Table of content
Unlocking insights from PDfs
Here are simple steps to get started
Summary
Unlocking insights from PDFs using purpose built annotation tool
Today, many enterprises extract data from scanned documents, such as PDF’s, tables and forms, through manual data entry (that is slow, expensive and prone to errors), or through simple OCR software that requires manual configuration which needs to be updated each time the form changes to be usable. To overcome these manual processes, Deep learning based approaches have been developed to instantly read and process any type of document, accurately extracting printed text, handwriting, forms, tables and other data without the need for any manual effort or custom code. While there are many purpose-built third party softwares available, cloud providers have democratized the OCR capabilities. The popular cloud services include Amazon Textract, Google Vision or Microsoft Azure’s OCR Service. Many enterprises have adopted these services to unlock data out of PDFs or Image documents. So, we recommend customers to not waste cycles and valuable data science effort on building OCR systems.
When your organization processes a variety of documents, you sometimes need to extract entities from unstructured text in the documents. A contract document, for example, can have paragraphs of text where names and other contract terms are listed in the paragraph of text instead of as a key/value or form structure. Amazon Comprehend is a natural language processing (NLP) service that can extract key phrases, places, names, organizations, events, sentiment from unstructured text, and more. With custom entity recognition, you can identify new entity types not supported as one of the preset generic entity types. This allows you to extract business-specific entities to address your needs.
The custom entity recognition models require high quality labeled data for training. Performing annotations on blobs of text makes it very hard for understanding the context of a document. Let’s say in the document below, we need to extract key skills and experience. You can see that annotating it in original PDF appears lot easier and accurate than OCRed blob of text.

Formatted PDF

Extracted Text
So, how do I go about achieving better PDF annotation. Before diving deep, bit about labeling tools. While there are many labeling tools in the market, Amazon SageMaker GroundTruth offers lots of flexibility to create custom annotation UI and unlike other tools, it is entirely pay as you go means we can do a lot of experimentation without lock in.
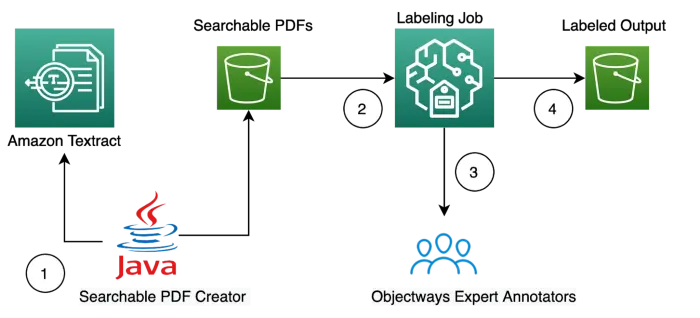
We demonstrate how you can use Objectways developed PDF annotation tool label PDF documents for Named Entity Recognition(NER) labeling. The annotation tool provides labeling entities, relationships among entities, overlapping entities, document classification along with a custom notes field all in a single annotation UI. The tool is really easy to configure and compatible with SageMaker GroundTruth. It also supports multi-page annotation. The input to the annotation tool is searchable PDF which can be easily created using a freely available utility on GitHub. The utility uses Amazon Textract to OCR and then creates a searchable PDF as the output.
Here are simple steps to get started:
- Use Searchable PDF tool to create searchable PDFs
- Contact Objectways (sales@objectways.com) to set up a data labeling job in SageMaker Ground Truth
- Our Expert annotators will label your data(We will do multiple quality passes to ensure high quality labels)
- Output labels are saved to your S3 bucket