Most AI projects begin with collecting data, but that’s just the first step. Simply having data isn’t enough; it needs to be structured, cleaned, and made meaningful before it can power a successful AI model. For example, in computer vision, a branch of artificial intelligence that helps machines understand images and videos, data labeling involves clearly and consistently labeling the elements within each image.
This enables a Vision AI model to learn to recognize what it sees. This process is known as image annotation. When a photo is annotated, a specific area of pixels can turn into meaningful objects such as roads, vehicles, faces, or trees. Over time, a computer vision model can learn to recognize these visual patterns in a way similar to how children learn by seeing pictures alongside words that describe them.
Accurate labeling plays a crucial role in determining the performance of AI systems. In self-driving cars, for instance, annotated images help AI models learn to detect lanes, traffic signs, and pedestrians. Poor annotations can lead to missed details, inaccurate predictions, or inconsistent results.

An example of an annotated image. (Source)
As more industries rely on computer vision, the need for high-quality image annotation continues to grow. In fact, the global data annotation tools market is expected to reach $5.3 billion by 2030, reflecting the growing role of labeled data in AI development.
In this article, we will look at what image annotation is, how it works, and what to focus on when starting or scaling an image annotation workflow. Let’s get started!
Computer vision systems can’t understand images without guidance. They rely on labeled examples that clearly showcase what objects are present in an image, where they are located, and how they relate to one another.
You can think of image annotation as giving an AI model a set of visual flashcards. By labeling parts of images or video frames, it teaches the model what different objects look like and how to recognize them. Without these labeled examples, the AI model wouldn’t know what it’s looking at.
The AI capabilities made possible through computer vision and image annotation can redefine everyday life in fascinating ways. One good example is farmers using annotated drone imagery to detect crop stress, identify pest infestations, and monitor plant growth across large fields with precision.
Meanwhile, retailers can automate shelf audits by training AI models to recognize product placement, stock levels, and pricing accuracy. Similarly, in logistics, annotated warehouse images enable AI to track inventory, detect damaged goods, and optimize space utilization – all in real time.
As you learn more about image annotation, it may seem like a relatively straightforward task. So, why are high-quality labels so critical to a Vision AI project, and what factors are involved? The answer has to do with how much an AI model relies on accurate, consistent labeling to learn. Even small annotation errors can lead to confusion during model training.
Consider the example of teaching an object detection model to recognize birds. If one annotator includes the beak as part of the bird’s head while another labels it separately, the model receives conflicting information. Over time, it may misidentify birds entirely, sometimes basing its predictions on background elements like trees or the sky rather than the bird itself.
Beyond accuracy, other factors also play a key role: the clarity of annotation guidelines, the diversity and balance of the dataset, and the tools used to manage and apply labels. Poor annotation can also lead to biased results, such as facial recognition systems that struggle to accurately identify individuals from underrepresented groups.
In short, while image annotation might seem simple at first glance, it’s actually quite complex. It requires precision, consistency, and thoughtful planning to ensure AI models learn accurately and fairly from the data.
