples in its training, leading to errors. That’s exactly why diverse and representative data is so important for AI models to function correctly.
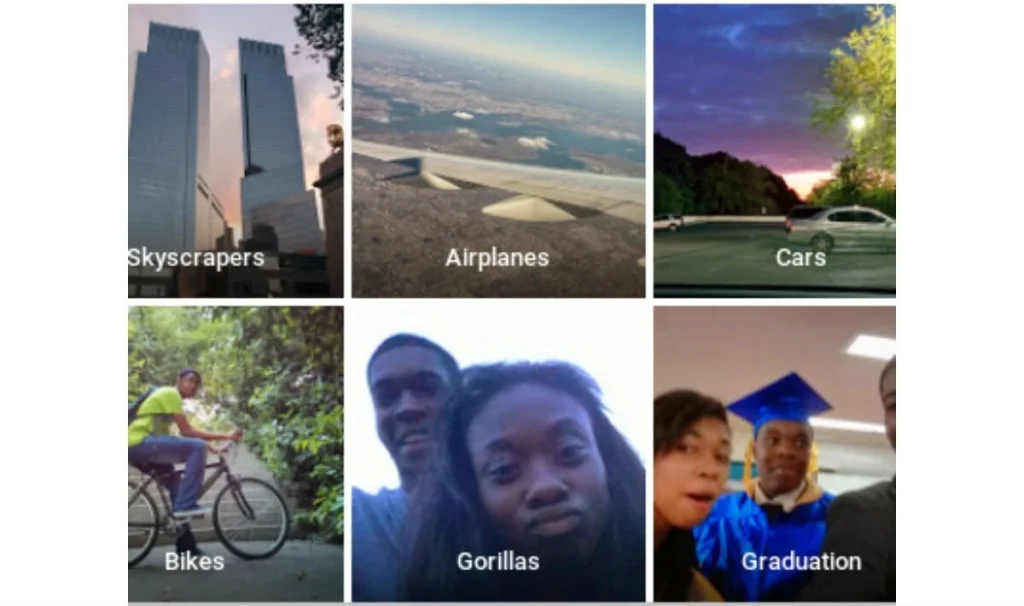
Poor data quality can impact image recognition systems. (Source)
Going beyond image analysis, this issue with poor-quality data crops up in relation to many other AI applications as well. Think about self-driving cars that can’t recognize a child crossing the street because their training data didn’t include enough scenarios with diverse environments or lighting conditions. Or chatbots that repeat biased or inappropriate phrases because they were trained on text filled with stereotypes. These examples represent more than technical hiccups; they can have real-world consequences that affect safety, trust, and fairness.
So, what is the solution? AI models need to be trained on diverse, representative data and rigorously tested in real-world scenarios. High-quality data is the gateway to fairer, more reliable systems that can avoid harmful mistakes and earn trust.
Now that we’ve discussed the importance of high-quality data, let’s step back and discuss why data needs to be labeled and the types involved.
A great way to visualize this is to think of a teacher in a classroom. Before expecting students to solve math problems, a teacher would first explain the concepts and show examples of equations. The students learn by seeing those examples. Similarly, most AI models need labeled data as examples to learn and understand how to perform tasks.
Here are some examples of different types of data that can be labeled:

An example of LiDAR data used in autonomous vehicles to map and detect objects.
Next, let’s walk through how these data types can be used in real-world applications and why high-quality data is the DNA of AI. A popular application of AI in healthcare involves AI models being trained on meticulously labeled medical scans, such as X-rays or MRIs, to detect diseases like cancer or identify abnormalities. The precision of these labels directly impacts diagnostic accuracy. High-quality data can indirectly improve patient outcomes.
