Typically, when you look at a picture, you see more than just objects. As humans, we notice how things relate. We can pick up on small details. We can sense the mood or tone of an image. A shadow, an expression, or the lighting can all hint at what just happened or what might happen next.
Now, what if you were trying to explain the picture you saw to someone over the phone? You might describe what is happening in the image and what it makes you feel. In that moment, you’re not just naming things. You’re connecting ideas, building context, and turning a single frame into a story.
Just like how you can turn a photo into a story with words, large vision models, also known as vision-language models or VLMs, can learn to translate images into language. Trained on vast datasets of images, videos, and text, these models can interpret visual scenes and answer questions about what they see.
VLMs are already being used to organize visual data, support people with visual impairments, and assist decision-making in areas that depend on images. In this article, we’ll look at how VLMs work and how they are reimagining the future through multimodal learning. Let’s get started!
Large vision models, or VLMs, are artificial intelligence (AI) models trained to understand visual information such as images, videos, and diagrams. These models learn from millions of examples and identify patterns, objects, and relationships in visual content. Instead of just recognizing what appears in an image, they also interpret context.
They combine image and language understanding in a single model to handle complex tasks. These models can describe a scene, answer a question about an image, or process a visual document along with its text. This ability to work across formats is known as multimodal learning.
Another way to think about a VLM is like a teacher explaining a diagram in class, pointing out the visuals and describing them so everyone can understand both the structure and meaning. Similarly, the model looks at both the visual elements and the text together, helping it develop a fuller understanding of the input.
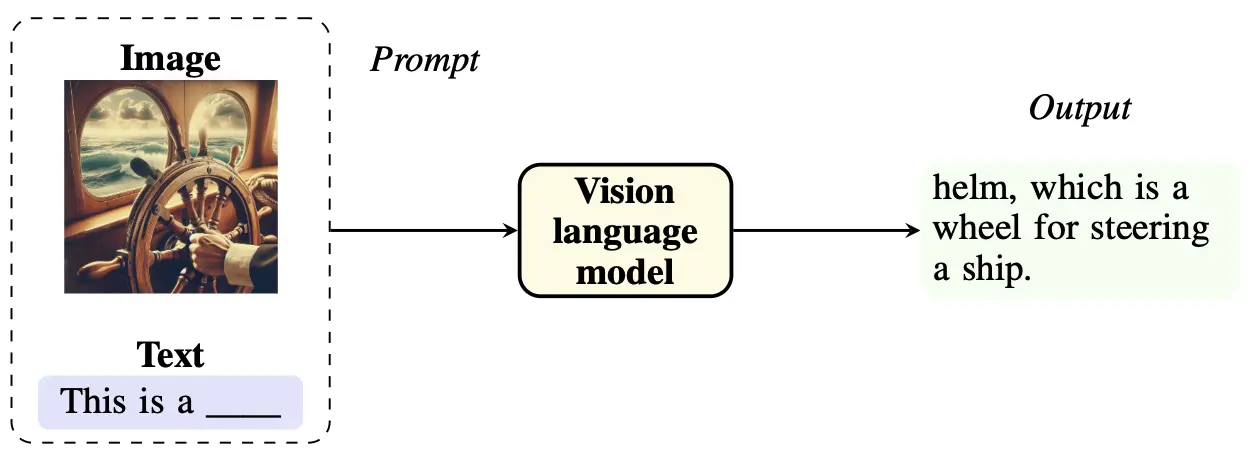
A vision-language model can understand both image and text input. (Source)
Vision-language models process images and text through a sequence of connected components. The process begins with a vision encoder, which takes in the image and converts it into a format the model can understand. This involves identifying patterns, objects, and relationships within the image.
The encoded visual data is then combined with language input using a fusion layer. This layer acts as a bridge, aligning visual features with corresponding words or phrases. By learning how these two types of information relate to each other, the model builds a shared understanding of the scene.
To improve accuracy, the model uses contrastive learning. It learns by matching images with their corresponding descriptions and distinguishing them from incorrect ones. This helps it respond more accurately to new examples.
