Every time you ask a question in ChatGPT or use a generative AI feature that responds like a human, a large language model (LLM) is working behind the scenes. Models like OpenAI’s GPT-3.5, GPT-4o, and GPT-5 are designed to handle tasks such as writing, summarizing, and answering questions with high accuracy. But this level of performance comes at a high operational cost.
According to public estimates, running ChatGPT can cost OpenAI around $100,000 per day, mostly due to the computing power these models require. In general, costly AI applications create a practical concern for any company deploying AI at a larger scale. The performance is impressive, but how do you manage the cost?
One widely used solution is model distillation. When applied to language models, it’s known as LLM distillation. This method trains a smaller model to learn from a larger one, allowing it to produce similar outputs while using fewer resources.
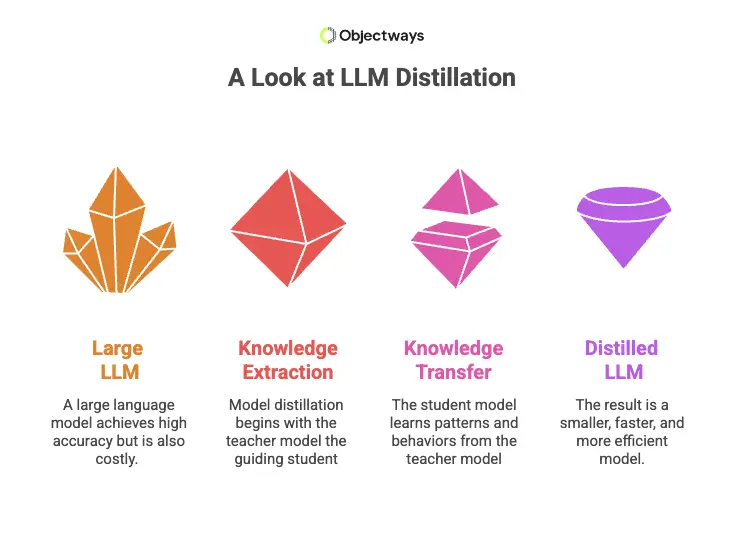
A Look at LLM Distillation
This is one of the reasons GPT-3.5 Turbo became popular when it was released. It offers strong performance while being more efficient and significantly cheaper than earlier GPT-3.5 models, likely due to optimization techniques such as model compression and distillation.
We’ve previously discussed the basics of LLM distillation and how it helps reduce complexity and cost in AI systems. In this article, we’ll further explore its impact, how distillation shapes LLM deployment, the trade-offs involved, and its importance in scaling AI. Let’s get started!
Once a large language model has been trained and performs well, the next challenge is making it efficient enough for everyday use. Many models work accurately but require too much computing power to be practical in products like mobile apps, chatbots, writing tools, or customer support systems.
Model distillation helps address this by using a teacher and student setup. Here’s how it works. The original large model serves as ‘the teacher’. A smaller model, called ‘the student’, learns by studying how the teacher responds to different inputs. Instead of training directly on the original data, the student watches the teacher’s answers and learns to produce similar ones. When this method is applied to language models, it is known as LLM distillation.
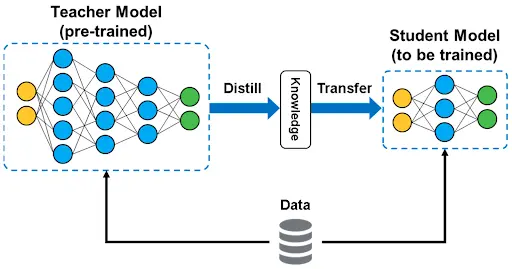
The Teacher–Student Process of Model Distillation (Source)
Language models are now used in everyday applications. Many online platforms use them to accurately answer questions, support conversations, and generate content. However, speed and scalability are becoming just as important as accuracy.
An LLM might deliver good results, but it can be slow or too expensive to run at a large scale. LLM distillation is a great way to reduce resource demands, so models can serve more users and run on different types of hardware infrastructure.
This approach also gives technical teams more options to work with. For instance, they can deploy models that are fast enough for real-time use and affordable enough to maintain. Distilled models are easier to integrate into software products, like chatbots, where responsiveness and cost matter.