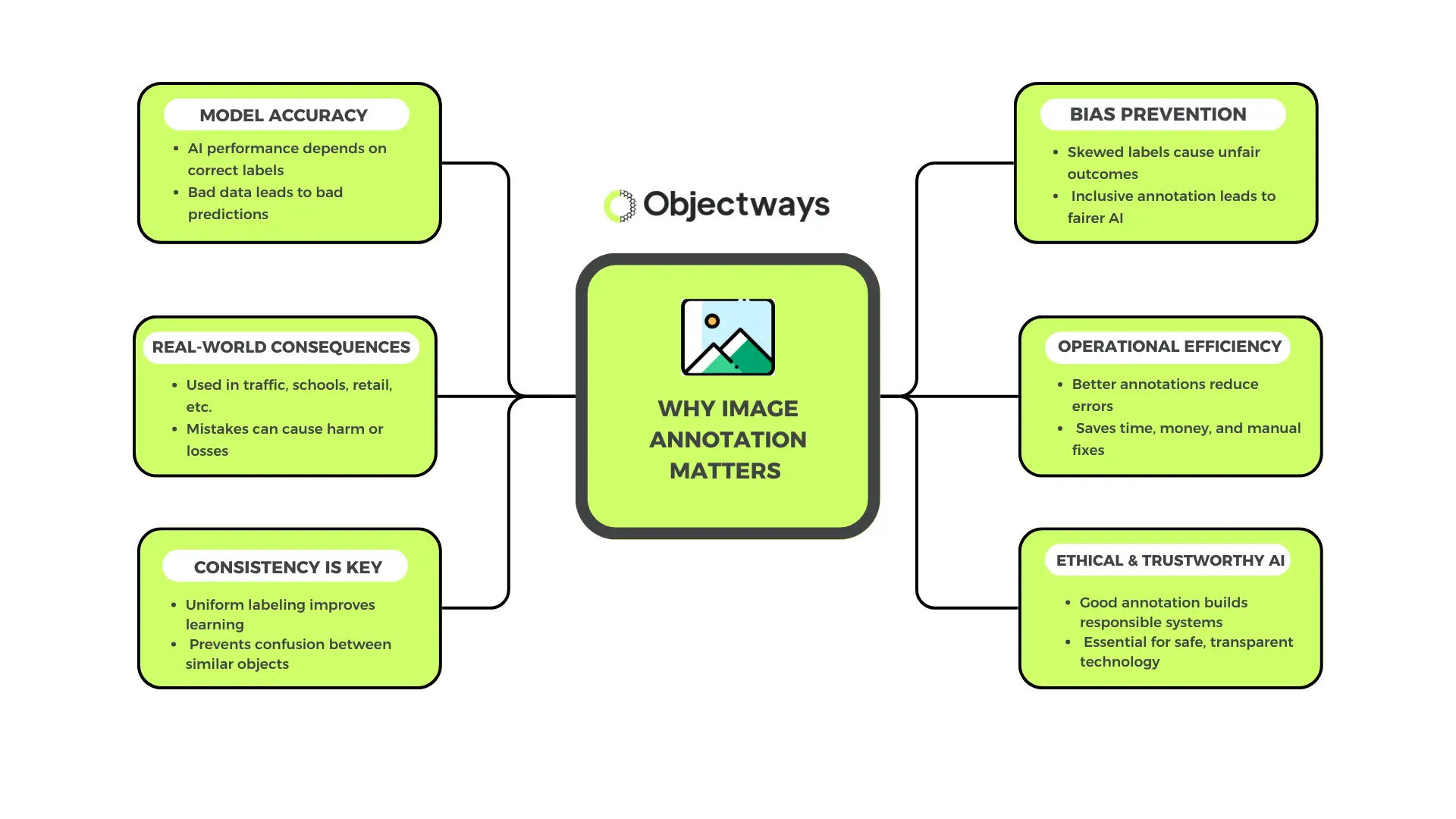
Why Image Annotation Matters
Now that we have a better understanding of what image annotation is and why it matters, let’s explore different types of annotations related to images.
Bounding boxes are one of the most widely used types of labels in image annotation. They’re created by drawing a rectangle around an object and adding a label to identify it. These boxes enable computer vision models to learn to recognize and locate objects, such as cars, people, animals, or tools, within an image.
This computer vision technique is known as object detection. It’s commonly used in areas like traffic monitoring, retail shelf tracking, security surveillance, and crowd analysis. For example, bounding boxes help self-driving cars identify other vehicles on the road, or spot pedestrians and obstacles in their path.