The final step involves a language decoder, which takes this combined understanding and generates text. Depending on the task, the model might describe an image, answer a question, or explain what is happening in a visual scene. Each part of the system works together to ensure the output is both relevant and grounded in the input data.
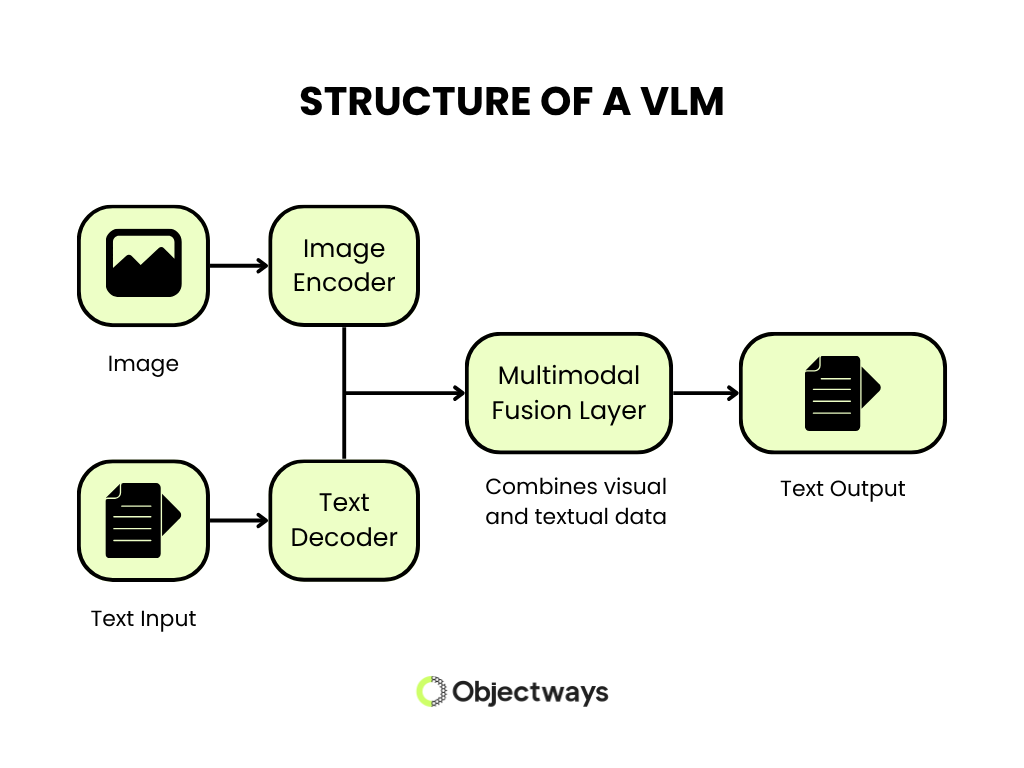
Structure and Working of a VLM (Source)
Large vision models are becoming popular because they reflect how people work with images and text together in everyday tasks. People read documents with visuals, browse images with short descriptions, and watch videos that include on-screen text. This mix of formats has created a need for systems that can process different types of inputs within a single model.
VLMs support this requirement by connecting visual input and natural language. They help systems read an image and respond in a way that includes both context and detail. For instance, vision encoders like Vision Transformers (ViT) can learn detailed patterns across large datasets, while advances in hardware have made training and deploying these models more efficient.
Architecture of a Vision Transformer (Source)
As a matter of fact, you can now find VLMs being integrated into everyday tools that label photos, help describe images for accessibility, and sort visual content easily. Enterprises are using them to process large image libraries, extract insights from documents, and build more adaptive AI systems.
These models also tend to work well even when there’s very little training data. In zero-shot and few-shot scenarios, they can take on new challenges without retraining. This makes them a practical option for teams working with limited resources or fast-changing requirements.
