Large language models (LLMs) like OpenAI’s GPT models and Anthropic’s Claude models are now part of everyday enterprise workflows, used for drafting documents, analyzing data, and supporting decision-making. In fact, Gartner predicts that this year, more than 80% of enterprises will use generative AI APIs or deploy LLM-enabled applications in production.
However, as these systems move into real-world enterprise applications, a pattern is emerging. LLMs perform well on general tasks but struggle in specialized environments that require domain-specific terminology, structured workflows, and regulatory awareness.
For example, in healthcare, summarizing a clinical note isn’t just a language task. It requires understanding medical terminology, patient history, and context that general models often miss or misinterpret.
Transfer learning is an AI technique that helps provide this missing context. It makes it possible for development teams to adapt and fine-tune pre-trained models using domain-specific data so they perform more accurately in real-world scenarios.
For the healthcare use case, this means training the model on clinical data to better understand medical language and generate more reliable summaries and insights. How well the model performs ultimately depends on the quality of that data, a factor that holds true across industries and use cases.
Let’s take a closer look at how transfer learning works in LLMs and why data is central to its success.
Transfer learning in LLMs is becoming a practical way for teams to close the gap between general models and real-world use cases. Instead of building models from scratch, most teams are starting with a foundation model and adapting it using domain-specific data.
At a high level, this process builds on two stages. During pre-training, models learn broad language patterns from large and diverse datasets. Fine-tuning then narrows that knowledge, helping the model adapt to the terminology, structure, and context of a specific domain.
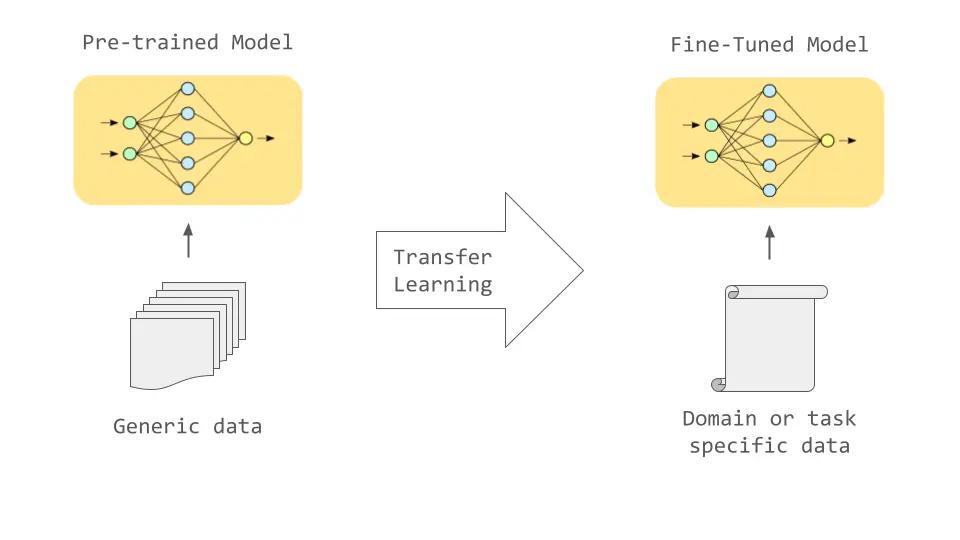
Transfer Learning in LLMs Enables Domain-Specific Model Performance (Source)
You might be wondering why transfer learning is becoming so important for LLMs.
What we are seeing is that general-purpose models rarely perform consistently in specialized environments on their own. They may generate fluent responses, but still miss important context, misinterpret domain-specific terms, or produce outputs that don’t align with real workflows.
Transfer learning aligns models more closely with the data they are expected to operate on. By refining models with targeted, domain-specific datasets, teams can improve accuracy, consistency, and relevance across tasks.
At the same time, this approach also makes large-scale AI development more practical. Instead of retraining entire models, teams can build on existing foundations, reducing both development time and computational overhead.
Adapting LLMs today is less about building models and more about choosing the right starting point and refining it with the right data. Here’s how that process typically works:
As you explore transfer learning, you might come across domain adaptation, and at first glance, the two can look very similar.
However, they solve different problems. Transfer learning focuses on adapting a model to perform new tasks using what it has already learned, while domain adaptation focuses on enabling a model to handle changes in data, even when the task itself stays the same.
For example, if a general model is adapted to summarize clinical notes, that is transfer learning. But if that same model is adjusted to handle differences in clinical data across hospitals, formats, or patient populations, that is domain adaptation.
