The success of any AI application depends on two key factors: the AI model and the data it’s trained on. Both play a crucial role in shaping the entire AI development process. An AI model is an intelligent system that learns from data to make predictions or decisions. Data is the input or information it learns from; better data leads to a better model.
Building a reliable AI model begins with the right foundation, which can be either model-centric or data-centric. The model-centric approach focuses on fine-tuning the model’s core design, while the data-centric approach focuses on improving the quality and diversity of the training data. Today, these two strategies represent the core of an ongoing “AI war” in development.
As AI tools like ChatGPT, Gemini, and Claude become more popular, a new question arises: Is AI progress happening because the models are getting bigger, or because they’re being trained on better, cleaner, more useful data?
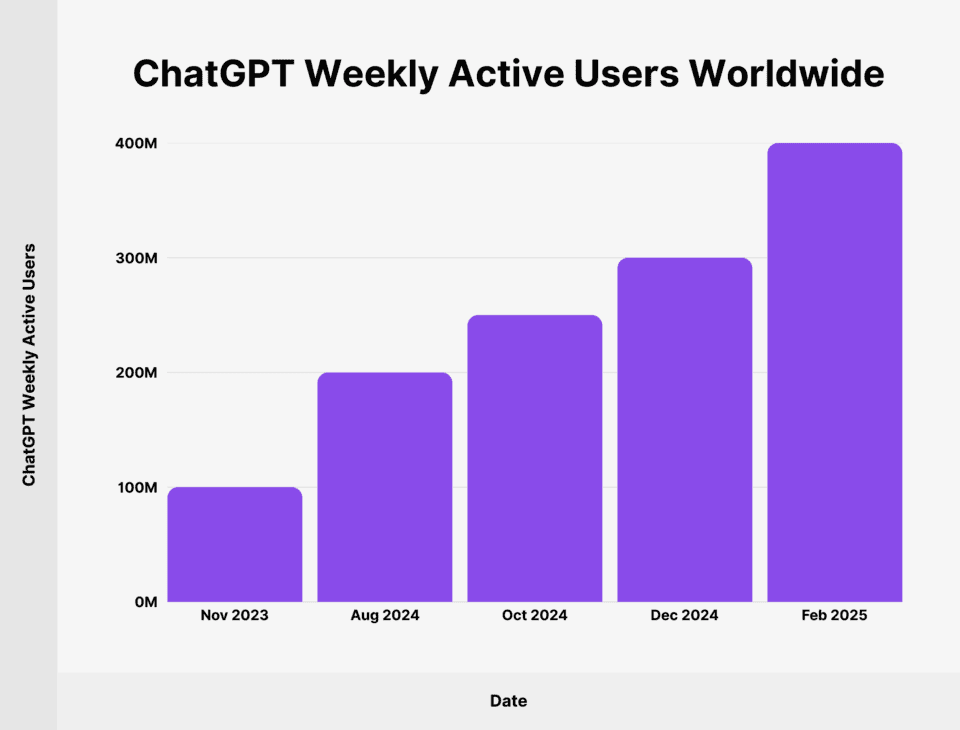
The popularity of AI tools like ChatGPT continues to increase every week. (Source)
Many experts are starting to agree that just increasing the number of parameters (model-centric) isn’t enough. In most cases, smaller machine learning models trained on high-quality data can outperform larger ones trained on messy, biased datasets.
Think of it like choosing ingredients for a dish. Good quality ingredients can create a great dish. Similarly, AI models need clean, diverse, and well-curated data to perform well.
In this article, we’ll explore data-centric vs model-centric AI. We’ll explore both approaches, their features, and why taking a data-centric approach is an easy win. Let’s get started!

Comparing Data-Centric Vs Model-Centric AI Development
Before diving into this so-called “AI war” (don’t worry, no robots were harmed), let’s first understand what model-centric and data-centric approaches to AI development actually mean.
Let’s start with the model-centric approach first.
The model-centric approach to AI is the more popular of the two, forming the backbone of most AI applications. In fact, the majority of AI applications today are built on a model-centric approach.
This method focuses on improving the AI model itself to get better results. It involves experimenting with different types of models, evaluation methods, and training methods to see what works best. Here, the data stays the same; most of the work is done by adjusting the code or changing how the model is built.
