When a robot moves through a busy warehouse and handles packages, it can seem as if a single AI system is doing everything. But in reality, several AI systems run in parallel.
One maps the environment and avoids obstacles, another identifies the right items, and another fine-tunes grip and movement. All of this happens in real time, so the robot can work safely and efficiently alongside people.
It looks seamless, but it is usually powered by a mix of technologies. For example, machine learning methods can help a robot learn patterns from data and make decisions, such as selecting actions based on sensor inputs.
On top of that, deep learning, which is a type of machine learning, is often used for more complex perception tasks like recognizing objects or interpreting cluttered scenes. Meanwhile, computer vision focuses on extracting useful information from images or video so the system can understand what it is seeing and act on it.
Because these tools overlap, the terms are often used interchangeably. Understanding the differences is key to using each technology effectively and applying the right one to the right problem.
In this article, we’ll explore machine learning, deep learning, and computer vision, and see how they work together in real systems. Let’s dive in!
So how do all these AI terms connect? A simple way to picture it is like a set of nested circles, where the big, broad ideas sit on the outside, and the more specialized ones fit inside.
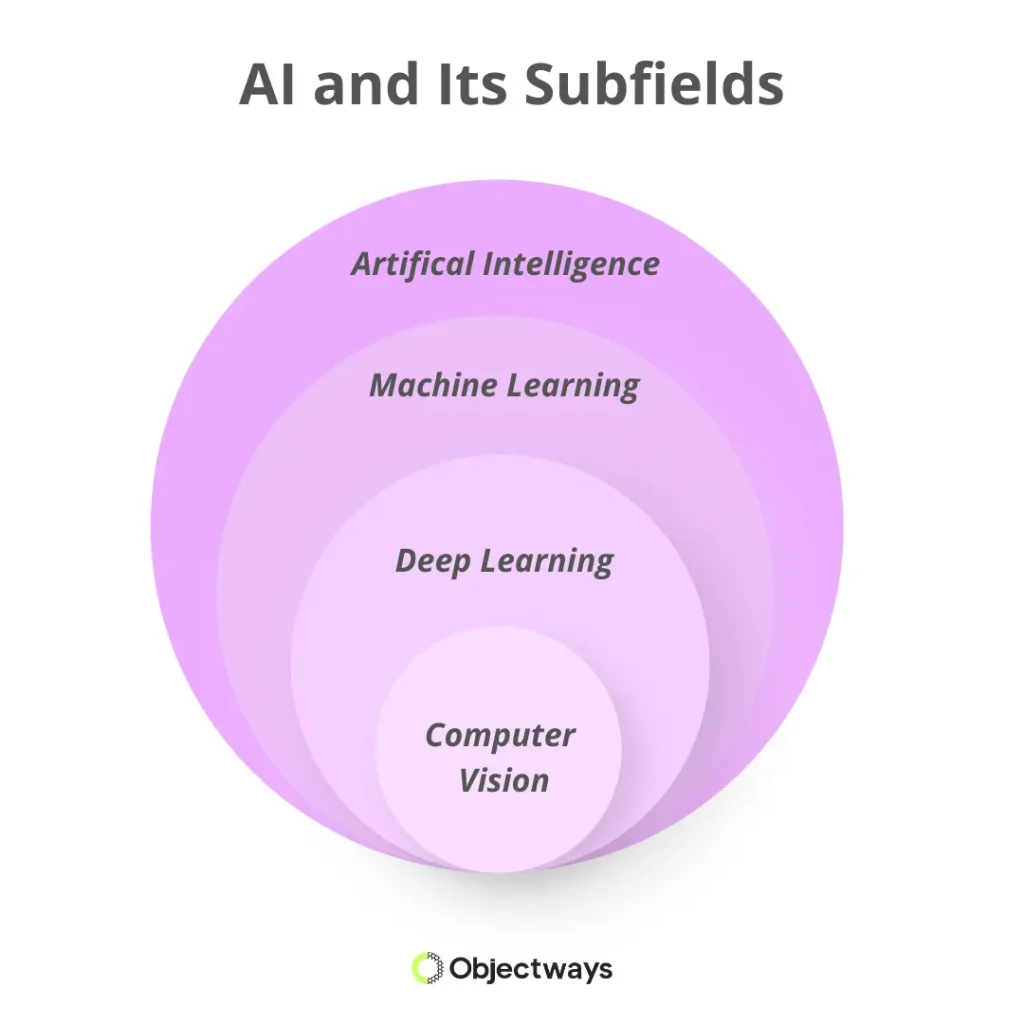
The Hierarchy of AI
AI is the biggest circle; it is the broad goal of building systems that can do things we usually associate with intelligence. Inside AI is machine learning, where models learn from data instead of relying only on handwritten rules.