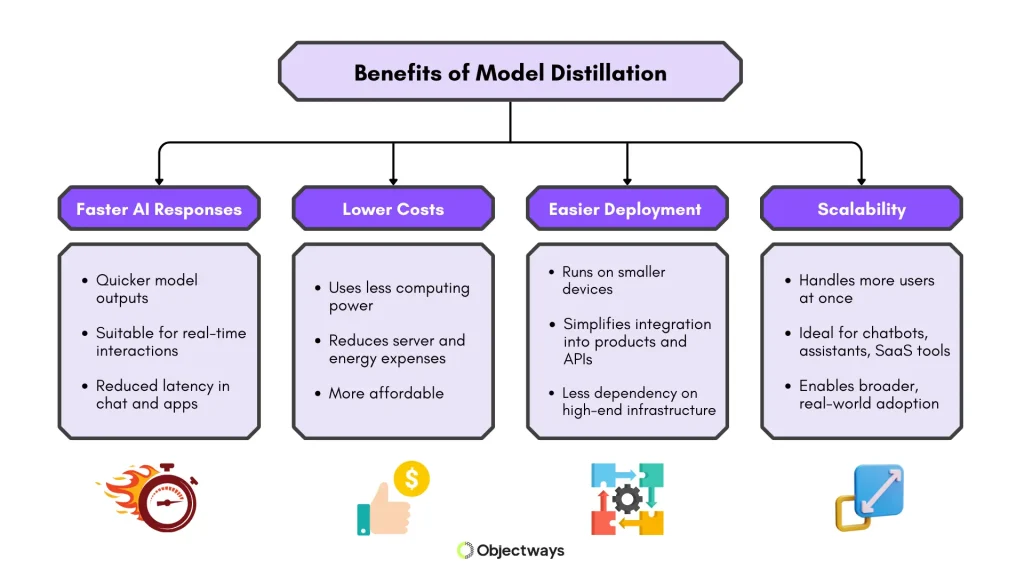
Key Benefits of Model Distillation
While model distillation is a reliable way to make large language models more efficient, it comes with certain trade-offs in performance and flexibility. You can think of it like compressing a high-resolution image: it takes up less space and loads faster, but some fine details may be lost.
Next, let’s look at how distillation changes model performance and where it can fall short.
Reducing a model’s size through distillation often involves some trade-offs. A distilled model may not perform as well as the original in every area. It might miss subtle details or struggle with long documents or highly specific questions.However, for most everyday LLM use cases such as summarizing content, answering general questions, and generating simple text, distilled models can perform reliably well. They meet the needs of most businesses and users, while being faster and more affordable to deploy.
One challenge with model distillation is managing how compression impacts output quality. If a model is compressed too aggressively, it can lose the ability to handle more complex or nuanced tasks. This effect is especially noticeable in tasks involving long-range dependencies or rare tokens that appear less frequently in training data.
When selecting an LLM, people often rely on leaderboard scores or benchmark metrics to guide their choice. But these numbers don’t always tell the full story, especially when techniques like model distillation are involved.
Typically, LLM ranking systems are often used to demonstrate the performance of different models on language tasks. These rankings help users compare the accuracy of different LLMs, but they rarely include technical details about how the models were built.
You can consider LLM rankings like a scoreboard in a sports tournament. They show which teams are leading based on recent performances. However, they don’t share every detail, like how much training each team had or what strategies they used.
That missing context can be significant. For instance, a particular model’s score may appear similar to another’s, but its performance, speed, and cost in real-world use can be very different. Some LLM rankings may not show if model distillation was used, and knowing if a model has been distilled is important.
Here is how model distillation plays a role in LLM rankings:
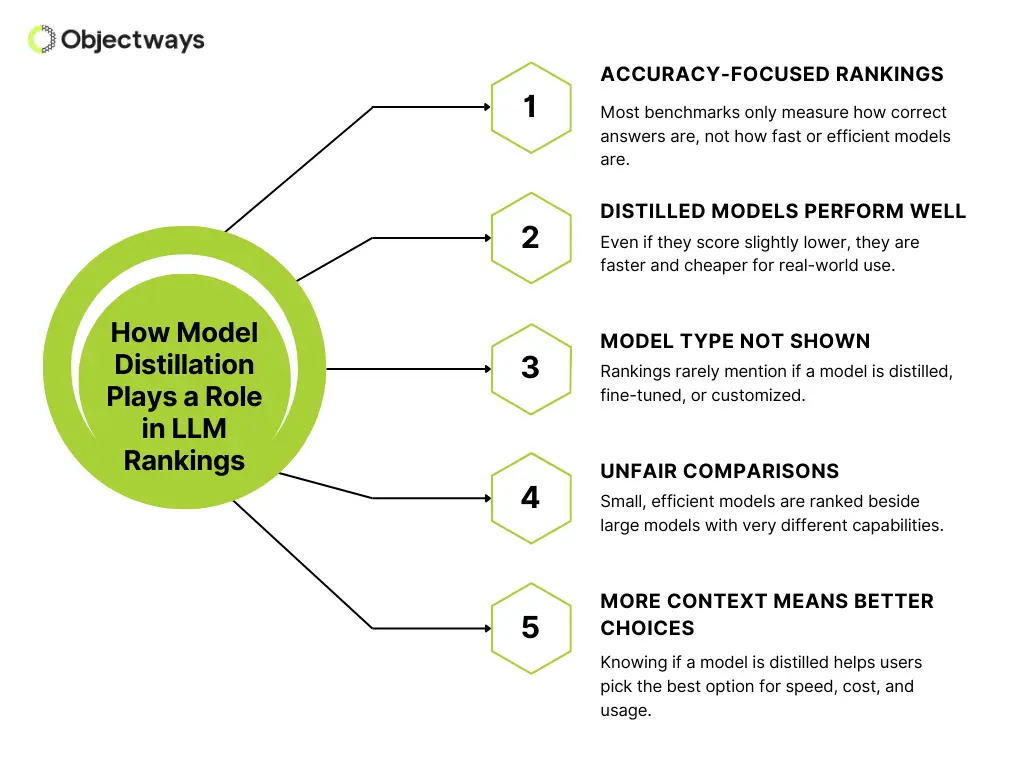
How Model Distillation Plays a Role in LLM Rankings
Now that we have a better understanding of LLM distillation, let’s take a closer look at an example of how it can be applied.