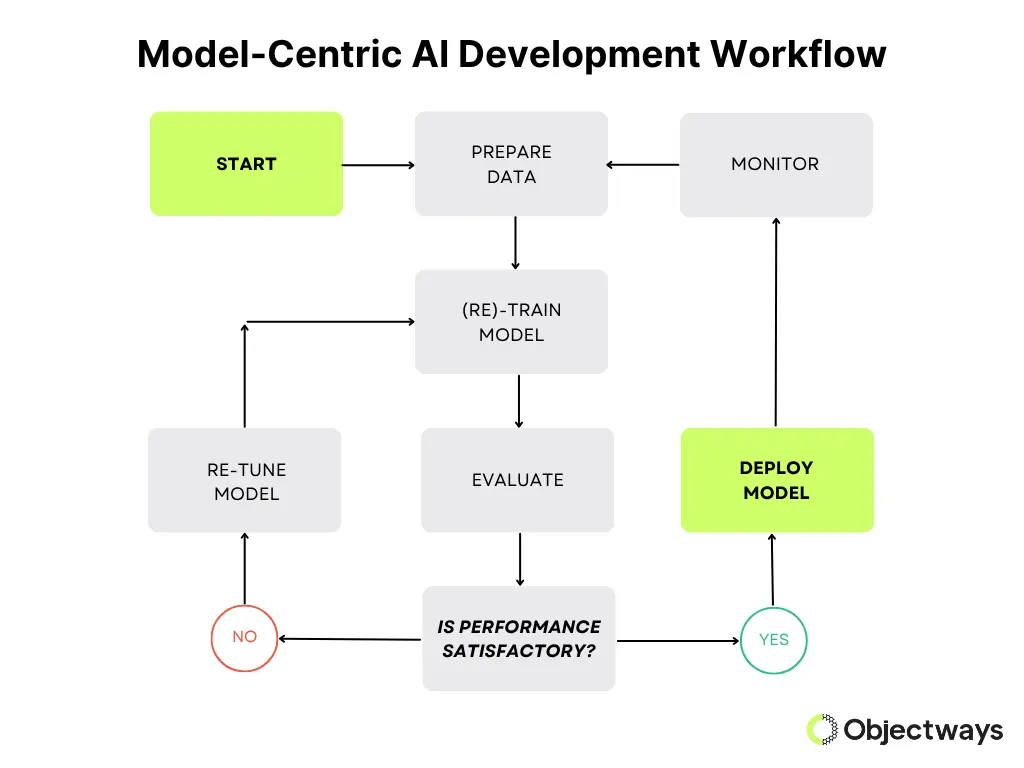
Model-Centric AI Development Workflow
One reason for the popularity of this approach is that the AI community is heavily influenced by academic research, which often puts a lot of focus on the design of the model. In fact, according to AI experts like Andrew Ng, more than 90% of research papers in this domain are model-centric and not data-centric.
However, the model-centric approach works best when high-quality data is already available and you want to experiment with various AI models, though it often demands substantial computing power. It’s widely used in research aimed at innovating and exploring new model architectures.
Unlike the model-centric approach, the core of the data-centric approach is the data itself. It is at the center of every decision-making process, especially in businesses.
A data-centric approach can help businesses stay better aligned with the needs of their customers, employees, and other stakeholders. By relying on high-quality data, the AI model can operate in a more accurate, organized, and transparent manner, making AI systems run more smoothly.
The basic idea behind a data-centric approach is that even simple models can perform very well if they’re trained on clean, diverse, and well-labeled data. This method is especially useful in fields such as healthcare and finance, where high-quality data is scarce but valuable.
It can lead to more reliable and easier-to-understand models, reduce the need for heavy computing, and help cut down on bias. Some key traits of a data-centric approach include fixing label errors, adding more variety to the data, and making sure it’s relevant to real-world use, all while keeping the model simple and stable.