Within machine learning is deep learning, which uses many-layered neural networks to learn richer, more complex patterns. And when those deep learning models are applied to images and video, you get computer vision, a specialized area that helps machines make sense of what they see.
Before we compare machine learning, deep learning, and computer vision, let’s first look at what each technology focuses on to better understand their strengths and weaknesses.
You can think of machine learning as training a model to make decisions from data. Instead of relying only on fixed, handwritten rules, the model learns patterns from examples and improves as it is trained and evaluated. Once trained, it can make predictions, classify inputs, find trends, or flag unusual cases based on what it learned.
How a system learns depends on how it is guided and the type of data it receives. Here are a few of the main approaches that shape how machines learn and improve over time:

An Overview of Supervised, Unsupervised, and Reinforcement Learning (Source)
Some problems are just too messy for basic machine learning to handle well, especially when the data is complex, like images, speech, or natural language. In those cases, deep learning helps by learning in layers, building from simple signals to a more detailed understanding over time, a bit like how we improve with practice.
It works through neural networks, which are made up of connected layers that pass information forward. Early layers learn basic features, and later layers combine them into more meaningful patterns. With enough layers, the model can pick up relationships and structure that simpler approaches often miss.
Here are a couple of ideas driving deep learning:
A good example of deep learning in action is detecting damage on products or packages from photos.
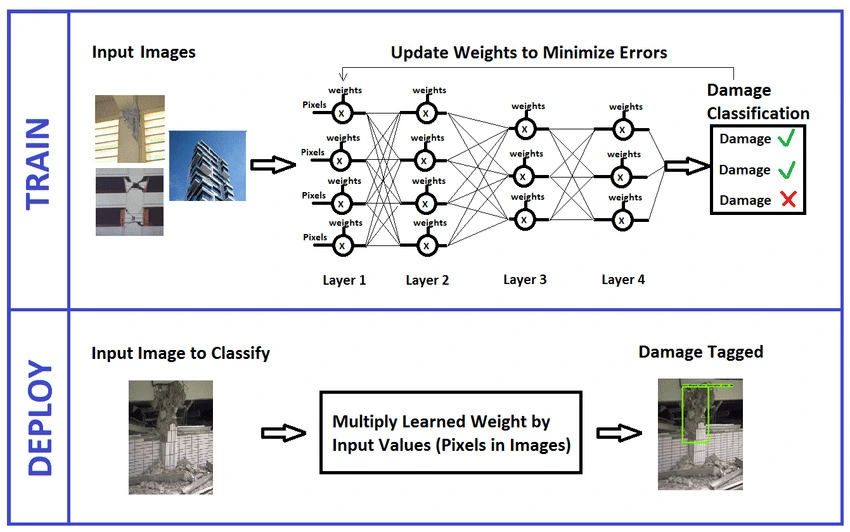
Using Deep Learning for Damage Detection (Source)
Small dents, tears, or cracks can look completely different depending on lighting, angles, and backgrounds, so a basic machine learning approach often needs lots of hand-crafted features and still misses edge cases. Deep learning can learn the visual cues directly from many labeled images, which makes it better at spotting subtle damage in real-world conditions.
Next, let’s take a closer look at what computer vision is and how it works. Computer vision is a branch of AI that makes it possible for machines to see and interpret the visual world just like humans do.
This ability often comes from deep learning models that analyze images in different ways. One of the most common approaches is the use of convolutional neural networks (CNNs). They look at an image in small sections, picking up details like edges, textures, and shapes. This close-up view helps the system understand what the smaller parts of an image represent.
On the other hand, models like vision transformers take a broader perspective. They split an image into patches and study how these patches relate to each other. That broader context helps the model understand the overall scene, not just individual details.
