At its core, computer vision is a branch of artificial intelligence that teaches machines to understand the world through images and video. Even though it may sound like something out of a science fiction movie, computer vision is already part of our daily lives. In 2024, computer vision systems made up a $20.9 billion market, and by 2034, that number is expected to climb to $111.3 billion.
Self-driving cars use it to recognize obstacles on the road, while augmented reality apps let shoppers preview furniture in their homes. Similarly, hospitals rely on it for early disease detection, and manufacturers use it to catch defects and improve efficiency. Its reach is continuing to scale, and it is reshaping a wide range of industries.
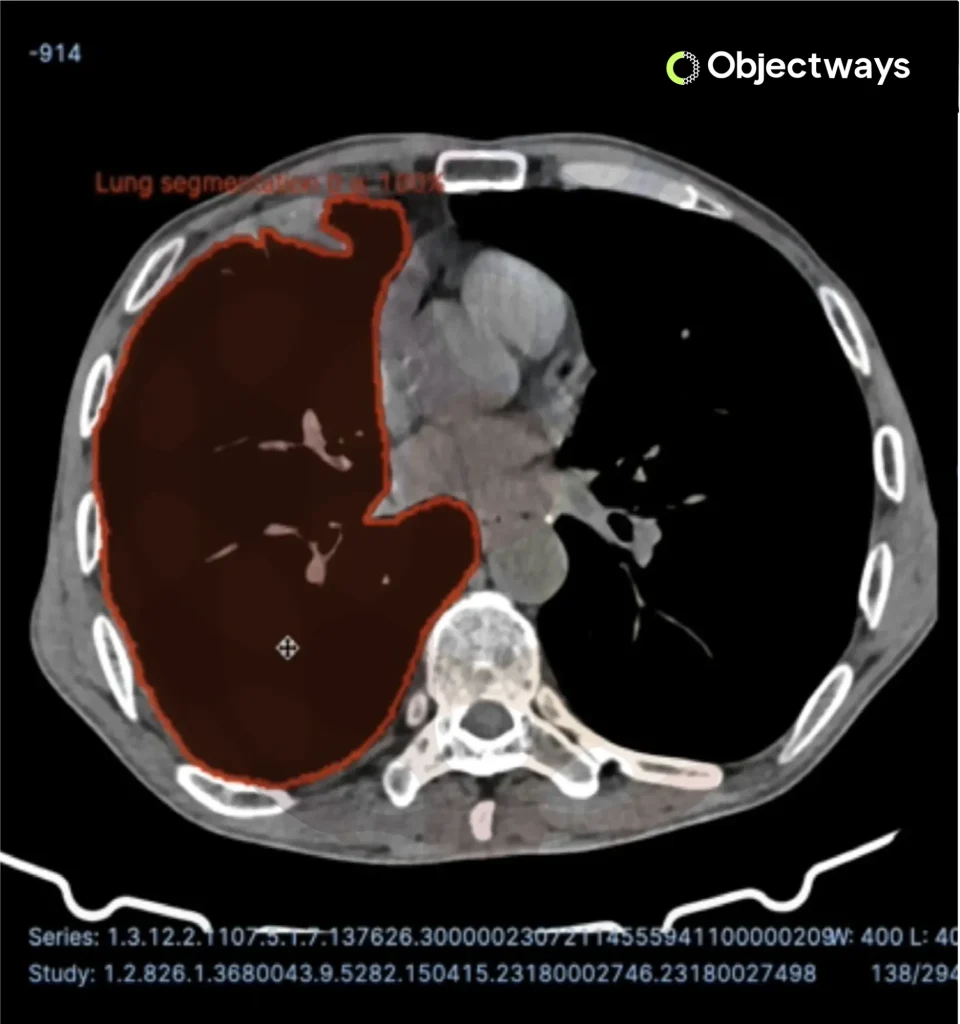
Using Computer Vision to Detect Brain Tumors
In this article, we’ll explore the top computer vision trends shaping 2025, from faster edge-optimized AI to the growing importance of ethical and explainable systems. Let’s get started!
Before we dive into the trends, let’s take a quick look at computer vision for beginners and how a typical solution works.
At its simplest, computer vision is about teaching machines to see. A system takes in images or video and processes them so it can recognize and interpret what is there. For example, when shown a picture of a cat, the system does not immediately know it is a cat. Instead, it learns to identify features such as edges, shapes, textures, and colors, then combines those clues to make a prediction.