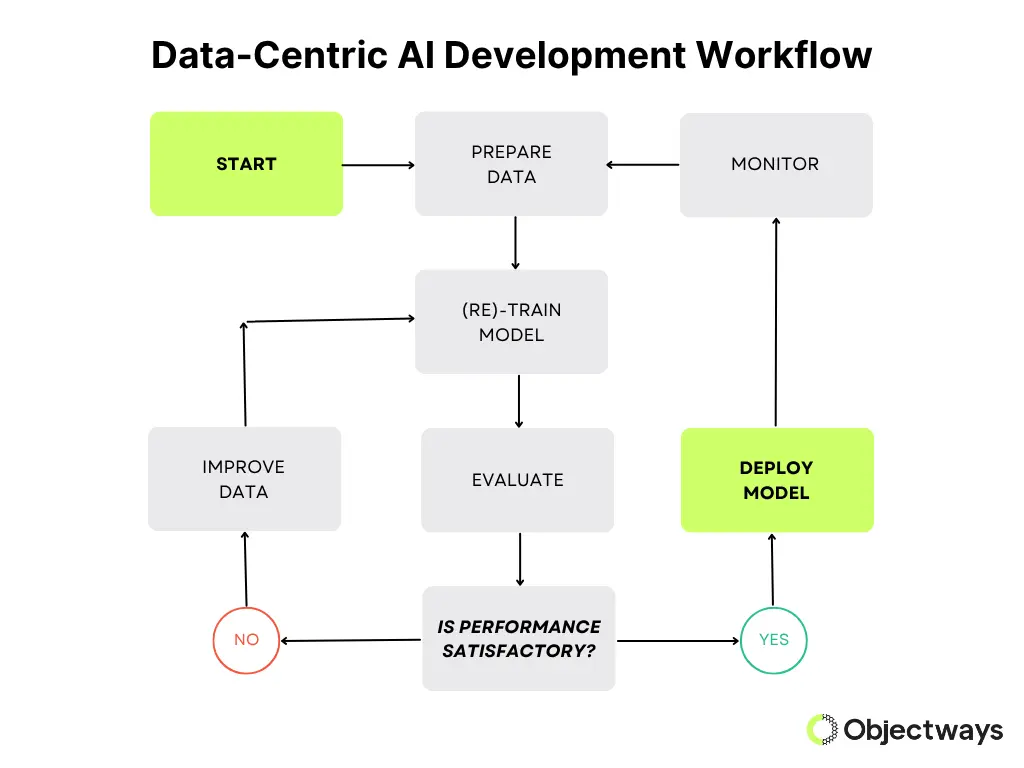
Data-Centric AI Development Workflow
Now that we have a better understanding of each approach, let’s discuss why there is a debate or “AI war” regarding these approaches.
It basically comes down to where improvements in AI should be focused. Model-centric development aims to design better models, while data-centric development focuses on the quality of the data used to train them.
Next, let’s explore why the latter is a better option.
High-quality data is the lifeblood of every AI system. Machine learning models, which power most cutting-edge AI systems, learn patterns, relationships, and rules from large datasets full of diverse data.
The quality, range, and variety of training data directly affect how accurate, fair, and helpful the AI model is. If the data is limited or flawed, the model will reflect these issues in its responses. It will also negatively impact companies that use such models. In fact, poor data quality costs organizations an average of $12.9 million every year.
High-quality data sets the stage for reliable and responsible AI models and systems. It needs to be diverse (fairly representing different people and situations), accurate (trustworthy), and well-labeled (so the AI knows what it’s learning). When these standards are met, AI models are more likely to produce results that are fair, clear, and useful.
A model-centric approach often scales up an AI model. Its size, complexity, or computing power, such as the increased number of layers and parameters, are all increased to improve performance.
You might think that a bigger model is an improvement. That’s true to an extent. However, it takes a lot of resources to scale up a model, especially large language models (LLMs). For example, training OpenAI’s GPT-3, which has 175 billion parameters, consumed approximately 1,287 megawatt-hours of electricity, equivalent to the energy consumption of an average household over 120 years.
Even after training, using these AI models in real-time and running inferences can be costly and use a lot of energy. Especially when done at a large scale.
In many cases, the cost remains high even when the model’s improvements are limited. For example, doubling a model’s size may only slightly improve its ability to understand language or generate images.
Because of this, researchers, as well as the broader AI community, are starting to question if just scaling up is the best way forward, and are now exploring smarter, more efficient ways to build and train AI models. This is where the so-called “AI war” begins as experts debate whether to build bigger models or focus on better data.