Once the models learn to recognise patterns, computer vision systems can perform different tasks to understand images and videos. Here are some commonly used computer vision tasks:
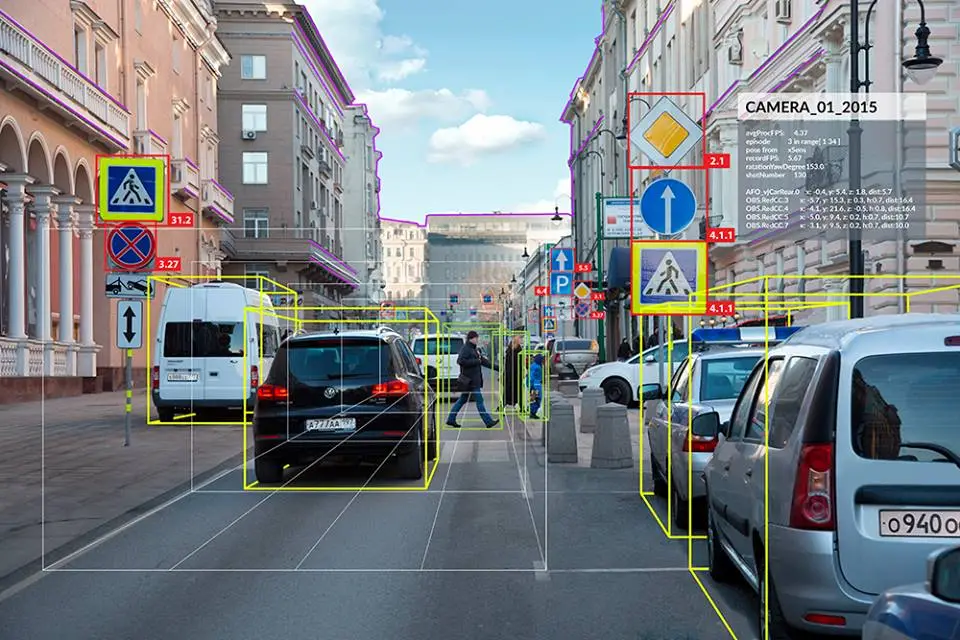
Identifying Cars, Pedestrians, and Road Signs Using Object Detection (Source)
Now that we have a better understanding of the basics of computer vision and machine learning, let’s take a look at how they each differ.
In a smart factory, machine learning can analyze production data to predict equipment failures or optimize inventory. It mainly works with numbers and patterns in data to support better decisions.
Computer vision, however, focuses on visual inputs. It can spot product defects, detect safety hazards, monitor workflows, and even flag issues like a misaligned part on an assembly line or missing safety gear.
Even though they are different, they often work best together. Computer vision turns images and video into useful signals, like defects found or parts detected, and machine learning can use those signals to predict outcomes and guide what the system should do next.
Next, let’s weigh deep learning and computer vision.
Deep learning is the set of techniques that learns complex patterns from data, while computer vision is where those techniques are used to understand images and video. That is why tasks like defect detection, object recognition, and scene understanding fall under computer vision, and deep learning is often what powers them.
For example, consider a quality check camera on a packaging line. A computer vision system captures images of each box and analyzes them to check for issues like visible damage, missing or misprinted labels, and seal defects. Often, a deep learning model trained on many labeled examples of acceptable and defective packages does the core recognition work, which helps it stay reliable even when lighting, camera angle, or packaging appearance varies.
Similar to computer vision, another major branch of AI is natural language processing, or NLP. NLP deals with language, things like text and speech. Computer vision deals with visual data, like images and video.
In a simple sense, NLP helps machines understand what we say and write, while computer vision helps them understand what they see. Because the inputs are so different, the models learn different patterns.
NLP learns how words relate to each other and how meaning changes with context. Computer vision learns visual cues like shapes, textures, and how objects are arranged in a scene.
In real-world systems, these two areas often overlap. A simple example is optical character recognition, or OCR, which extracts printed or handwritten text from an image and converts it into machine-readable text.
Some models go further by learning from images and text at the same time. For example, CLIP is trained on image-text pairs and learns to match a picture with the most relevant text description, which makes zero-shot image classification possible using only text prompts.