Most computer vision pipelines begin with preprocessing. This step cleans up the input by resizing images, reducing noise, or adjusting brightness and contrast so the data is easier for the system to work with.
Next comes pattern detection. A deep learning model, often a Convolutional Neural Network, starts by picking up simple features like edges and corners. As the data moves through more layers, these details are combined into textures and shapes.
By the end, the model can recognize complete objects such as cars, buses, or pedestrians. To perform well in the real world, the model needs to be trained on a large amount of high-quality data so it can tell patterns apart with accuracy.
When you explore computer vision for beginner guides, you will usually come across machine learning topics as well. Machine learning is a branch of artificial intelligence that focuses on teaching computers to learn from data and improve over time without being explicitly programmed.
It is a key part of computer vision because it gives computers the ability to learn from data instead of relying only on fixed rules. You could say that machine learning is a large umbrella, with computer vision as one of the fields that sits beneath it.
Tutorials on computer vision for beginners usually start by explaining the main tasks that make the technology useful. Each task focuses on a different way of interpreting images and videos, such as identifying objects, analyzing body movements, or recognizing facial features. Together, these tasks give machines the ability to understand and interact with the visual world.
Here are some computer vision tasks that are commonly used in the real world:

Key body points can be identified using pose estimation. (Source)
Now that we have a better understanding of what computer vision is and how it works, let’s explore the top computer vision trends shaping 2025 and how they are influencing real-world applications.
Processing large volumes of images and videos in real-time can be slow and costly if all the data has to travel to the cloud first. This delay can be a major problem for applications that need instant insights, like monitoring traffic intersections or managing industrial machinery.
Edge-optimized vision AI solves this by running computer vision models directly on devices such as cameras, drones, or embedded systems. Think of it as giving a device its own mini brain that can analyze visual data right where it’s generated, without waiting for the cloud. This means faster results, lower network costs, and improved privacy, as sensitive data remains on the device.
Let’s say there’s a smart camera at a busy traffic intersection. Instead of sending all its footage to the cloud, the camera processes video on the spot.
This means it can instantly detect cars, track their speed, and even notice when a vehicle runs a red light. Only the essential information gets sent to city systems, which keeps traffic flowing smoothly and saves bandwidth.
Traditionally, computer vision has depended on supervised learning, which means every image in a dataset has to be labeled with the correct answer, like the name of an object or its category. This works well for tasks such as image classification, object detection, and facial recognition. But when there isn’t enough labeled data, the approach quickly runs into limits.
Another factor is that in many industries, data collection and annotation for AI projects can be slow, expensive, and complicated. In healthcare or manufacturing, for example, manually labeling thousands of images can take weeks or even months, delaying projects and increasing costs.
To overcome this challenge, newer approaches are being used. Here’s a look at a couple of them:
Interestingly, researchers are also looking into combining these two methods. A recent study used self-supervised learning and unsupervised learning for defect detection in manufacturing.
Models are first pretrained on normal product images, teaching them what a good product looks like without manual labels. After that, unsupervised learning is used for anomaly detection, spotting irregularities such as scratches or misalignments by identifying deviations from normal patterns.
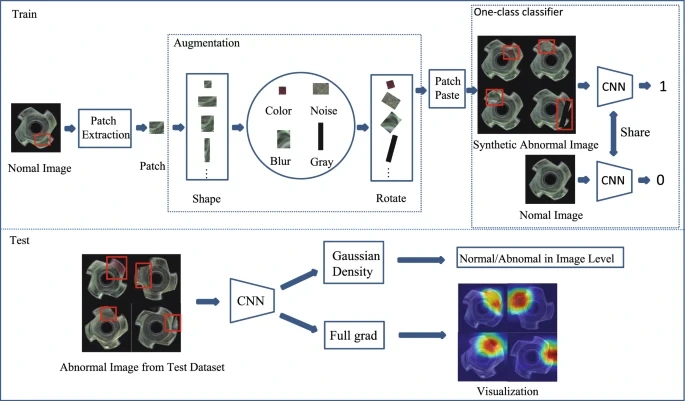
Self-Supervised Pretraining Combined with Unsupervised Anomaly Detection. (Source)
Cutting-edge AI systems often need to process different types of information at the same time. An image might show what something looks like, but the description tells you how it is used. Consider a product photo that displays a pair of running shoes, while the text explains the size, brand, and purpose. AI systems that can only see or only read may miss the full meaning.