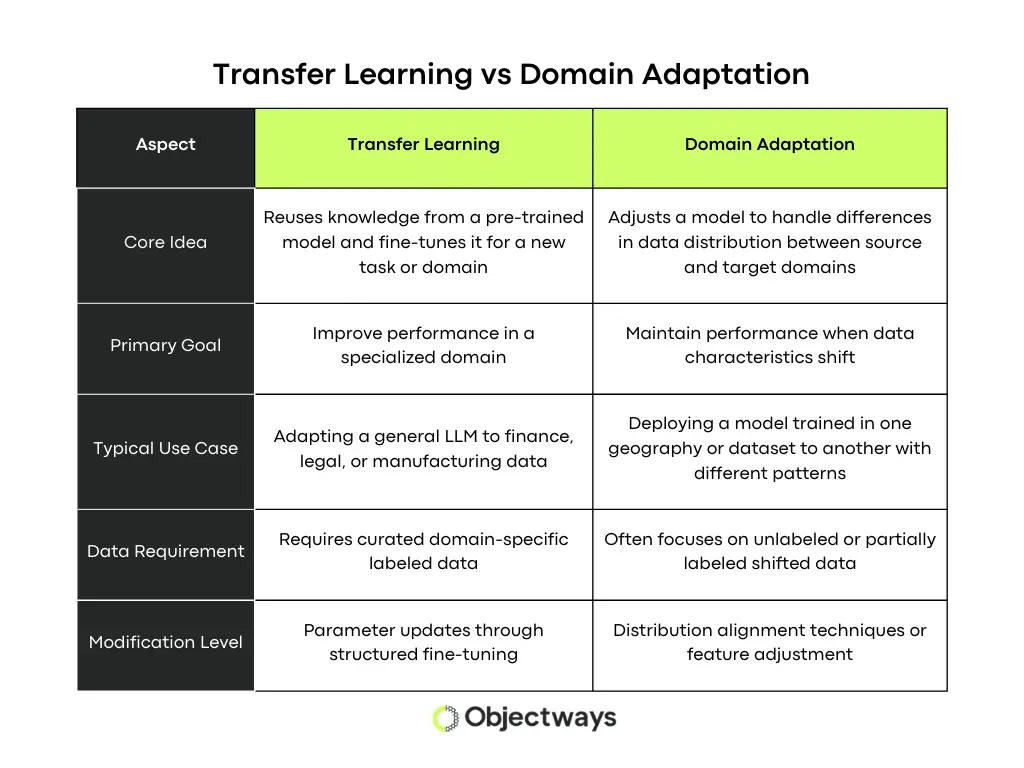
A Look at Domain Adaptation Vs Transfer Learning
You can think of it this way. Transfer learning is the step where a general model is adapted to a specific domain using domain-specific training data. Domain adaptation comes after that, when the goal is to make that model work consistently across different but similar data environments.
Based on which stage you are at, how you prepare your data and what data needs to be collected and annotated changes. Transfer learning often requires new, domain-specific datasets, while domain adaptation focuses more on capturing variations in existing data.
As organizations move LLMs from experimentation into production, transfer learning is becoming a crucial enabler for solving domain-specific challenges. From document analysis to decision support and workflow automation, its impact is already visible across industries.
When it comes to AI in healthcare, the challenge isn’t a lack of data, but making sense of it. Clinical notes, diagnostic reports, and patient records are generated at scale, yet most of this information is unstructured and difficult to use in real-time.
General-purpose models simply aren’t enough in these scenarios. Medical language is highly specialized, and even small gaps in understanding can lead to unreliable outputs. This is where transfer learning becomes critical.
By adapting models with clinical data, teams can align LLMs with the terminology, structure, and context of healthcare workflows. More reliable systems that can support clinicians without adding to their workload can be built.
LLMs like Google’s Med-PaLM 2 reflect this shift. It is a medical language model created by adapting a general-purpose model using medical-specific datasets and expert instruction tuning. The model is designed to support tasks such as answering clinical questions, summarizing medical reports, and assisting physicians in reviewing patient information.
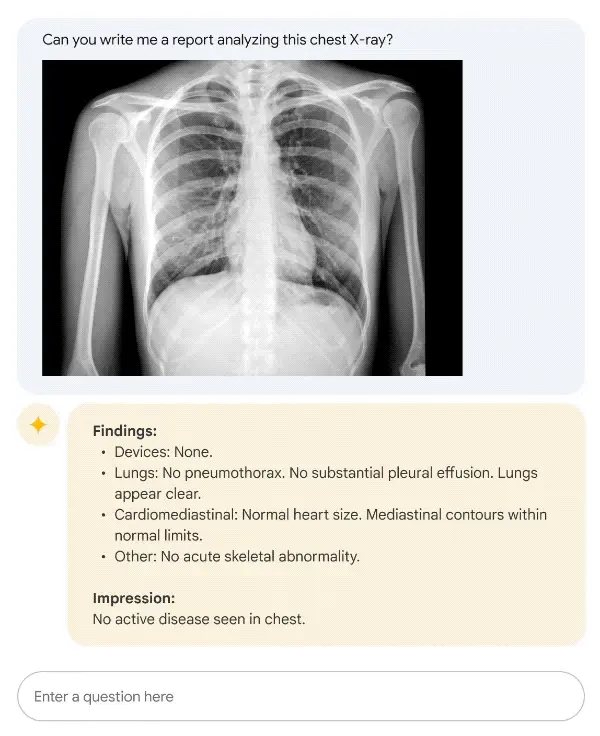
An Example of Google Med PaLM 2 Generating Clinical Reports from X-rays (Source)
Similar to healthcare, finance and legal workflows operate in environments where accuracy isn’t optional. Small misinterpretations in contracts, regulatory filings, or market reports can quickly translate into real risk.
