Despite the explosion of data around us nowadays, finding accurate information can still be strangely elusive. For instance, if you search online for wireless headphones, you might end up with results for Bluetooth speakers.
One of the reasons this happens is keyword-based search algorithms, where systems match exact words instead of understanding the actual intent. Most traditional search engines are still built on keyword matching, even if they layer on additional techniques to improve information retrieval.
While keyword matching handles basic lookups well, it falls short when people phrase queries in everyday language or use unstructured inputs like images and audio. To handle this, many systems have shifted to vector similarity search (VSS).
Vector similarity search is an advanced AI technique that converts data into vector representations (machine-readable numerical values) and compares them based on meaning to deliver results by focusing on contextual understanding rather than just keywords.
In this article, we will explore what vector similarity search is and how it works. Let’s get started!
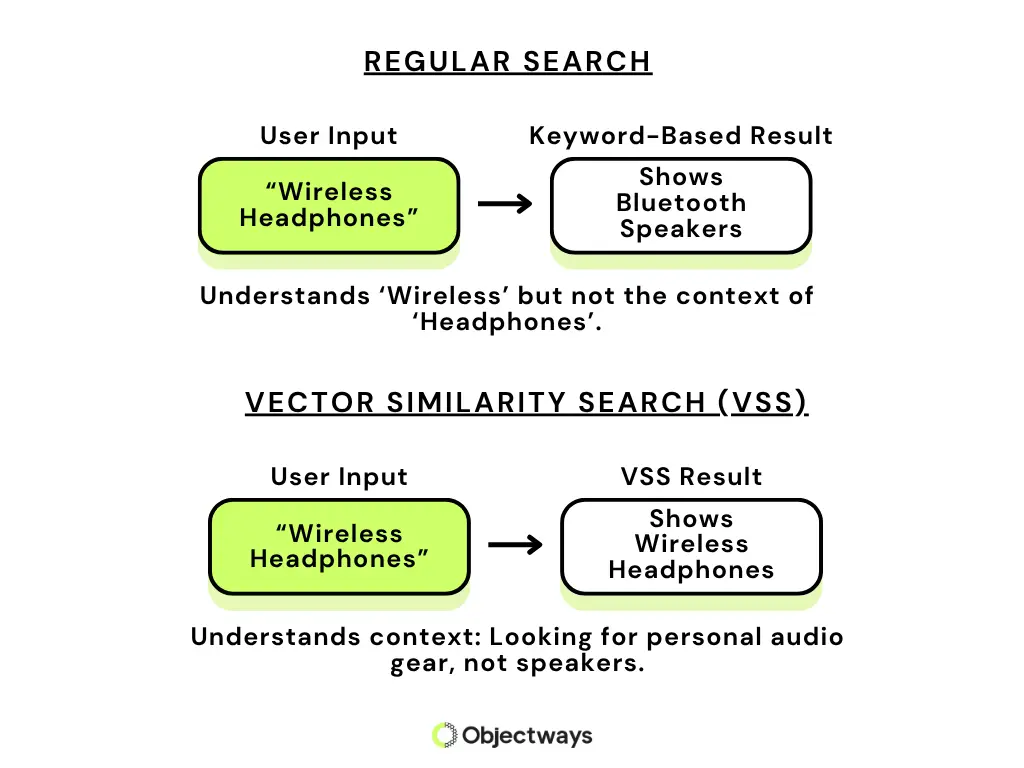
Traditional Search Engine Vs. Vector Similarity Search
What sets VSS apart is its ability to capture semantic relationships. These relationships reflect how closely concepts are connected in meaning, even if they use different words. For example, words like “teacher” and “school” have a semantic relationship because they are meaningfully connected. This helps AI systems link terms like wireless headphones and Bluetooth audio to deliver more accurate results.
From product suggestions on Amazon to content recommendations on YouTube, VSS is one of the key components powering many intelligent systems we use daily. These platforms use vector similarity search for information retrieval. By doing so, they provide relevant and personalized results for their users.
Before diving into vector similarity search and search algorithms, let’s take a closer look at the concept of vectors in AI.
Unlike humans, machines can’t understand language, images, or emotions. They simply find patterns in data. To bridge that gap, we can convert data into numbers (vector representation). A vector is simply an array of numbers that represents data, like text, images, or audio, in a machine-readable form. You can think of it as a unique numerical fingerprint that captures the meaning behind the data.
For example, the word “apple” might be represented as a vector like [0.29, 1.11, -0.2], while “mango” would have its own set of number values. These numbers aren’t random.