Here’s a closer look at some practical AI development challenges:
Now that we’ve discussed both model-centric and data-centric approaches and learned the limitations of the model-centric approach, let’s take a closer look at some real-world examples that showcase why dataset improvements are better.
Bigger AI models don’t always mean better results because size alone doesn’t guarantee quality or accuracy. While larger models have more parameters, similar to our brain cells, they also require more computing power. Plus, they can also be slower and more expensive to run. In many cases, a smaller, well-trained model with high-quality data can perform just as well, or even better, than a bigger one.
For example, OpenAI’s GPT-4 is an upgrade over the previous version, GPT-3.5. GPT-4 performed well for complex tasks like legal or medical exams, offering more accurate and thoughtful responses. It even scored in the top 10% on the bar exam compared to GPT-3.5’s bottom 10%. However, for everyday tasks, the performance gap is limited in comparison.
With well-crafted prompts, GPT-3.5 can deliver similar results (as that of GPT-4) faster and at a fraction of the cost (about 0.4 cents vs. 9 cents) for the same task. This makes GPT-3.5 a more practical choice for everyday routine use, even though GPT-4 is the bigger model.
By improving the quality of the data used to train AI models, a data-centric approach often leads to better results. Clean, well-labeled, and diverse data help the model learn more accurately and make fewer mistakes.
Even a large and powerful model won’t perform well if it’s trained on poor or biased data. Think of it like a student learning the wrong things from poorly made textbooks.
An interesting example of this comes from a team of researchers who tested the impact of model-centric vs. data-centric approaches across tasks like steel defect detection, solar panel analysis, and surface inspection. Their findings are shown in the table below.
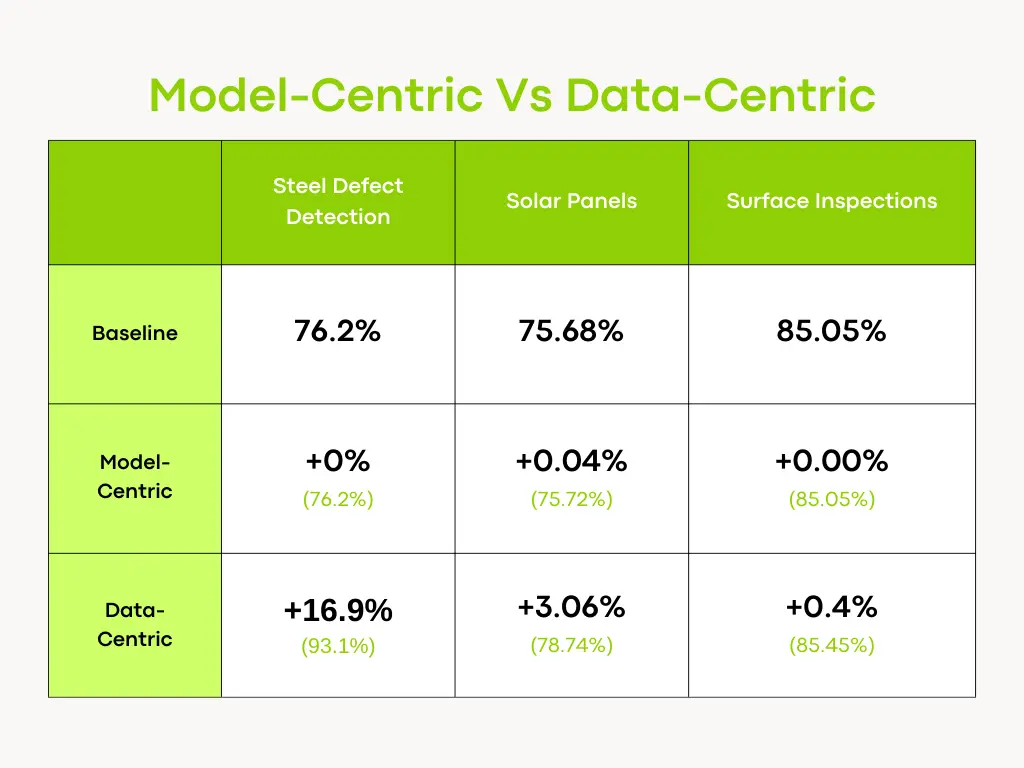
Results of Comparing Model-Centric and Data-Centric Approaches. (Source)
Their research showcases how improving data quality can make a much bigger difference in the AI model’s performance rather than just tweaking the model. In tasks like detecting steel defects, analyzing solar panels, and inspecting surfaces, a model-centric approach made little difference, boosting accuracy by as little as 0–0.04%. But when the focus shifted to improving the data, the results improved significantly. For example, in steel defect detection, accuracy jumped from 76.2% to 93.1%, which is a 16.9% increase.