Vision-language models are constantly improving, and many are being recognized for their great performance across various multimodal tasks. Here are some of the most talked-about models and how they’re being used:
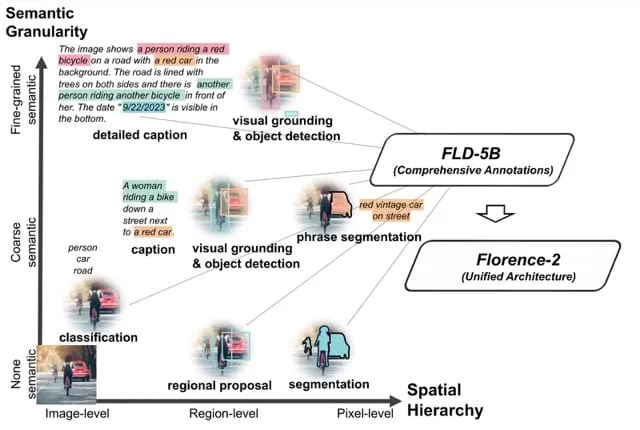
How Florence-2 Handles Different Types of Visual Tasks (Source)
Next, let’s take a look at some of the common ways large vision models are being used in different industries.
Image captioning focuses on using vision-language models to describe what is happening in an image. These models learn from large sets of image-text pairs and can recognize scenes, objects, and actions. A caption like “two people riding bicycles on a bridge” makes it easier to sort and search images in media libraries or personal photo apps.
E-commerce sites use this approach to label product photos for better indexing and discovery. Models such as Google Gemini 2.5 Pro and DeepMind Flamingo also support domain-specific captions, which help in fields like medical imaging or industrial inspection. For example, they can describe abnormalities in an X-ray or label parts in a machine assembly image with precision. This reduces manual effort in publishing and documentation workflows.
Similarly, in visual question answering, a model looks at an image and answers a related question. This goes beyond basic image recognition. It involves understanding relationships between objects.
For example, a VLM can answer questions like, “How many people are sitting at the table?” or “Is the person wearing a helmet?” These tasks support use cases in robotics, education, and document analysis. Also, in enterprise settings, these models can handle structured visual data to respond to layout-based questions from scanned forms or reports.

VLMs can handle visual question answering and reasoning tasks. (Source)
VLMs help improve accessibility by generating text descriptions of images for people with vision impairments. These models power screen readers and camera-based apps that describe scenes out loud.
For example, if a user points their camera at a scene, the system might say, “A dog is sitting on a couch” or “A person is standing at a bus stop.” This helps users understand the visual content around them. Automated alt-text generation is also being used in emails, websites, and digital learning tools to meet accessibility standards.
Visual search engines can use VLMs to match visual content based on similarity, style, or context. Instead of using text queries, users can upload an image to find visually similar items or related content.
Retail platforms are adopting VLMs for product discovery, allowing users to find clothing, furniture, or tools based on appearance. Apps like Pinterest Lens enable this by embedding both text and image into a shared space for retrieval. Likewise, recommendation engines can apply VLMs to suggest content with shared visual characteristics, supporting personalization in video platforms, e-learning systems, and digital media services.
