Nowadays, we are starting to interact with cutting-edge technology in ways that feel effortless. We ask Siri for directions, tell Alexa to play music, or use apps that turn speech into text. Behind these experiences is annotation, where raw data is labeled so machines can understand it. One of those areas is audio data annotation.
Audio data annotation gives structure and meaning to sound. A recording turns into useful data when details are added, such as who is speaking, the emotion in their voice, and the background sounds around them. With this information, AI models can recognize accents, filter out noise, and respond in ways that feel more natural.
It works a lot like teaching a child to understand a new language. At first, they only hear sounds. With guidance, they begin to notice tone, intent, and context. Data labelling and annotation give models the same guidance during model training, so they can learn to recognize not just words but also voices, emotions, and background sounds.
This leads to the growing importance of data annotation tools. Interestingly, the market also reflects this demand. Data annotation tools were valued at $1.02 billion in 2023 and are projected to reach $5.33 billion by 2030.
In this article, we’ll explore audio data annotation, showcase real-world examples, and share best practices. Let’s get started!
Audio data annotation is the process of turning raw sound into information that machines can understand. An audio recording on its own is just a stream of audio waves to a computer. When people add structure and context, that same file becomes training material that AI can learn from.
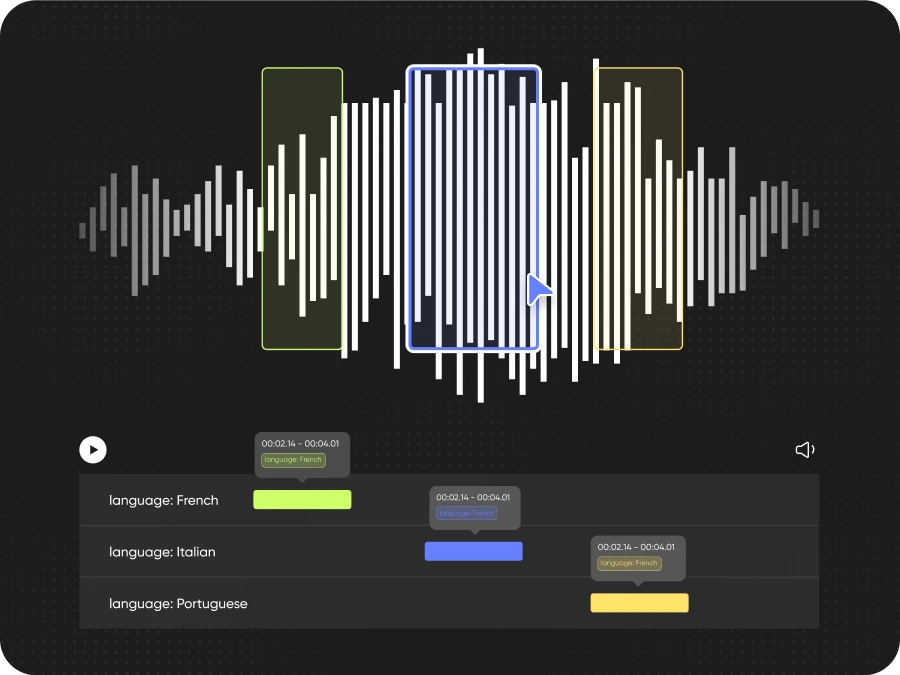
An Example of Audio Data Annotation (Source)
This structure comes from labels. They can mark when a sentence begins and ends, show who is speaking, capture the emotion in a voice, or note background sounds like music, laughter, or traffic. These details enable AI models to go beyond just hearing words and start recognizing intent, mood, and setting.
Here are the key techniques used in data labelling and annotation related to audio data:
We are already seeing the impact of such labeled data with the rise of AI voice tools. People now mimic celebrities, athletes, and politicians with striking accuracy. Behind the scenes, these systems are trained on annotated audio, where speech patterns, accents, and vocal tones are carefully labeled to make the imitation sound as realistic as possible.
Annotating audio is a slow and detailed process. A single clip may include multiple speakers talking over each other, strong accents, or background sounds like traffic and music. To train a system properly, annotators must review recordings and add labels indicating who is speaking and when sentences begin and end.