Multimodal AI bridges this gap by combining computer vision, which lets machines see and interpret images, with natural language processing, which lets them understand text. Together, these capabilities enable AI systems to recognize objects in an image, understand the surrounding text, and answer questions about it.
Autonomous driving is a good example of multimodal AI in action. Waymo’s EMMA (End-to-End Multimodal Agent), built on Google’s Gemini model, uses a single multimodal model to process camera feeds, maps, and contextual information together.
This integration allows the system to interpret unusual situations more effectively. For instance, if there’s a construction zone or an unexpected obstacle, EMMA can combine what it sees with its understanding of real-world driving scenarios to make smarter decisions.
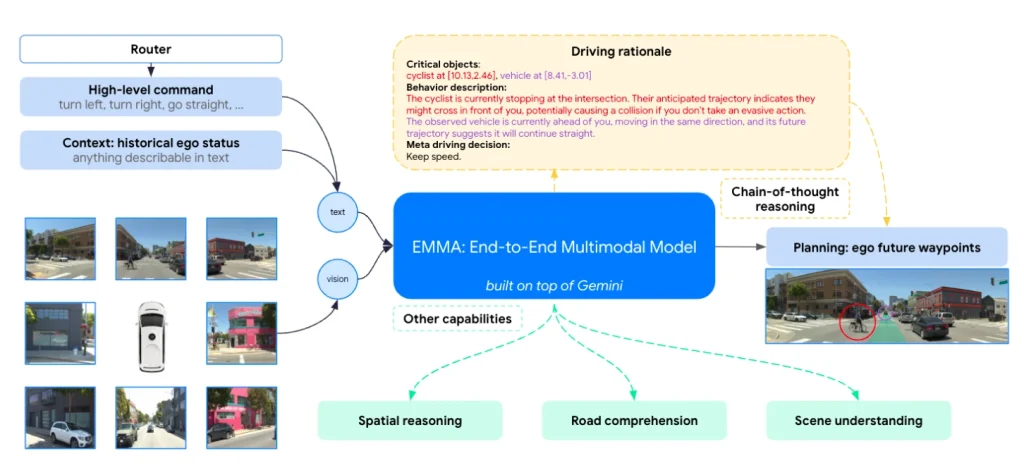
Waymo’s EMMA Fuses Multimodal AI and NLP for Safer Driving. (Source)
When you walk into a room, you immediately understand where objects are, how far away they might be, and how to move around them. For robots and AI systems, this kind of spatial awareness is much more complex. The world is constantly changing as objects shift, people move, and environments evolve in ways that a single snapshot can’t capture.
Without strong spatial understanding, a robot would struggle to navigate safely, handle objects, or interact with its surroundings in meaningful ways. This challenge has made spatial reasoning an important trend in computer vision and robotics.
To close this gap, AI systems rely on advanced technologies. LiDAR measures exact distances, depth cameras create real-time maps of the environment, and neural rendering methods such as NeRFs can transform ordinary two-dimensional images into realistic three-dimensional scenes. These approaches give robots the ability to see, interpret, and respond to the world around them.
An interesting example is Microsoft’s MindJourney framework. It combines a vision–language model with a world model to simulate navigating through a space. By following guided paths, the AI model can answer questions about the environment, reason about spatial relationships, and anticipate how objects and spaces interact.