They’re generated using trained AI models that position semantically related data closer together in a vector space, where all data is represented as vectors. This transformation process is called embedding. It captures subtle patterns such as tone, context, and the similarity between pieces of data. The accuracy of these representations depends heavily on data integrity and high-quality labeling, which ensures that AI systems learn from reliable inputs.
An easy way to picture this is to imagine each data point as a dot on a giant invisible map. Data with similar meanings, like apple and fruit, appear closer on this map, while unrelated data like fish and apple are placed far apart. This spatial relationship enables AI to interpret meaning and make sense of information beyond literal terms for information retrieval.
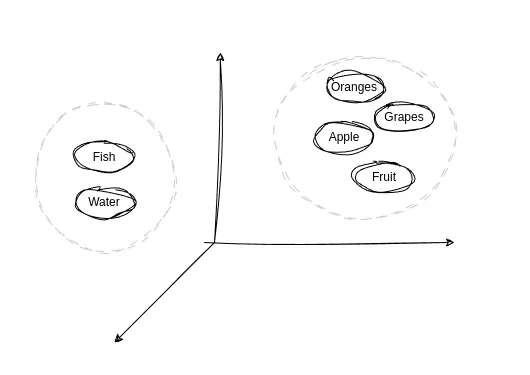
Word Vectors Grouped by Meaning in a Vector Space (Source)
Now that we’ve covered how vectors help machines understand data, let’s look at how vector similarity search uses that understanding to improve search accuracy and information retrieval.
Vector similarity search is an advanced AI search algorithm that finds similar items, not by exact word match, but through their meaning and closeness, using vectors. This approach differs significantly from the traditional keyword method, which relies on identifying exact phrases.
Take the example of searching for a comfortable reading chair. A traditional search engine will focus on those exact words, which means it might miss equally relevant results like a plush armchair or a cozy recliner, simply because the wording doesn’t match.
However, VSS does the opposite. It converts both your query and the database of possible results into high-dimensional vectors. Then it compares them numerically to find the closest matches in meaning. The closer the vectors, the more semantically related the results are. This process makes vector similarity search a crucial component for cutting-edge AI search systems, particularly those built with strong data pipelines.
Next, let’s get a better understanding of how VSS works. At its core, vector similarity search is a search algorithm and has one simple principle: take a user input and return the most relevant results based on meaning.
Here’s a step-by-step look at what happens behind the scenes during information retrieval:
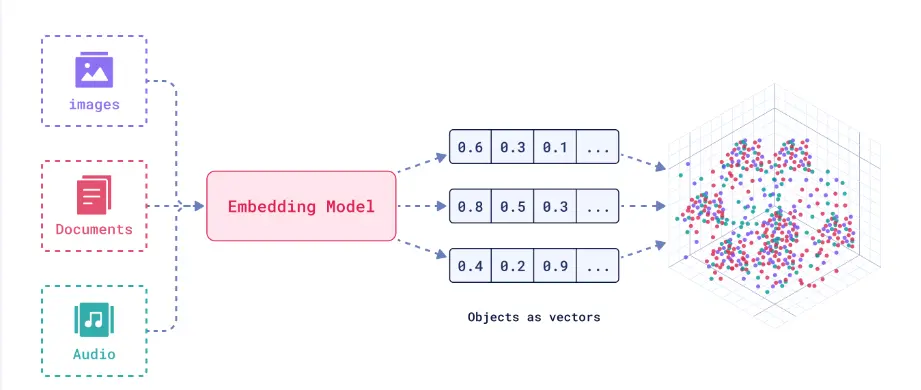
Turning Audio, Text, and Video into Vector Embeddings for Smarter Search (Source)
Once the data is in vector form, the next step is to compare those vectors. This is done through similarity metrics. They are mathematical formulas that measure the degree of similarity between two vectors in terms of context.
The dot product measures the alignment between two vectors. A higher value means the vectors point in a similar direction, which often indicates they have a similar meaning. This similarity metric is commonly used in recommendation systems, physics (for calculating work), and computer graphics (for lighting and shading effects).
Think of it like checking how closely two arrows align when shot from the same point of origin. If they point in the same or opposite directions, the score is high. If they shoot off at a right angle, the result is zero, implying no similarity.