Based on the application, they also mark emotions or background noises, such as traffic, music, or overlapping voices. Many clips need to be checked more than once before they are ready.
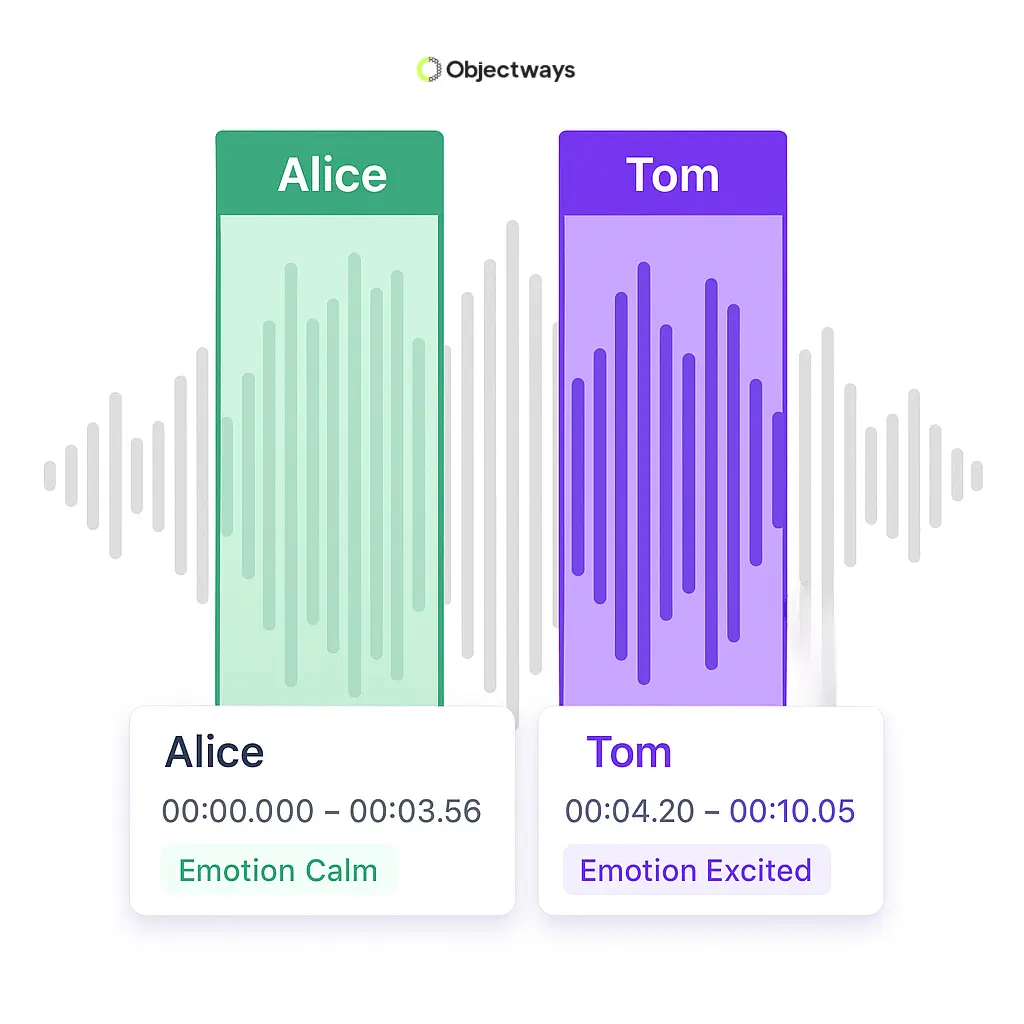
How Audio Clips Are Annotated
The difficulty grows with scale. Large projects often involve thousands of hours of recordings, and it is easy for quality to slip if every file is not handled with the same care. Privacy also matters when it comes to data labelling and annotation, since conversations can contain sensitive information that must be protected.