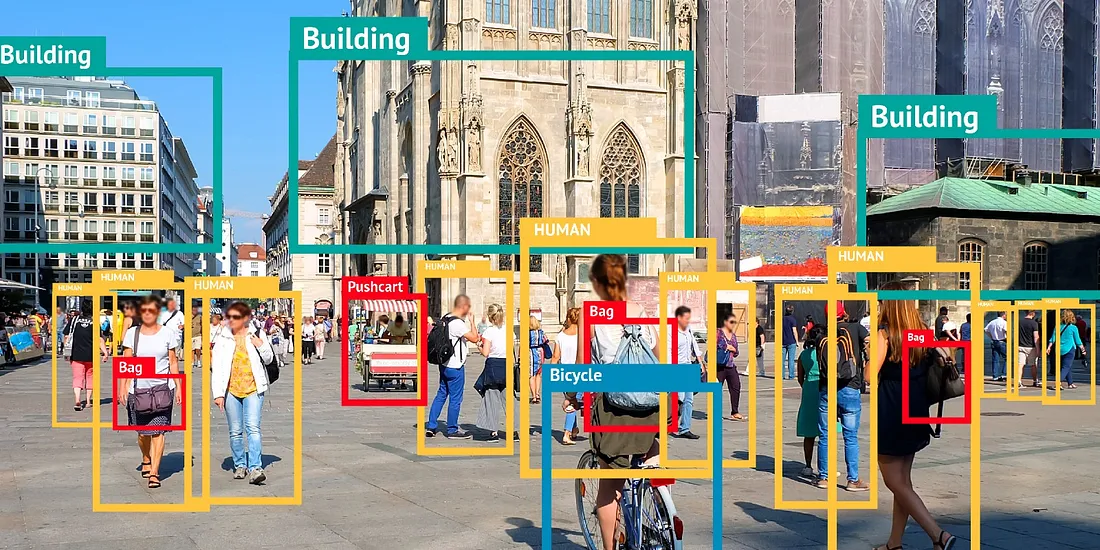
A Look at Object Detection and Its Use of Bounding Boxes (Source)
Polygons are ideal for labeling objects with complex or irregular shapes that a simple bounding box can’t capture accurately. Annotators can outline these objects by placing points along their edges, precisely tracing forms like road surfaces, lane areas, rooftops, or even fruit.
Splines build on polygons by providing a better way to outline objects with smooth, curved edges. Instead of straight lines, they use flowing curves between points to trace features like lane markings or road curves in autonomous driving. This results in smoother, more accurate outlines for continuous shapes. By capturing these details more precisely, splines help AI models better understand how objects and their shapes interact within a scene.
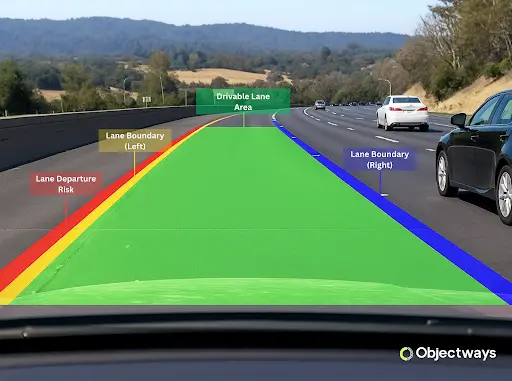
Annotating Curved Objects (Source)
Segmentation is used when a model needs to understand the whole shape of each object in an image. Instead of drawing a box around an object (which may include pixels that aren’t part of the object), the model is trained to identify every pixel within the object. There are two types of segmentation: semantic and instance. Both are typically represented using segments or masks that highlight the exact areas occupied by each object in the image.
Semantic segmentation labels similar objects the same, such as marking all cars or all people as one group, without telling individual entities apart. On the other hand, instance segmentation takes it a step further by labeling each object separately, so the system can tell how many there are and where each one is. This is especially useful in busy scenes like traffic, crowds, or stores.
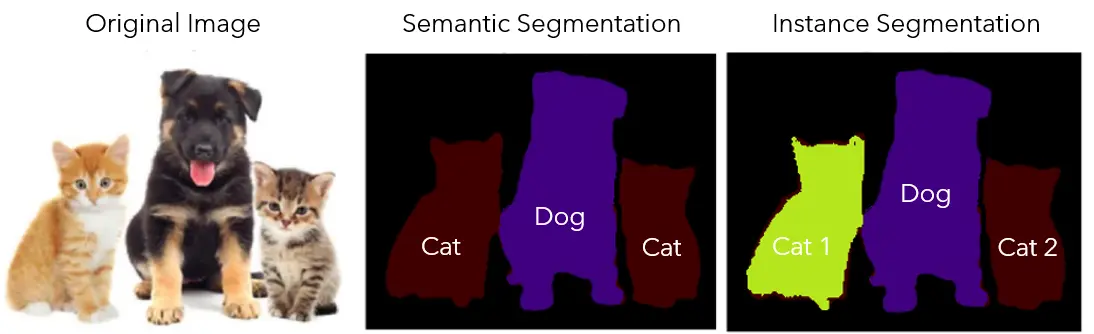
Semantic Segmentation Vs Instance Segmentation (Source)
Some computer vision tasks, such as facial recognition or pose estimation, focus on identifying specific points on an object rather than the whole object. Keypoint or landmark annotation is used to label features like eye corners, fingertips, joints, or facial outlines.
