Previously, we’ve looked at what inter-rater reliability (IRR) means in the context of data labeling and why it matters when building fair and consistent AI systems. Today, we’ll dive deeper into the challenges that affect IRR, explore what factors cause inconsistencies in annotations, and explore different ways to improve IRR.
Before we get started, why is improving inter-rater reliability so crucial in AI projects? Taking a closer look at how annotation tasks are done, especially by annotators without extensive training, can help us understand why.
Labeling might seem straightforward: just look at the data, tag it, and move on to the next piece of data. However, when multiple people work on the same type of input, differences in how they understand the data can lead to errors.
These issues often come from unclear instructions, different levels of training, or confusion around annotation examples. When this happens while handling large volumes of data, it results in a dataset that makes it difficult for AI models to learn patterns from the data accurately.
In complex or time-constrained AI projects, unmanaged IRR can slow down progress. Annotation teams end up having to recheck the data and labels, review the final model performance, and fix problems that come from poor training inputs.
All of this takes time and resources. In fact, a recent survey revealed that AI models trained on low-quality or inaccurate data resulted in companies losing an average of 6% of their annual revenue, equivalent to approximately $406 million.
A Look at How Data Annotators Use Inter-Rater Reliability
Most AI systems rely on different types of annotated data. High-quality datasets are used to train models, helping them make accurate predictions and recognize patterns.
However, when two annotators review the same data, their labels might not always match. For example, in image and video annotation, if annotators are asked to label damaged products on a conveyor belt, one might tag a slightly dented product as “damaged.”
At the same time, another annotator might ignore it, thinking it’s too minor to be considered a defect. These small differences can quietly affect model accuracy down the line. Simply put, different individuals can interpret the same instructions differently, leading to small but significant differences.
When such scenarios happen repeatedly across thousands of data points, the final AI model also reflects these inconsistencies. It learns from mixed signals and displays unpredictable behavior. Such inconsistencies can create challenges in areas like healthcare, finance, or autonomous driving, where precision is vital.
That’s exactly why improving inter-rater reliability is a critical part of AI development. IRR measures how consistently different annotators apply the same labels. A high IRR means the task is well understood and done correctly, while a low IRR usually indicates unclear guidelines, lack of training, or confusing examples.
Improving inter-rater reliability involves alot more effort than tracking metrics or completing a single annotation session perfectly. While annotation teams often aim for consistency through quick fixes, the practical truth is that achieving long-term reliability requires ongoing effort, regular feedback, and addressing the root causes of inconsistencies.
Here are some common mistakes that occur during annotations:

Agreement Metrics Can Be Misleading without Proper Context
To get a clearer picture of how IRR can be improved, let’s walk through a few examples of how it can be enhanced in different AI projects, such as those in e-commerce and legal sectors.
When it comes to AI in healthcare, deep learning models depend heavily on expert-labeled data. But there are situations where specialists from different healthcare backgrounds may interpret medical images like X-rays or colposcopy scans differently.
One expert might mark the edges of a lesion (an area of abnormal tissue) slightly differently than another. At the end of the day, inconsistent labeling might go unnoticed, but it can impact the model’s accuracy and performance.
Improving IRR in healthcare requires clear data annotation protocols, regular calibration among experts, and visual checks to maintain consistency. This shared understanding helps create stable, reliable training data to build safe and accurate AI tools.
A great example of improving the consistency of medical image labeling comes from the National Institutes of Health (NIH), where five experts marked lesions in colposcopy images. To measure how much the experts agreed on each part of the image, they used a method called “pixel-wise Fleiss’ Kappa.”
This method looks at how much the experts agree on each individual pixel in the image. However, they found that the agreement was only fair to moderate. To make the annotations more effective, they used techniques like STAPLE, which combines all the expert opinions into one result, and heatmaps, which are color-coded images that show where the experts agree the most. These methods improved the consistency of the data.