Audio annotation supports many of the technologies we use in daily life. Here are some of the most important AI applications related to audio data:
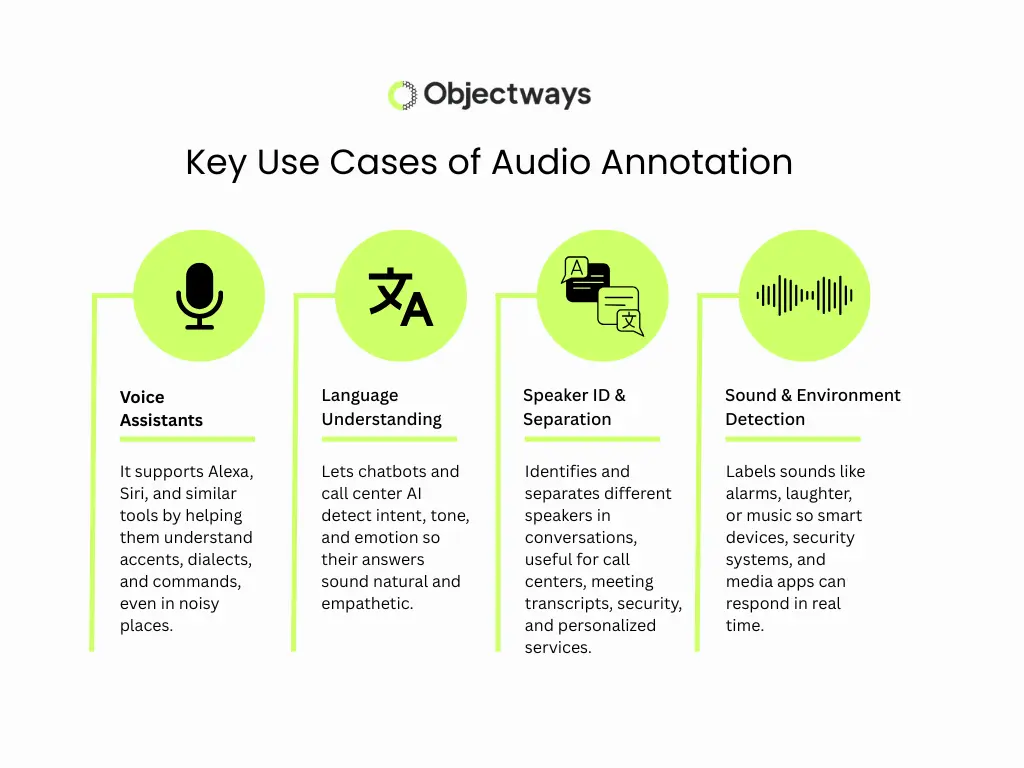
Use Cases Related to Audio Data Annotation
When we use voice assistants and other smart tools, it is easy to overlook that audio annotation is the driving force behind them. By labeling speech for meaning, tone, and context, it enables machines to understand us and powers the way technology listens, interprets, and responds.
Next, let’s see some of the ways data labelling and annotation are already making a difference.
Baby monitors are built to give parents peace of mind by alerting them when their baby is crying, even from another room. For machines, however, sound is complex. A hungry cry, a sleepy whimper, and the hum of a dishwasher can easily overlap and create confusion.
To improve accuracy, baby-tech companies and researchers rely on audio annotation. Human teams listen to recordings and label them carefully, marking cries, coos, and background noises like television or running water. These annotations provide the training data that machine learning systems need to learn what truly matters.
Studies have shown that deep learning models trained on annotated datasets can detect infant crying with high accuracy. Carefully labeled data has turned baby monitors from simple listening devices into smarter systems that provide clearer and more reliable alerts for parents.
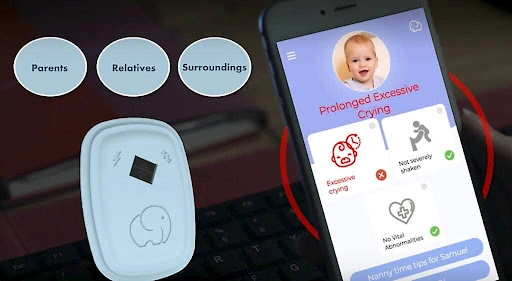
A Smart Baby Monitor Powered by Audio Annotation (Source)
There are now more than 600 million Alexa devices in use around the world, and one of the biggest reasons Alexa feels natural to talk to is audio data annotation. To build reliable speech recognition, large volumes of recordings are collected and labeled so that machine learning systems can learn from them.