In other words, the fluency of general-purpose models alone isn’t enough. What matters is whether the model understands the structure, intent, and constraints behind the data it is working with.
For instance, BloombergGPT is a 50-billion-parameter language model designed for financial analytics and market intelligence. The model is based on the BLOOM architecture and was trained on FINPILE, a large financial dataset that includes Bloomberg news, filings, market data, and research reports.

Using BloombergGPT to Generate Short Headline Suggestions. (Source)
This lets BloombergGPT interpret financial language, generate insights from market data, and support tasks such as financial analysis and document processing. Fine-tuned LLMs like this help teams improve efficiency, reduce manual effort, and make faster, data-driven decisions.
Moving away from fields that require precision due to high risk, transfer learning in LLMs is still just as relevant in other sectors. Consider customer support environments.
Here, the challenge is less about regulatory accuracy and more about scale, consistency, and understanding context. Teams need to handle large volumes of queries, service tickets, invoices, and internal documents while staying aligned with company policies and workflows.
General-purpose models can assist with responses, but without domain alignment, they often miss intent, misinterpret queries, or provide inconsistent answers. That’s why adapting models with domain-specific data makes a difference.
For example, models like CS-BERT build on general language models by further training them on customer service conversations. This allows them to better understand intent, context, and patterns specific to support interactions.
CS-BERT Enabling Intelligent Enterprise Support Automation (Source)
When models are trained on real support data, they become more effective at handling recurring queries, automating workflows, and improving response quality. The result is faster support and more consistent, reliable customer experiences.
As teams move from development to production, the value of transfer learning becomes more apparent. It’s a practical way to make LLMs usable in real enterprise environments.
One of the biggest additional advantages is speed. Instead of building models from scratch, teams can start with existing foundations and focus on adapting them. This significantly shortens development cycles and accelerates time to deployment.
There is also a clear impact on cost. Training large models end-to-end is resource-intensive, but adapting pre-trained models requires far less computational effort, making it more accessible for enterprise teams.
While the benefits of transfer learning are clear, getting it right isn’t always straightforward. As teams start working with LLMs, a different set of challenges begins to surface.
The first is data. Model performance is directly tied to the quality of the data it is trained on. Domain-specific datasets need to be accurate, well-structured, and representative of real workflows. Collecting and labeling this data takes time, effort, and often deep domain expertise.
Another challenge is maintaining balance within the model. As models are adapted to new domains, there is a risk of losing some of their general understanding. Without careful tuning, improvements in one area can lead to degradation in another.
There are also broader considerations around compliance and security. In regulated environments, how data is handled, validated, and used becomes just as important as model performance.
Addressing these challenges is less about the model and more about the data behind it. We have seen that organizations that prioritize data quality, annotation, and validation are the ones that succeed at scaling LLMs. At Objectways, this is exactly where we work with teams, helping them build the data foundation required for reliable AI systems.
Data collection, data annotation, and human-in-the-loop validation are the pillars that streamline transfer learning in LLMs. Without these in place, even well-designed models can struggle to perform reliably in real-world settings.
From what we have seen, the challenge isn’t just building the model, but making sure the data reflects the domain it is being applied to. This includes capturing the right terminology, workflows, and context so the model can generate accurate and consistent outputs.
This is where Objectways supports teams. We help with domain-specific data collection, high-quality data annotation, and human-in-the-loop validation to ensure models are trained on reliable, well-structured data. By combining these elements, organizations can build systems that are accurate and dependable in production environments.
As LLMs move into real-world applications, the focus shifts beyond model capability to how well those models are aligned with the domains they operate in. Transfer learning is a great technical option for aligning general models with domain-specific needs without starting from scratch.
By adapting foundation models with domain-specific data, organizations can build systems that are more useful, reliable, and relevant to their workflows. At the same time, model performance is shaped by the data behind it. Without strong data foundations and consistent validation, even well-adapted models can fall short in production.
From our experience, the teams that succeed are the ones that treat data as a core part of their AI strategy. If you are building LLM applications and need support with data collection, data annotation, or human-in-the-loop validation, reach out to us. We would love to talk.
Transfer learning in LLMs is a process of training a pre-trained language model to a specific domain by fine-tuning it with targeted datasets to improve accuracy and relevance for specialized tasks.


Explore how generative AI in procurement improves sourcing speed, reduces risk, and supports smarter, data-driven decisions across the lifecycle.
Generative AI in accounting is changing finance workflows with faster reporting and insights. Learn about the various applications, benefits, and risks.