Annotators May Mark the Same Lesion Differently (Source)
An understanding of English itself isn’t enough for accurate document labeling in the legal sector; it’s a lawyer’s interpretation of the law that really makes a difference. Legal texts are often dense, filled with jargon and subtle nuances, meaning that even a small difference in interpretation can lead to inconsistent labels.
For example, a study on legal document annotation highlighted the value of improving inter-rater reliability. When three annotators labeled legal provisions, agreement scores varied widely. For one category, Cohen’s kappa ranged from 0.33 to 0.68 between different annotator pairs.
After reviewing disagreements and revising their labels, the scores improved significantly. For instance, agreement in the “Prohibition” category rose from 0.49 to 0.98. Also, a final round of expert reviews helped reduce variation between annotators.
By measuring inter-rater reliability and resolving disagreements early, the team was able to produce more consistent labels. This process helped reduce ambiguity and resulted in high-quality data.
E-commerce platforms also rely on accurate information for various use cases like recommending products, detecting fraud, and improving the overall shopping experience. Annotators may have different interpretations when labeling content related to tone, emotion, or relevance, like in customer reviews or chat transcripts.
Here, inter-rater reliability helps by indicating the degree of agreement among annotators on such tasks, making it easier to identify unclear guidelines. Researchers have shown that inter-rater reliability (IRR) can be improved by refining guidelines and providing clearer instructions.
In particular, a study surrounding 2,481 beauty product reviews used clear criteria to identify fake content and measured annotator agreement. By analyzing disagreements and updating the instructions, the team achieved better annotator alignment, leading to a more reliable dataset and improved model performance.
Measuring IRR and improving IRR scores can be tricky, but leveraging expert services like those offered by Objectways can help simplify the process and deliver more consistent, reliable results.
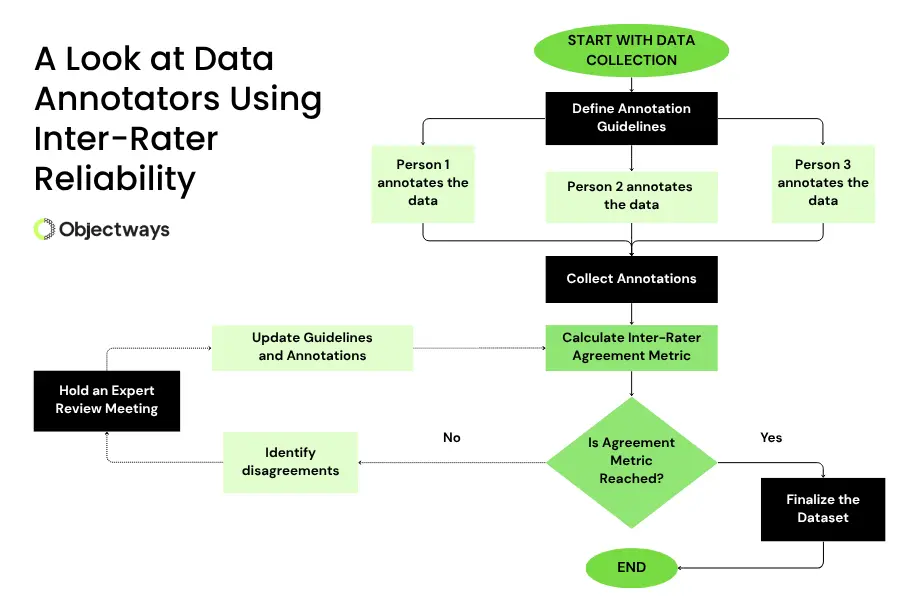
At Objectways, inter-rater reliability is built into the data annotation process from the beginning. When a team of annotators shares the same understanding of a given task, labels become more consistent, which in turn results in an AI model that behaves exactly as expected.
Objectways follows a structured framework to reduce confusion and maintain high-quality outcomes at every stage. Here are some of the steps Objectways follows to ensure consistent data annotation:

Improving Inter-Rater Reliability: Objectways’ Approach
Inter-rater reliability is an important part of producing high-quality labeled data, and at Objectways, we believe in doing more than measuring agreement between annotators. We focus on building data pipelines that are transparent, traceable, and consistent with domain needs.
Here’s how we prioritize inter-rater reliability (IRR) to build trustworthy AI pipelines:
With these practices, Objectway helps deliver data and AI solutions that are accurate, explainable, and AI-compliant.
Inter-rater reliability is a key part of building AI systems that are safe, explainable, and trustworthy in real-world applications. In critical fields like healthcare and finance, consistent data labeling has a direct impact on model accuracy and user confidence. Achieving strong IRR requires the right people, well-defined processes, and deep domain expertise.
At Objectway, we have the expertise to deliver precise and consistent data for your AI projects. If accuracy and reliability in annotation are what you are looking for, we’re here to help. Contact us to have your data annotated the accurate way, ensuring top-quality results for your AI systems.
Inter-rater reliability is a way to measure how consistently different people label or evaluate the same data. It checks whether multiple raters agree when applying the same criteria, helping ensure that results are dependable and unbiased.

See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.