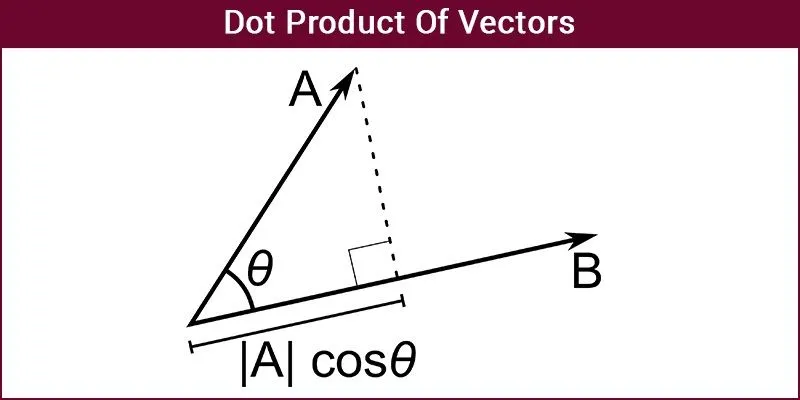
The Dot Product is Higher When Vectors Point in the Same Direction (Source)
Cosine similarity calculates the angle between two vectors, ignoring their magnitudes. It’s particularly useful for comparing documents, sentences, or user preferences. Even if two inputs use different words, cosine similarity captures their contextual closeness.
For example, if the vectors are aligned, it indicates a higher similarity. If they diverge, similarity drops, and if they point in opposite directions, their meanings conflict.
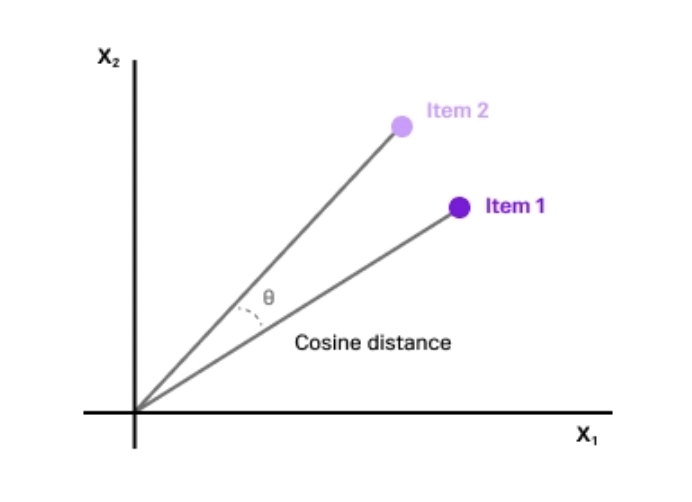
Cosine Similarity is Higher When Vectors are Closely Aligned (Source)
Euclidean distance calculates the straight-line distance between two vectors in a multi-dimensional space. It’s derived using the Pythagorean theorem and reflects the distance between two vectors in terms of their values. The smaller the distance, the more alike the items are. This metric is often used in image recognition, clustering, and scenarios where the actual spatial gap between data points is important.
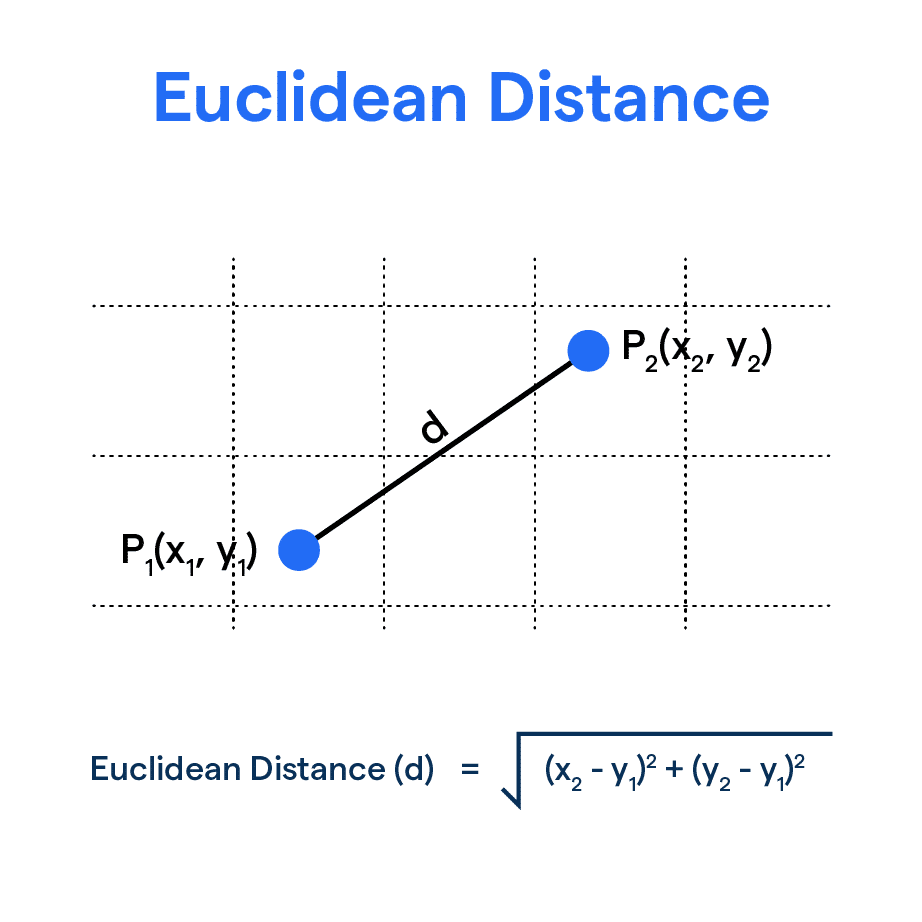
Euclidean Similarity is Higher When Vectors are Closer Together (Source)
Vector similarity search and related concepts like search algorithms may sound technical, but chances are you’ve used them in the past week without even realizing it. From online shopping to streaming platforms, here’s where information retrieval shows up:
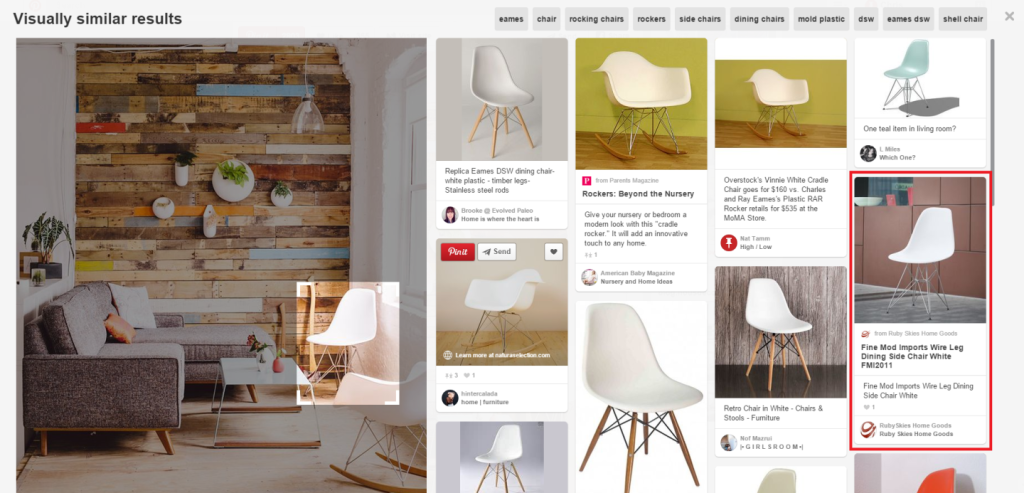
Pinterest Uses Visual Embeddings to Deliver Visually Similar Images (Source)
Here’s why vector similarity search is so useful for working with complex data:
Behind the consistent results, vector similarity search has technical complexities that need careful attention. From data representation to large‑scale processing, here are a few things to keep in mind.
The effectiveness of a vector search system depends on the quality of its vector embeddings. If the underlying model is outdated or poorly trained, it may fail to capture the true context of data, leading to weak or irrelevant information retrieval.