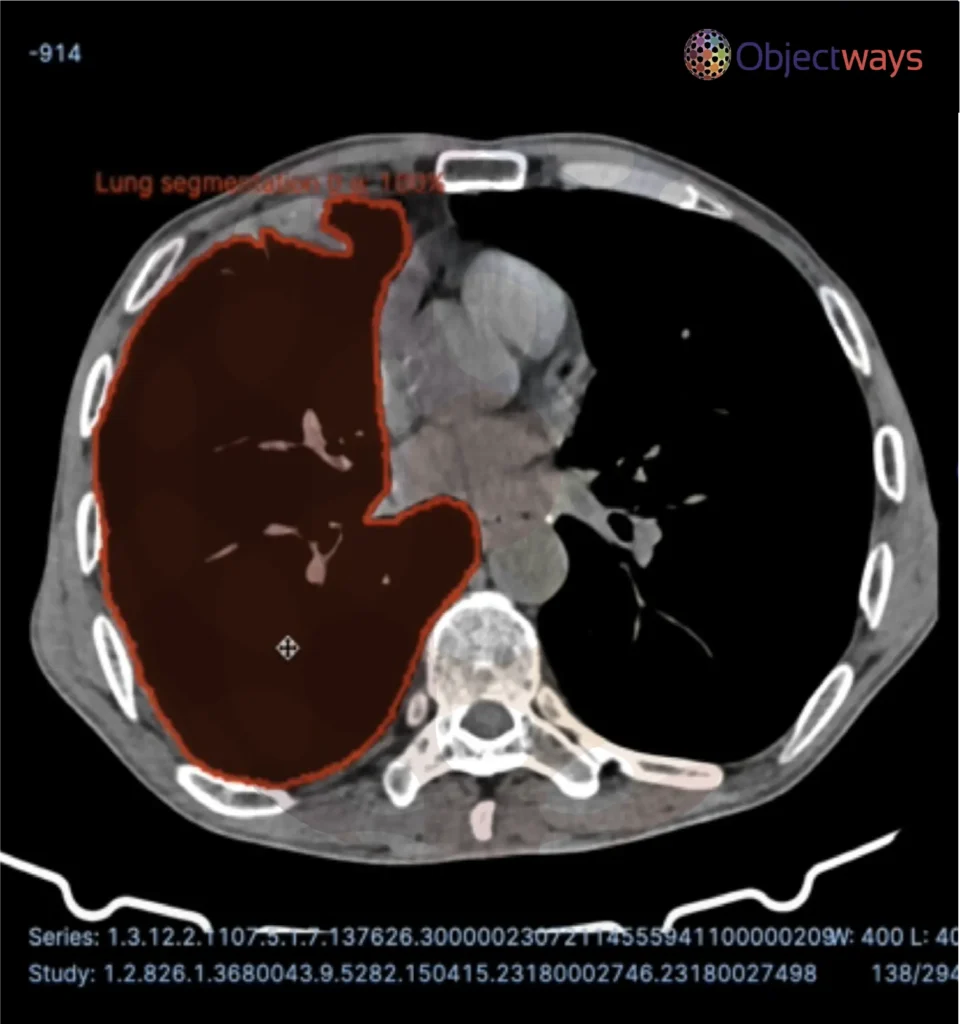
Using AI to detect brain tumors.
Jumping to an industry with a different focus, retail, the precision of high-quality data is still relevant. AI-driven recommendation systems rely on structured customer data, such as browsing history and past purchases, to provide personalized shopping suggestions. Accurate and well-prepared data can help make sure that these systems understand customer preferences and deliver meaningful recommendations to boost customer satisfaction and drive sales.
These are just two examples where high-quality data is the key to building AI systems that are reliable, efficient, and impactful. The same principle applies across many AI applications in various industries, from finance to transportation.
Sourcing the right data for AI systems is often easier said than done. Especially when you are dealing with domain-specific needs, it can be like finding a needle in a haystack.
Let’s say you are building a speech recognition system that requires diverse audio datasets from various languages, accents, and environmental conditions. Collecting such an array of audio data can be time-consuming and logistically challenging.
The same can be said for medical imaging – it demands high-quality, specialized datasets often involving rare or sensitive cases. Collecting this data requires navigating strict privacy laws and ethical guidelines, even more complex hurdles. Similarly, video analytics models need data from a wide range of real-world scenarios, including different lighting, weather, and environments, and it can be difficult to gather.
On top of these challenges, guaranteeing secure and compliant data handling is essential, especially when dealing with personal or sensitive information. These factors make finding the right high-quality data to build reliable AI systems a daunting task. Making turning to experts when it comes to data sourcing and data labeling a great option.
At Objectways, we specialize in providing high-quality data labeling and sourcing services that tackle these challenges head-on. Our process is designed to be thorough, flexible, and transparent, ensuring that we meet the unique needs of every client.
Here’s a quick glance at what it’s like to work with us:
Throughout our process, we pride ourselves on keeping communication open and encouraging feedback. We are always happy to make any needed adjustments to ensure our annotations meet your expectations. Our goal is to deliver your data so that it’s ready for production.
We’ve taken a look at how high-quality data is the foundation of successful AI. Much like DNA shapes who we are, reliable, well-labeled data enables AI systems to learn, adapt, and deliver consistent results. Without it, even the most advanced AI models can fall short, leading to errors and mistrust.
At Objectways, we’re dedicated to helping you get it right. Our high-quality data labeling services can guide your AI model and help it be ready to tackle real-world challenges. Contact us today to take your AI projects to the next level.
High data quality leads to more accurate decisions. It’s like using the right ingredients in a recipe – good data leads to reliable results, while poor data can cause errors and confusion.


Explore the 7 core physical AI annotation types and learn how high-quality labels help robots understand, learn, and perform real-world tasks.
See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
