Whenever you build an AI system, you are working with data. Data is raw information that can be collected and stored. This can be customer identities, payment records, images, videos, etc, which form an essential part of creating an AI system. In fact, data is at the center of AI innovation and is very valuable and sensitive.
AI systems are generally driven by AI models, and these models are trained to learn patterns and features from high-quality data. AI solutions implemented using strong and relevant data can provide impactful results. You can think of it like the foundation of a building that supports the entire structure.
Data being so vital to AI projects results in the need for data protection measures. Data protection not only safeguards people but also ensures data compliance and builds user trust. So, data privacy isn’t an afterthought; it’s a core design choice in AI projects from the very beginning

The Importance of Data Privacy (Source)
However, deciding how to protect sensitive data effectively can be challenging. Some popular data protection methods include tokenization, encryption, masking, and hashing, and each serves a different purpose in keeping information safe. Choosing the right one depends on your specific data protection needs.
In this article, we’ll explore tokenization vs encryption vs hashing, understand how these data protection methods compare, and learn how to choose the right one for your AI project. Let’s get started!
Before we dive into comparing tokenization vs encryption vs hashing, let’s first walk through what each method does to get a better understanding of what they’re capable of. They might seem similar since all three aim to protect sensitive data, but they work in very different ways. Choosing the wrong one is like using the wrong key to open a lock; both are keys, but only the right one will fit.
Tokenization converts sensitive data into nonsensitive digital substitutes called tokens that have no exploitable meaning or value outside the system that issued them. It’s like using poker chips instead of real cash; the chips represent money but have no actual value on their own.
The original data is stored securely in a token vault, while the token can be used for transactions or processing. Even if a token is stolen or intercepted, the real data remains protected because only the vault can map tokens back to their original values.
For example, in healthcare, tokenization makes it possible for researchers to analyze patient outcomes without exposing personal identifiers, supporting compliance with HIPAA privacy regulations. Similarly, in finance, a bank’s AI-driven fraud detection system can tokenize customer account numbers so the model can still identify unusual or suspicious transaction patterns without accessing any real customer data.
Here’s a simpler example: payment data. Details such as an account number, last name, or contact information can be replaced with randomly generated tokens.
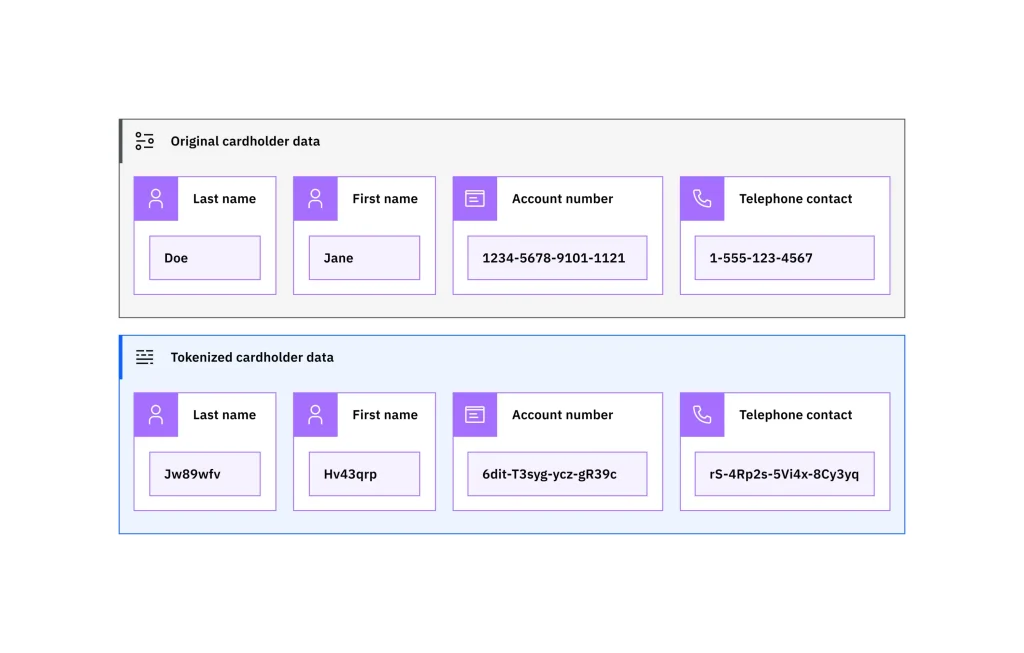
An Example of How Tokenization Works to Protect Data. (Source)
Have you ever passed coded secret messages to your best friend in class? This is basically encryption.