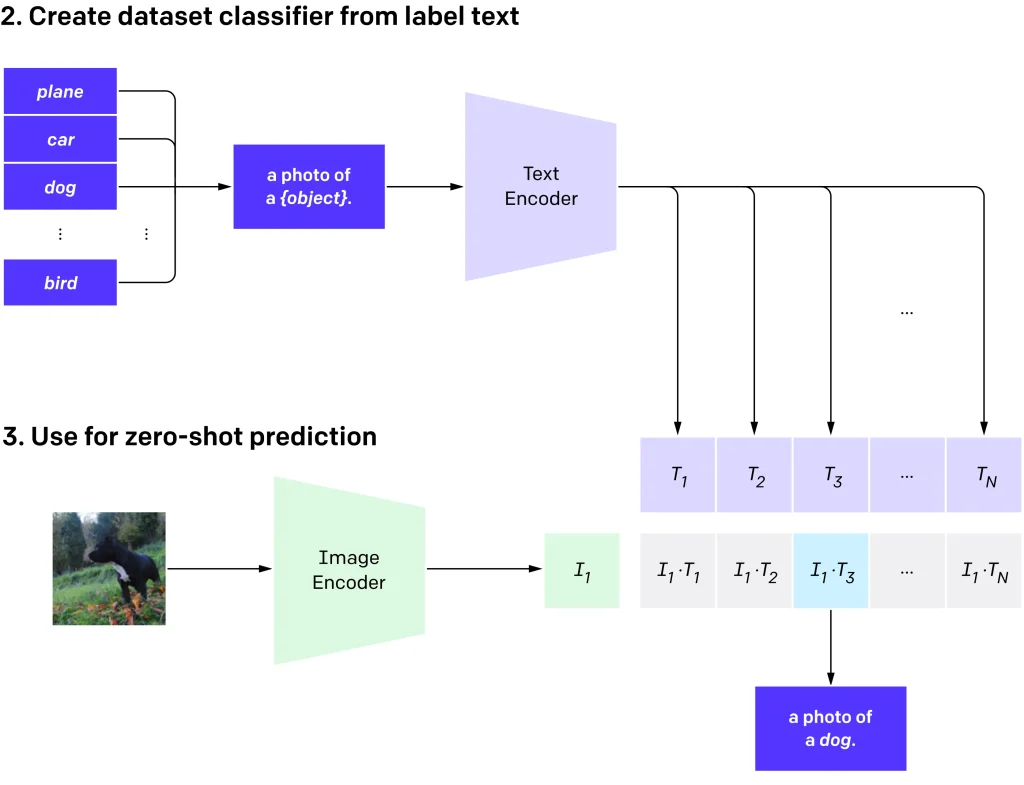
How Zero-Shot Image Classification Through CLIP Works (Source)
Now that we have covered machine learning, deep learning, computer vision, and natural language processing, let’s quickly compare how they differ.
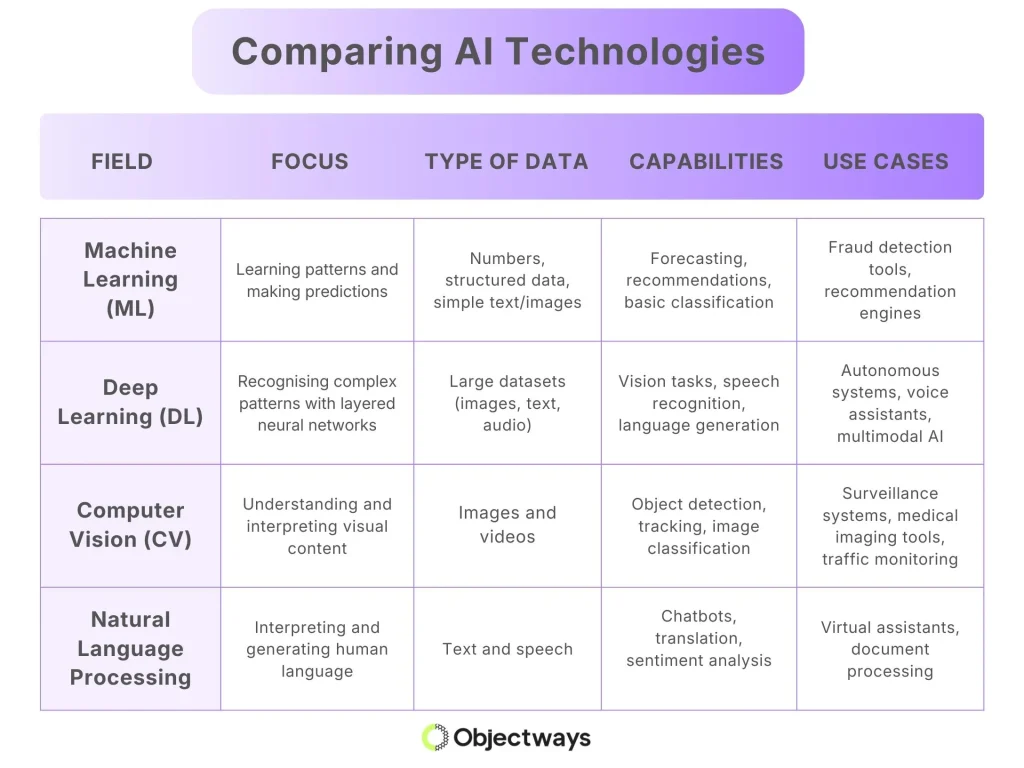
Machine Learning Vs. Computer Vision Vs. Deep Learning Vs. NLP
The table above summarizes the key differences between them.
Next, we’ll walk through a few real examples where these AI technologies are used together.
In many industrial settings, the fastest way to make a good decision is to understand what the system is seeing. When computer vision and machine learning team up, they turn raw camera footage into clear signals that can guide action in real time.
Take steel manufacturing, for example. When burner flames inside a reheating furnace start behaving abnormally, it can be an early sign that something is off, like combustion drifting out of tune or a burner issue starting to develop. Thermal cameras can be used to monitor those flames around the clock.
Computer vision then translates the thermal images into measurable signals that describe flame behavior. Machine learning analyzes those signals to spot patterns that indicate the process is drifting away from normal. Instead of waiting for a visible fault or a shutdown, the system can flag an early warning and help operators intervene before the issue turns into a bigger problem.