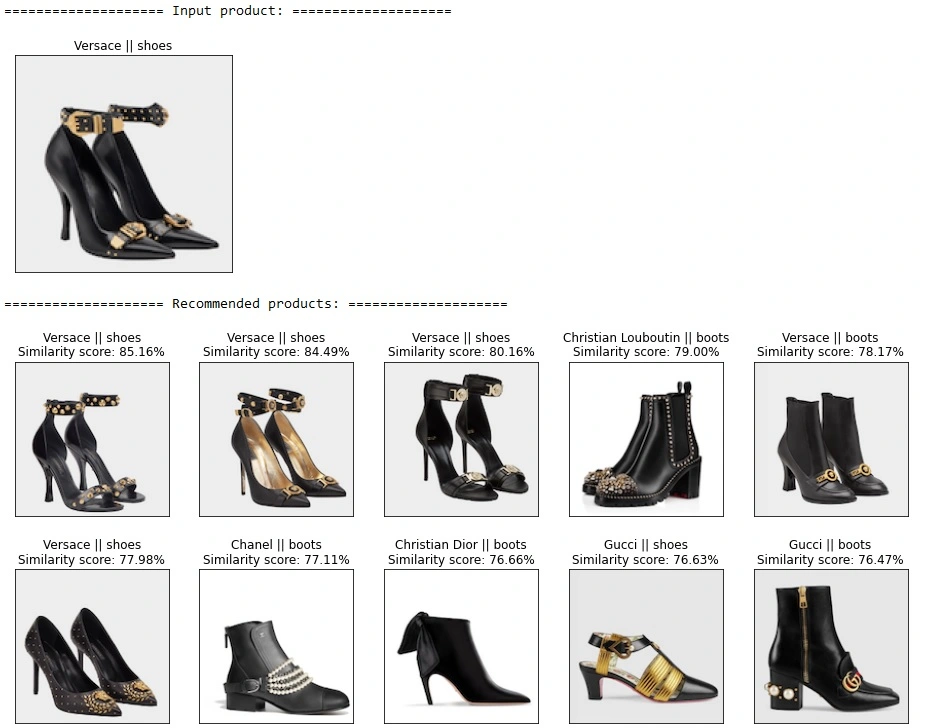
A VLM identifying visually similar shoes and boots (Source)
The internet is overflowing with media content, and VLMs are being deployed to moderate visual content at scale. Platforms that host user-generated media can rely on these models to detect unsafe or policy-violating content, including violence, hate symbols, graphic material, and manipulated media.
Unlike text-only moderation systems, vision-language models can analyze images directly and detect risks that are not obvious from captions alone. Companies like Meta, TikTok, and YouTube use content moderation systems to automate first-level reviews and reduce manual moderation load.
Till now, we’ve discussed some of the advantages and use cases that VLMs offer. However, like all technology, vision-language models have limitations that impact their performance in real-world scenarios and affect their overall reliability.
Here’s a look at some key factors to consider when working with VLMs.
So, while VLMs are fascinating and impactful, they come with challenges that make it critical to depend on expert guidance when implementing them.
For example, building a vision-language model that works in real-world settings starts with high-quality data. These models learn from image and text pairs that must align across diverse topics, environments, and formats. Unlike single-modality models, VLMs connect visual information with natural language, so the quality of the data pipeline directly affects the model’s performance.
On top of this, developers should focus on more than just the size of the dataset. They need to ensure relevance, balance, and clear structure. This includes collecting images from varied conditions and writing text that stays consistent across use cases. Tasks such as captioning, visual question answering, and document understanding often involve complex annotations that require skilled teams with knowledge of both modalities.
At Objectways, we specialize in supporting teams that build and train these types of AI systems. We help source diverse data, design task-specific annotation workflows, and stay involved throughout the project. We prioritize reducing bias, improving generalization, and increasing efficiency through careful dataset creation.
Working on multimodal AI? We help teams create high-quality datasets and develop efficient workflows from start to finish. Get in touch with us and we’ll help turn your ideas into reality with expertise and speed.
Vision-language models bring together visual and language understanding into one system, making it possible for machines to interpret images and respond with meaningful text. As more platforms rely on multimodal data, these models are becoming crucial for making complex tasks easier to handle. In fact, we’re already seeing this in areas like accessibility, content moderation, and intelligent search.
To build reliable large vision models for these purposes, it’s essential to have high-quality data and solid development workflows. Teams need to focus on clarity, balance, and accuracy right from the beginning. The future of AI lies in creating systems that go beyond simply recognizing what they see, but also responding in a way that makes sense in the real-world scenarios they are designed for.


Explore the top 5 computer vision trends in 2025 and see how they impact industries from healthcare and retail to manufacturing and autonomous driving.

Learn how image annotation works, explore different types of image annotations, and see how accurate data labeling improves computer vision model performance.