Encryption protects data by transforming it into unreadable (coded) text, known as ciphertext. Keys are used to code and decode this ciphertext. Only someone with the correct keys can restore the code text to its original value. Beyond data security, it’s also vital for meeting privacy regulations and maintaining user trust in the digital world.
Encryption can be done symmetrically or asymmetrically. Symmetric encryption uses one shared key for both locking and unlocking data, while asymmetric encryption uses a public key to encrypt and a private key to decrypt. The outcome is the same for both; the data is securely encrypted for transmission.
For instance, in the healthcare sector, when large medical image files are transferred to the cloud for training AI models, encryption ensures safety. Even if the files are accessed by unknown individuals, they remain useless to them without the specific key to decode them.
Just like our fingerprints identify us, data can have its own unique fingerprint, too. That is what hashing does. Hashing uses a one-way mathematical function to turn data into a fixed-length digital fingerprint. Unlike tokenization or encryption, hashing cannot be reversed, which makes it especially useful for verifying data integrity in AI workflows.
Consider a situation where AI developers want to make sure their training data has not been altered. They can hash all their files before training and later compare those hash values to confirm everything is still the same. Even the smallest change in a file would create a completely different hash, instantly showing that something has been modified.
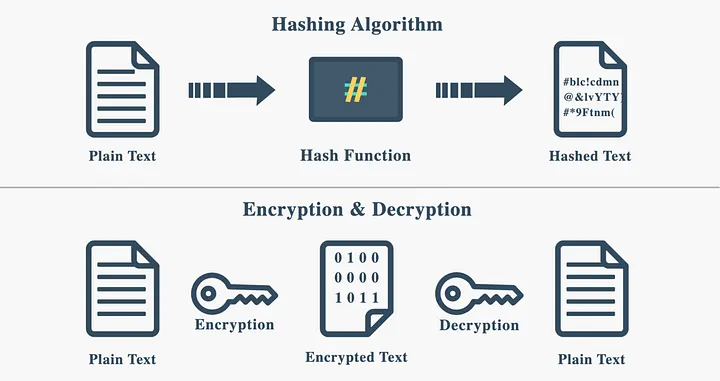
Hashing vs Encryption: Knowing the Difference. (Source)
Now that we have a better understanding of the basics of tokenization, encryption, and hashing, let’s take a look at how they each differ. Tokenization replaces sensitive data with meaningless stand-ins, encryption scrambles data into coded text that can be unlocked with a key, and hashing creates a fixed, irreversible fingerprint of the data.
Each method plays a different role in keeping data safe. Tokenization works well when you need to hide sensitive details but still keep the data usable. Encryption is best for protecting data that needs to be shared or stored securely. Hashing is great for checking that data hasn’t been changed, since it can’t be reversed. Knowing when to use each method helps you protect data effectively while keeping your AI systems running smoothly.
The table below provides a quick comparison of tokenization vs encryption vs hashing.
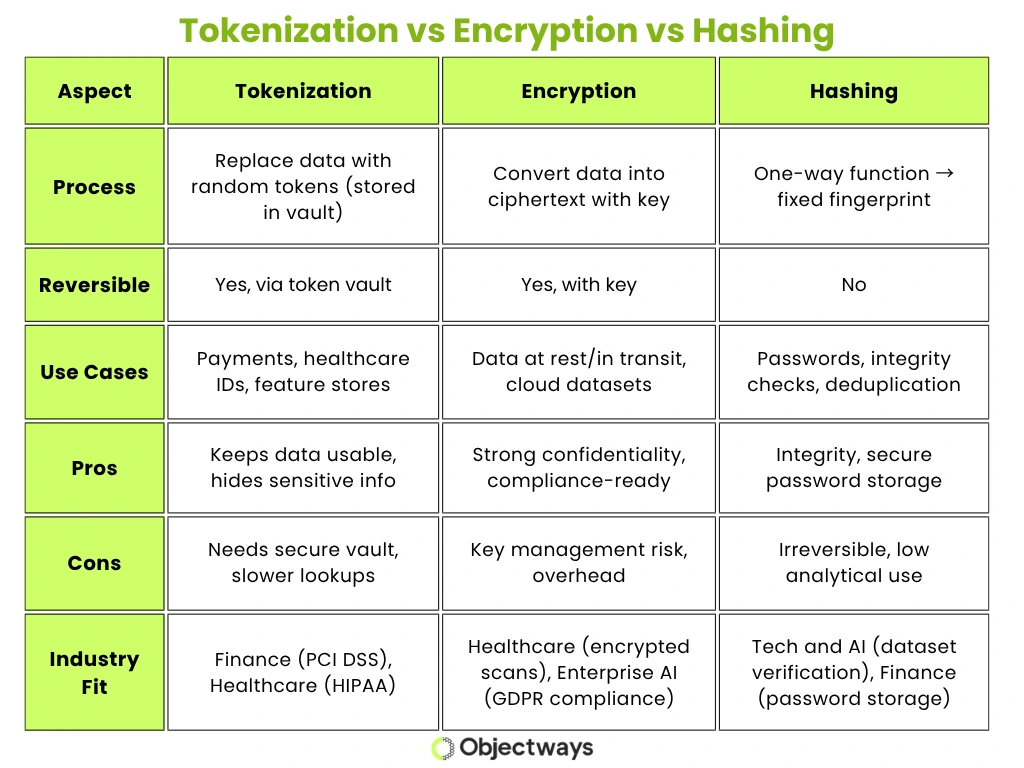
Comparing Tokenization vs Encryption vs Hashing
So far, we have focused on tokenization vs encryption vs hashing, but there is another important comparison to consider: encryption vs tokenization vs masking.