Another critical factor is the similarity metrics. Whether it’s dot product, cosine similarity, or Euclidean distance, the metric you select directly affects how search results are ranked. Using the wrong metric can push relevant results lower in the list, delivering mismatched or incorrect outputs to users.
VSS also requires scalable and high-performance infrastructure. Working with large volumes of vector data requires robust systems that are capable of handling both heavy computation and rapid retrieval speeds, especially as the scale grows. These challenges can make implementing such AI search algorithms seem overwhelming.
These challenges can make implementing information retrieval systems complex, and having the right expertise can make all the difference. At Objectways, we help teams develop AI solutions that rely on powerful algorithms, like vector similarity search. From raw text and images to domain-specific content, we specialise in preparing high-quality, structured datasets that support accurate and scalable information retrieval systems.
Vector similarity search makes it possible for information retrieval systems to deliver accurate results. But behind that smooth operation lies a data-driven, technical setup. Building AI solutions using such search algorithms means ensuring that your data pipelines, embeddings, and infrastructure all work in sync.
Whether you’re building a next-gen assistant or scaling an AI search engine, book a call with Objectways to explore scalable solutions.
Vector similarity search is an advanced AI technique that enables computers to find results based on meaning, rather than just exact words. It uses mathematical expressions to determine the degree of similarity between different items in a high-dimensional space.

Explore key classification metrics such as precision, recall, F1 score, and the calibration curve. Learn how to evaluate AI and machine learning models.

Learn about the difference between machine learning vs. deep learning vs. computer vision and how these technologies work together to build smarter AI systems.