These results are changing how experts think about building better AI models. Instead of putting efforts into making models bigger or more complicated, many are now rethinking their data strategy.
For businesses adopting AI, a strong foundation in data handling is essential for success. This means ensuring data is always available, secure and compliant with privacy laws like GDPR, accurate and reliable, scalable as the business grows, and capable of driving innovation.
Clean, well-labeled data plays a huge role here. That’s where data annotation comes in. It is the process by which experts tag images, text, or other inputs so the AI models can learn correctly.
Many in the AI community, as well as experts like Andrew Ng, agree that a data-centric approach to AI development is the better option. He also said that “Data is food for AI”, so better data results in a healthier AI system.
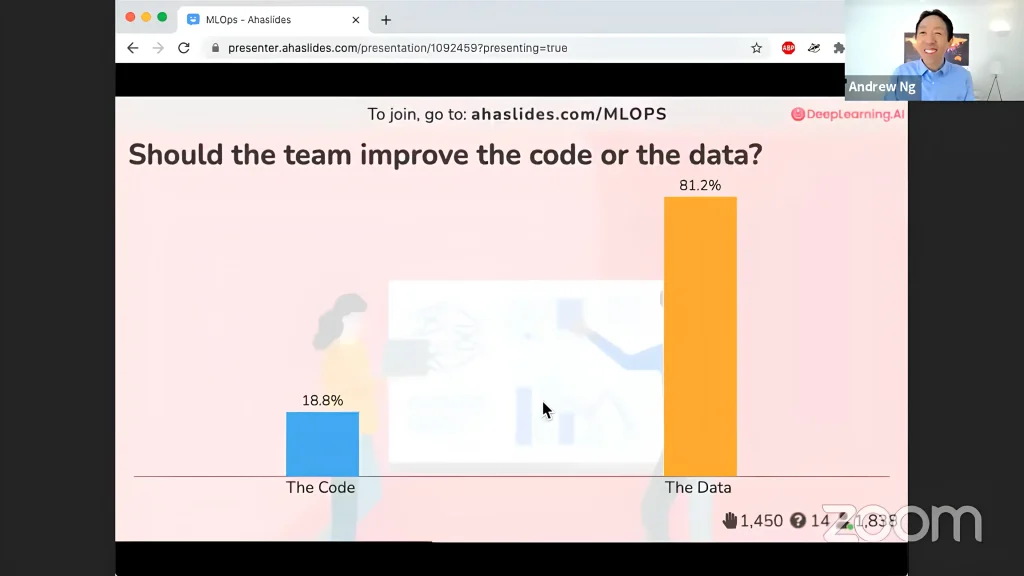
Andrew Ng’s Live Poll: Improve Models or Data? Data Wins. (Source)
At Objectways, we’re here to make your AI journey easier – no need to fight the AI war. Our team specializes in high-quality data annotation to power accurate, reliable models. Whether you need a few hundred labels or millions, we’ll work closely with you to deliver exactly what your project needs.
In the race to build better AI models, it’s becoming clear that scaling up doesn’t always mean smarter and reliable. While model-centric approaches focus on making changes to the model itself, they often bring high costs and limited improvements.
On the other hand, a data-centric approach, which is driven by clean, accurate, and diverse data, can lead to more reliable, efficient, and fair AI systems. The AI war makes one thing clear: the future of smarter, more reliable systems lies not in building bigger models, but in building better data.
At Objectways, we’ve got the people, tools, and expertise to give your AI model the quality data it deserves. Ready to get started? Let’s connect and talk about your AI vision.
Data is the information used to train an AI model, while a model is a system that learns from that data to make predictions or decisions. AI models are dependent on high-quality data.

See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.