It is commonly used for applications like identity verification or gesture tracking. By marking specific spots, the model learns the arrangement and movement of body parts or facial features in relation to each other. This method can be used to detect expressions, track gestures, and follow motions like a head turn or raised hand smoothly over time.

Key points are an important part of pose estimation. (Source)
Image-level classification is used when the goal is to understand the overall scene or context of an image, rather than identifying individual objects. For instance, a satellite photo showing docks and boats might simply be labeled “Harbor” without marking each boat. Instead of detecting specific items like a “tree” or a “car,” the entire image could be tagged as “coastline,” “urban area,” or “flooded” based on its general content.
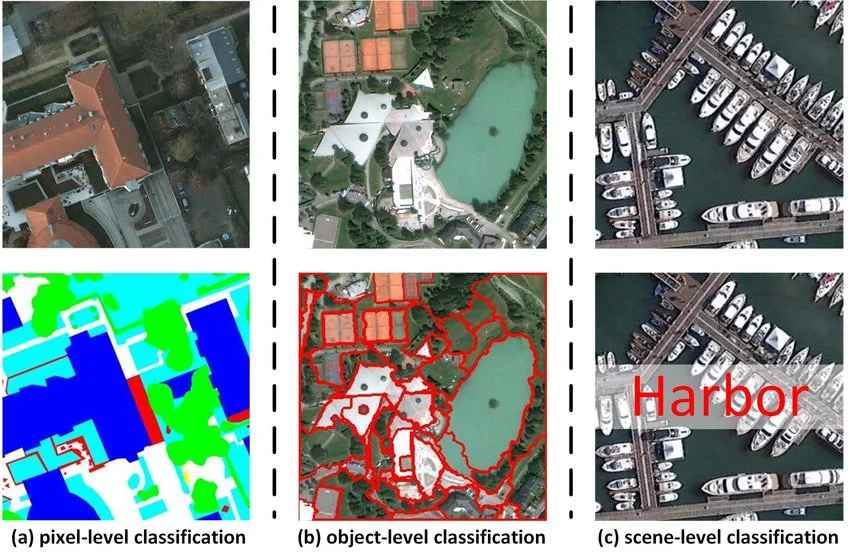
Examples of Annotated Satellite Images (Source)
This method is particularly useful for organizing large image collections, enabling quick scene detection, and supporting applications like remote sensing. It lets AI models classify images based on their setting, condition, or overall context.
Image-level labels are often used in large datasets because they are faster to generate when detailed object-level annotations aren’t required. While they lack fine-grained localization, they are great for high-level tasks such as image retrieval, scene recognition, and content moderation.
Not all visual data comes in the form of flat, two-dimensional (2D) images. In areas like robotics, drones, and autonomous driving, AI systems often work with three-dimensional (3D) data collected from various sensors. One of the most common sources of 3D data is LiDAR, which uses laser pulses to create detailed 3D point clouds of the surrounding environment.
Annotators label this 3D data by marking objects such as vehicles, pedestrians, traffic signs, or road boundaries using 3D bounding boxes or other spatial annotation techniques. Unlike 2D images, this data includes depth and distance, giving models a better understanding of real-world spaces.
Precise 3D annotations are especially critical in applications like autonomous driving, where AI solutions must make real-time decisions based on how close objects are, how fast they’re moving, and how they interact with the environment.
Now that we have explored the different types of image annotation, let’s discuss what the workflow of image annotation generally looks like.
The process begins with precise planning. Annotation teams first decide what the AI model needs to learn and find out which features are important to label. This step includes writing detailed instructions so everyone involved with labeling follows the same approach from the start.
Next, the right image labeling tool is chosen based on the type of data being used. Annotators receive training to apply labels with consistency, following project guidelines closely. Well-prepared teams reduce the risk of mistakes and improve the overall quality of the dataset.
Once labeling begins, the process is set up to handle scale efficiently. In large projects, it’s common to have multiple people working together, so the workflow is designed to keep things organized and consistent.