In many fields, important information is buried inside scanned documents or old images that are hard for machines to interpret. We can read them easily, but can an AI system understand them with the same clarity?
When text is embedded in labels, handwritten notes, or faded scans, even a small error in reading can affect the final analysis. This becomes a challenge for tasks that rely on accurate extraction, especially when dealing with large collections of image data where manual transcription is slow and inconsistent.
An interesting example is herbarium specimen digitization. In this application, computer vision first processes each specimen image and extracts the label text using optical character recognition (OCR).
Once the text is available, natural language processing highlights plant names, locations, and collection dates, turning scattered notes into structured information. This lets the entire collection be converted into searchable databases with minimal human effort.
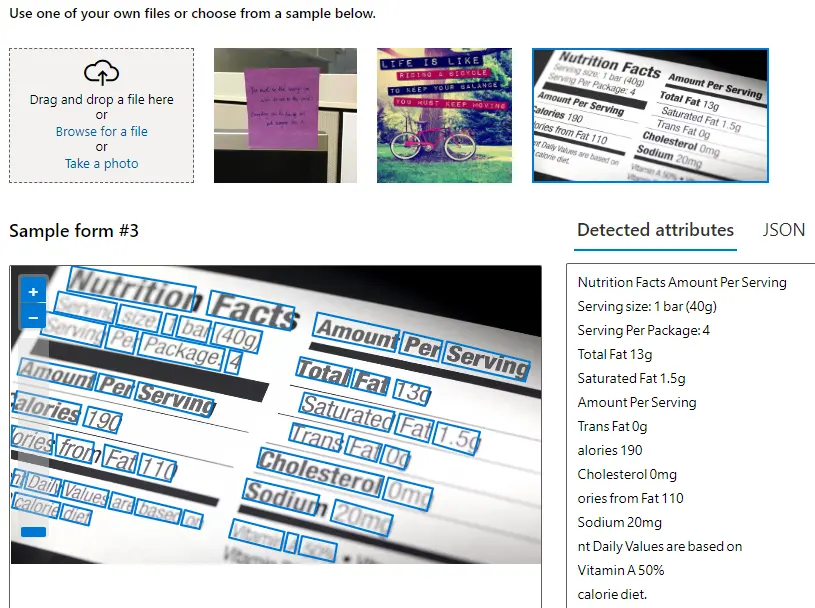
A Look at Optical Character Recognition (OCR) (Source)
On busy city roads, an autonomous vehicle has only a split second to understand what’s happening around it. A lane marking that’s slightly faded, or a pedestrian stepping off the curb, can change the entire driving decision. If the system misinterprets its inputs, the consequences can be serious.