Masking is often the simplest way to protect data while keeping it partly visible. It hides specific parts of the information, such as showing only the last few digits of a credit card or phone number. This makes it helpful in testing, analytics, or customer-facing systems where data needs to look real but cannot expose sensitive details.
Masking is different from tokenization and encryption because it doesn’t actually secure or transform the data at a deeper level. Instead, it simply hides parts of it for display or limited use. Once masked, the data cannot be reversed or fully recovered, but the original data still exists elsewhere in its complete form. That is why masking was not our main focus earlier – it is not commonly used in AI model training or automated data pipelines, where the data usually needs to remain both secure and usable for processing.
Tokenization and encryption, on the other hand, offer stronger protection for data that must be shared, stored, or analyzed securely. Understanding how tokenization vs encryption, vs masking differ helps in choosing the right method depending on whether your data needs to stay usable, hidden, or recoverable.
Data privacy in AI is like building a strong, secure bridge that carries heavy loads. The load represents training data, which must move safely across the system without falling into unsafe hands. Methods such as tokenization, encryption, and hashing form the structural supports of this bridge, keeping it both reliable and secure.
For example, using tokenization, biometric AI systems can turn fingerprints or facial data into tokens so authentication works without revealing the real data. Likewise, in e-commerce, customer IDs can also be tokenized, letting recommendation engines track buying habits without ever handling raw personal data.
Unlike tokenization, encryption keeps data safe both when stored and when shared. Researchers have explored advanced encryption methods such as homomorphic encryption, which allows computations to be performed on encrypted data without ever decrypting it.
In studies related to healthcare AI, this technique has been used to train models on encrypted medical scans stored in the cloud, ensuring that sensitive patient data remains protected throughout the process. Even if the encrypted data were accessed by unauthorized parties, it would remain unreadable. Some research has also explored combining homomorphic encryption with blockchain technology to securely record data access and updates, adding an extra layer of transparency and trust.
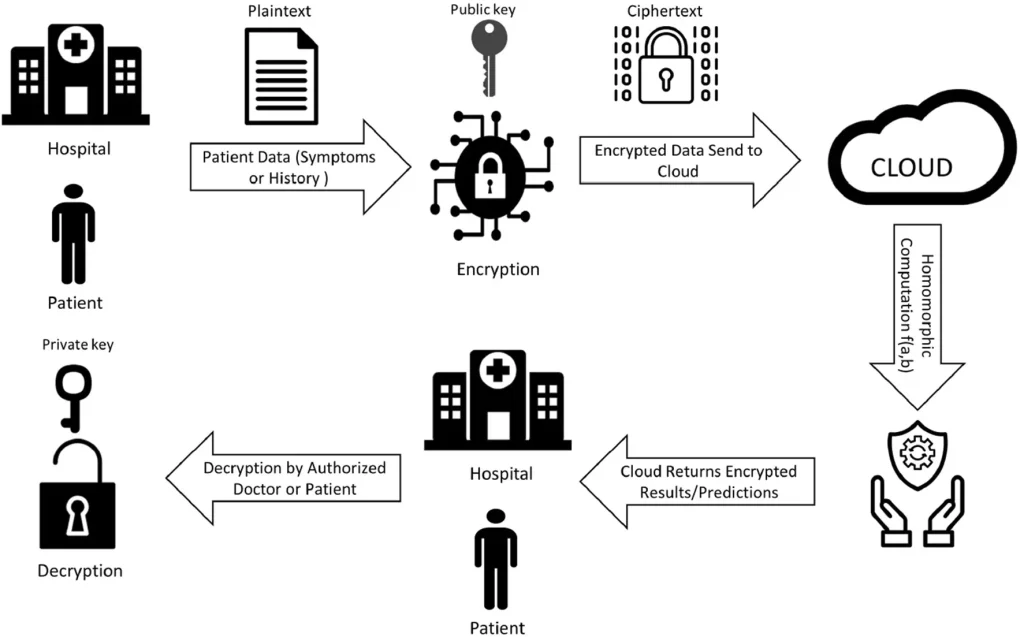
An Example of Homomorphic Encryption in Healthcare Systems (Source)
Hashing, on the other hand, makes sure that datasets used for training are unchanged. For example, in cybersecurity and digital image systems, techniques like perceptual hashing generate fingerprints that reflect visual similarity. This helps trace image provenance, confirm content integrity, or detect duplicates without ever exposing the original images.