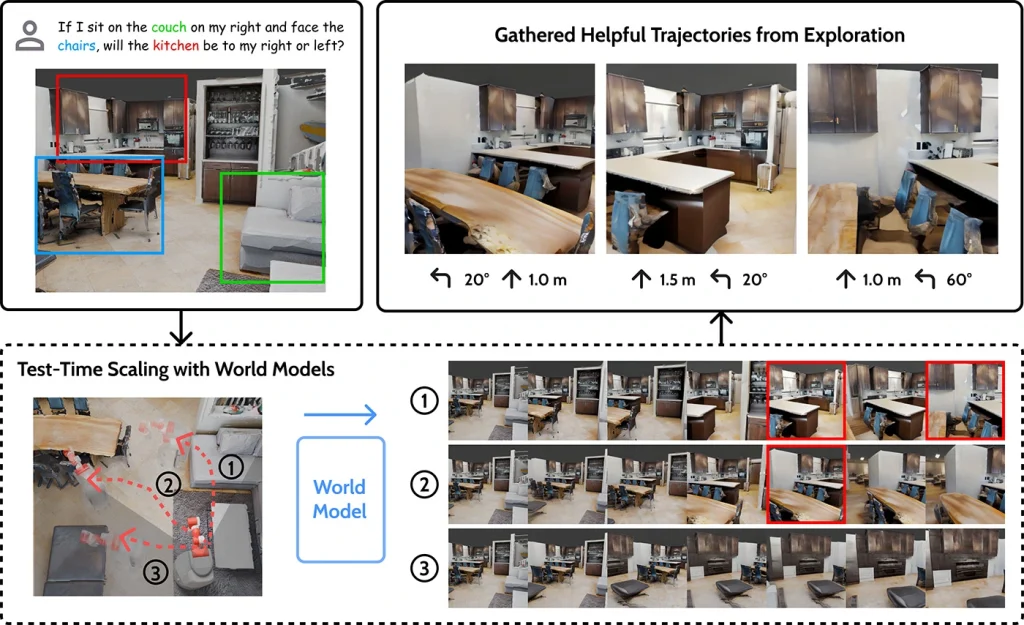
MindJourney Trains AI Models Using Simulated 3D Environments to Improve Spatial Reasoning. (Source)
In particular, this year we’re seeing computer vision show up in robotics more than ever. A big milestone has been Google DeepMind’s Gemini Robotics and Gemini Robotics-ER, which give robots the ability to actually see, understand, and interact with the world around them. From recognizing objects in 3D to planning how to pick them up or move through a space, these systems are a major step toward robots that can work alongside us in everyday environments.
Regardless of how advanced AI becomes, we cannot say it is truly improving everyday life if we do not understand the reasons behind its decisions. Picture a doctor looking at an AI scan that marks a tumor as positive. Without knowing how the AI reached that result, the doctor would find it hard to trust.
This is why explainability matters. In areas like healthcare, finance, and security, decisions affect real people in serious ways, and blind trust in a system is not enough.
The need for transparency has led to the development of explainable AI models, which reveal the reasoning behind predictions. Grad-CAM, LIME, and SHAP are examples of such models.
Grad-CAM highlights the regions of an image that most influenced a prediction, LIME analyzes how small changes in input affect the outcome, and SHAP assigns contribution scores to different features. These methods help users understand whether the AI model is focusing on meaningful patterns or being misled by noise, turning complex outputs into insights that are easier to trust.
A recent study showcased how such tools are being applied in healthcare. Heatmaps from Grad-CAM, LIME, and SHAP were used to support doctors in detecting pneumonia from chest X-rays and identifying breast cancer in mammograms. By comparing AI reasoning with medical evidence, doctors can confirm whether an AI system is helping or making mistakes.
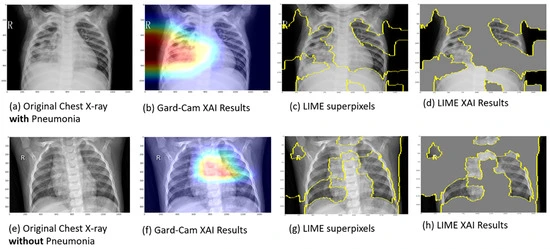
An Example of Explainable AI in Pneumonia Detection from Chest X-rays (Source)
Beyond these five major trends, there are other emerging developments in computer vision that are driving innovation across industries.
Here’s a look at a few other noteworthy computer vision trends:
AI is a field that is constantly evolving, with new breakthroughs and applications emerging every year. At Objectways, we help teams stay ahead of computer vision trends by providing high-quality data annotation and labeling services. Our expertise ensures your AI models are accurate, reliable, and ready for the latest vision technologies.
Computer vision is reimagining industries such as healthcare and finance. Trends such as explainable AI and self-supervised learning are making systems more accurate, fair, and trustworthy. By combining these advances with thoughtful application, computer vision can support better decisions, improve efficiency, and make everyday experiences smoother for people.
Even the most advanced models depend on reliable data. At Objectways, we transform raw visual inputs into production-ready AI training datasets. Our team delivers precise labeling and domain-specific annotations, ensuring your computer vision models learn from the right signals and perform reliably in the real world.
Smarter AI starts with smarter data. Book a call with us to power your next computer vision project with datasets you can trust.
The leading trends are Vision Transformers (ViTs), which improve image recognition by analyzing images in patches, multimodal AI that combines visual and text data for richer insights, and explainable AI (XAI), which makes model decisions more transparent and fair.


Learn how computer vision for quality inspection helps detect defects, improve product accuracy, and maintain quality control in production lines.

Learn how computer vision in transportation enhances safety, efficiency, and sustainability through real-time traffic insights and smart mobility systems.