Deep learning models help prevent these mistakes by giving the vehicle a detailed understanding of its surroundings. They analyze camera images to separate the road from sidewalks and identify vehicles, pedestrians, and other objects needed for safe navigation. But in real-world settings, rain, shadows, and crowded streets can make this interpretation far more challenging.
To address these issues, researchers have been improving vision models to make them more reliable in complex environments. One recent study on semantic segmentation showed that enhanced deep learning models can identify road regions with much higher accuracy. Instead of confusing road edges with nearby structures, the system learns to draw cleaner boundaries and understand the scene more consistently.

Semantic segmentation can be used to analyze traffic. (Source)
Regardless of the type of AI technology you are building, one thing stays constant: data is the foundation. Autonomous systems, computer vision models, and robotics applications all depend on large volumes of accurate, well-prepared training data to perform reliably in the real world.
If you are working on these technologies and need high-quality AI data, you are in the right place.
At Objectways, we make it easier for AI and robotics teams to develop smarter and more dependable systems. We manage data collection, evaluation, and annotation, along with detailed quality checks that ensure every dataset is consistent and ready for training. With more than 2,000 specialists, including experts focused on robotics, vision data, and sensor inputs, we can support projects of any size with precision and speed.

The Team at Objectways Working on Egocentric Data. (Source)
Machine learning powers many AI systems, deep learning pushes performance further on complex problems, and computer vision applies these capabilities to visual data. Each one plays a different role, but the biggest impact comes when they work together to solve real, practical challenges.
Even with fast progress, success in real environments still depends heavily on data. High-quality datasets help systems handle edge cases, adapt to variation, and stay reliable across changing conditions.
That is where Objectways comes in. From targeted data collection to precise annotation and quality checks, we help teams build machine learning and computer vision systems that are accurate, efficient, and ready to deploy.
If you are building an AI project and need data you can trust, we would love to help. Book a call with us to move faster.
Computer vision focuses on understanding images and video, while deep learning is a modeling approach. Deep learning often powers computer vision systems, helping them recognize objects, detect defects, and understand scenes more accurately.

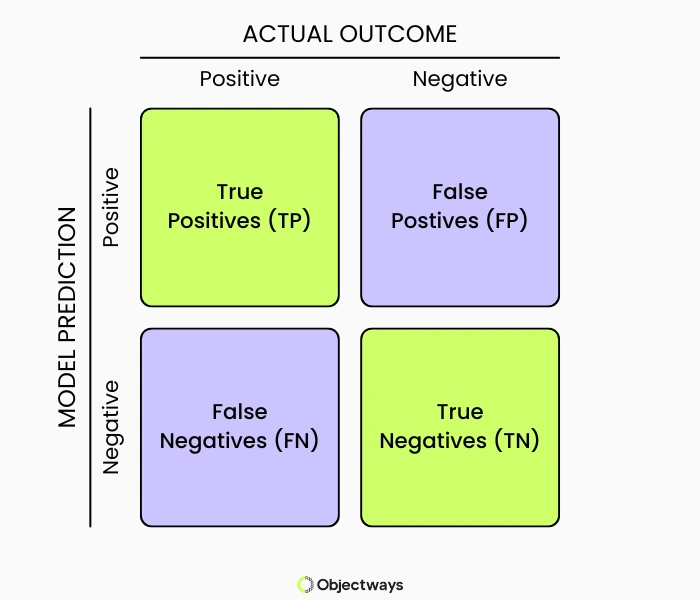
Explore key classification metrics such as precision, recall, F1 score, and the calibration curve. Learn how to evaluate AI and machine learning models.
Join us as we explore what is content moderation, how platforms apply it across multimedia, and how AI and human reviewers keep online spaces safe.