Quality checks are built into the process to review work, spot issues early, and ensure accuracy throughout. Before the dataset is finalized, a full review confirms if it meets the original goals and is ready to support reliable model training.
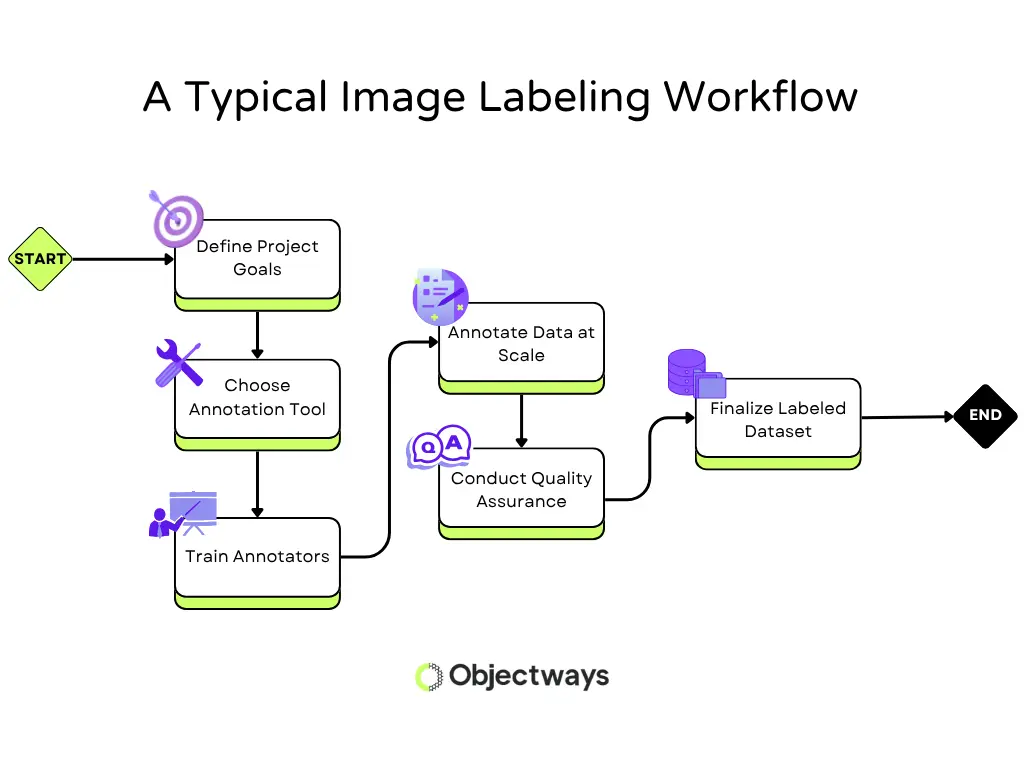
A Step-by-Step Workflow of the Image Labeling Process
Image labeling may appear easy on the surface, but several challenges can affect the progress and compromise the quality of your training data. Here are some of the limitations or factors to consider while labeling images:
Managing image labeling at scale can be a complex and intricate task. Accuracy, consistency, and speed all matter, and maintaining a balance among them becomes increasingly challenging as the dataset grows. That’s why many companies are turning to professional labeling services that can provide trained teams, reliable tools, and a workflow designed for quality.
Leading the way in data annotation, Objectways delivers scalable, high-quality labeling services tailored to your project’s needs. With expert teams and proven processes, Objectways helps AI developers focus on innovation – while ensuring their models are trained on reliable, well-annotated data.
Whether you need a few hundred labels or millions, scaling with confidence is easier with Objectways.
AI systems rely on labeled images to understand what they’re seeing. Whether it’s in retail, robotics, or any other industry, accurate image annotation is the difference between a model that works and one that almost works. As computer vision expands into more industries, the need for high-quality data grows with it.
Objectways brings the experience, tools, and trained teams you need to deliver labels you can trust. Whether you’re looking to improve your image labeling or build an AI solution, our team is here to help.
Ready to get started? Reach out to our team today to discuss your project needs.


Learn how computer vision in transportation enhances safety, efficiency, and sustainability through real-time traffic insights and smart mobility systems.
Explore how occlusion impacts computer vision, its challenges, and solutions like generative AI, multi-sensor fusion, and self-supervised learning.