GPT-2, created by OpenAI, was a powerful language model but demanded significant computing resources. Running it on lightweight hardware such as smartphones or Raspberry Pi boards was challenging, which limited its accessibility outside of research labs and high-powered servers.
To make GPT-2 easier to use in these kinds of settings, the AI platform Hugging Face developed DistilGPT-2, a distilled version of GPT-2. Instead of training the new model directly on the original dataset, Hugging Face used model distillation.
In this setup, GPT-2 acted as the teacher, generating outputs for different prompts, while the smaller model acted as the student, learning to imitate those outputs. It is similar to how an apprentice learns from a master by observing and practicing rather than starting from scratch.
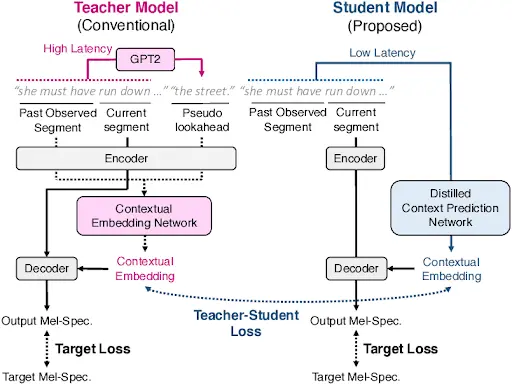
DistilGPT-2 Learns From GPT-2 Using Model Distillation. (Source)
The result was a smaller and faster model with 82 million parameters compared to GPT-2’s 124 million. DistilGPT-2 used less memory and delivered quicker responses, while retaining much of GPT-2’s capability. Although it showed a modest drop in accuracy on benchmarks like WikiText-103, it proved far more practical for real-world applications where speed and efficiency are critical.
This approach has since been used with newer models like GPT-3.5, LLaMA, and Mistral. Distilled versions help bring powerful AI applications into more hands by cutting down on cost and making deployment simpler.
Despite model distillation’s benefits, there are certain limitations to keep in mind. These may have little impact on simple tasks but tend to show up more clearly in complex or high-stakes situations.
Here are a few important factors to consider:
Understanding these limitations helps set the right expectations. Distilled models are practical, but they need to be matched carefully to the task. For critical or high-risk applications, larger and more robust models may still be the safer choice.
Working with the right AI partner can make it easier to navigate these challenges. For instance, at Objectways, we specialize in helping teams streamline their AI workflows. We offer data labeling services, AI development, and consulting to support end-to-end machine learning projects.
The future of LLM distillation is moving beyond simple compression toward smarter, more adaptive techniques. Researchers are exploring methods like hybrid distillation, which aligns outputs and intermediate features and attention patterns to preserve more of a model’s reasoning. Synthetic data generation is also becoming a crucial tool, making it possible for distilled models to learn from high-quality, task-specific prompts without requiring massive labeled datasets.
Looking ahead, we may even see models that self-distill, continuously refining smaller versions of themselves to stay efficient while keeping pace with larger state-of-the-art systems. All of this points to a future where distillation helps make powerful AI more accessible, adaptable, and practical for everyday use.
Model distillation reduces the size and resource requirements of a model without compromising the core abilities people rely on. This makes it possible to run language models in more places, including products that need to respond quickly and stay affordable to maintain.
Even with fewer parameters, distilled models can handle tasks like answering questions, generating content, and following instructions. They may not cover every edge case, but they are fast, cost-effective, and a perfect fit for most real-world applications.
At Objectways, we build custom AI models and provide expert data labeling. Book a call with our team today to learn how we can help you create smarter and more efficient AI tools.
LLM distillation is a method where a smaller language model learns from a larger one. The goal is to make the smaller model faster and lighter while still keeping most of the original performance.

Transfer learning in LLMs enables domain-specific AI. Learn how it works, where it adds value, and why data quality and validation are critical.

Explore how generative AI in procurement improves sourcing speed, reduces risk, and supports smarter, data-driven decisions across the lifecycle.