Choosing the right data protection method between tokenization, encryption, and hashing depends on your specific AI project goals. Here are some considerations that can guide enterprise teams in designing secure AI systems:
While tokenization, encryption, and hashing are essential for protecting sensitive information, they also have some limitations. Understanding these challenges can help AI teams select the optimal combination of data protection methods.
Here are some limitations to consider:
At Objectways, we help enterprises address these challenges by delivering high-quality data solutions and secure workflows for AI projects.
Nowadays, there are many new data security techniques that are trending, especially in the AI space. Confidential computing is one such trend. Many researchers are already using it for data security in AI.
It isolates executable code and data within a hardware-based trusted environment so that even the infrastructure provider cannot inspect the data being used. This enables AI workloads to run on sensitive data in the cloud or at the edge without exposing it to the host system.
Another emerging technique is secure multi-party computation (SMPC). It lets different organizations work together on data analysis without actually sharing their raw data. Each party keeps its own information private while still contributing to the overall result. This makes SMPC especially useful in areas like healthcare and finance, where data privacy is crucial but collaboration is still needed to gain meaningful insights.
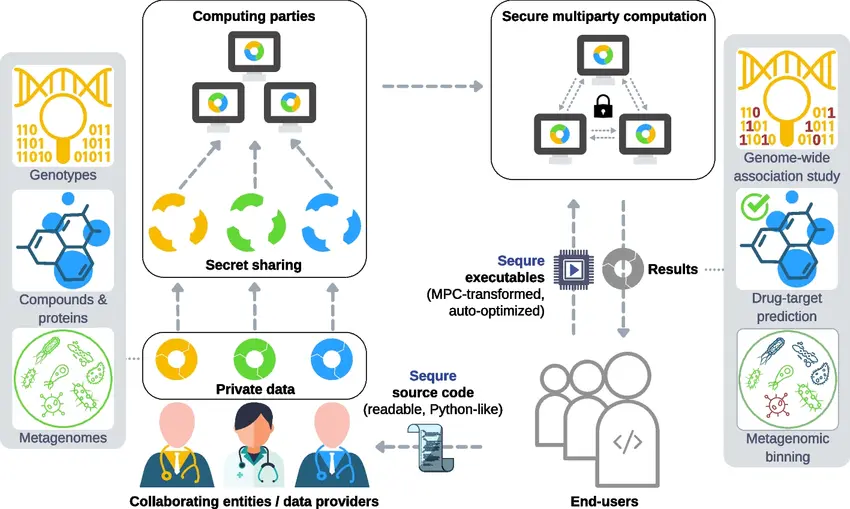
An Overview of Secure Multi-Party Computation (Source)
Tokenization, encryption, and hashing each play an important role in protecting sensitive data. Tokenization replaces identifiers with secure tokens while keeping the data useful for analysis. Encryption locks information with cryptographic keys so only authorized users can access it. Hashing creates irreversible digital fingerprints that help verify data integrity and detect any changes.
The right method depends on how sensitive your data is, the regulations you need to follow, and what your AI models require. In most cases, organizations combine these techniques to balance privacy, security, and performance.
At Objectways, we specialize in secure and high-quality data annotation and AI data pipeline services. Our expert teams label and prepare data across text, image, audio, and video while maintaining full compliance with SOC 2 Type II, HIPAA, and ISO 27001 standards. Build your next AI project with confidence and book a call with us.
Tokenization substitutes sensitive values, encryption locks data with keys, and masking hides portions. Each protects information differently based on needs.

See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.