Annotators identify important details such as different accents, when one speaker stops and another begins, and background sounds that might interfere, like dishes clinking or a television playing. These annotations provide the training context Alexa needs to recognize voices across regions, adapt to varied speaking styles, and pick out commands even in busy or noisy environments.
Getting audio data annotation right involves more than simply adding labels. The way the data labelling and annotation process is managed plays a crucial role in the quality of the final results.
Here are some best practices for audio data annotation that can make a real difference.
Audio annotation opens the door to smarter systems, but it comes with its own challenges. Here are some of the hurdles teams often face when handling data labeling and annotation:
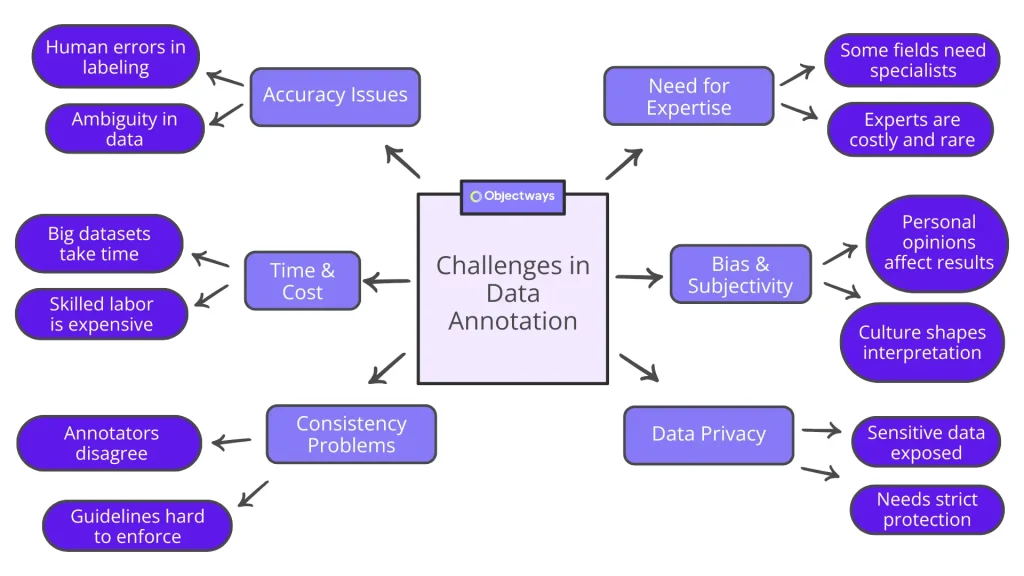
Challenges in Data Labelling and Annotation
At Objectways, we help organizations manage these challenges through a mix of automatic data annotation and human expertise. By combining scale with precision and keeping data security at the core, annotation becomes not just possible but reliable.
The way audio data is annotated is changing quickly. One of the biggest shifts is the rise of automatic data annotation. Instead of people labeling every second of sound, AI systems now pre-annotate recordings, leaving humans to refine the results. This speeds up the process and keeps quality high, especially when projects involve thousands of hours of audio.
Another trend is multimodal annotation. By linking audio with video or text, systems can capture richer context. A laugh paired with a smiling face tells a much clearer story than sound alone, making emotion detection far more accurate.
Real-time annotation is also emerging. Live streams can now be labeled as they happen, opening possibilities for instant captions, customer support, and safety monitoring.
Beyond this, personalization is becoming a big focus. Annotated datasets are increasingly designed to reflect each person’s unique way of speaking, allowing technology to respond in ways that feel natural and tailored.
Audio data annotation is the backbone of systems that respond naturally to human speech. From voice assistants and chatbots to healthcare and security, accurate labeling gives machines the ability to understand accents, tone, and context.
High-quality data annotation depends on precision, privacy, and scalability. It requires the right balance of automation for speed and human review for reliability. Without this, even advanced models fall short.
At Objectways, we work with teams to put this into practice. If you are exploring audio data annotation options, we would love to connect and talk through how Objectways can support your goals. Book a call with us today!
Audio data annotation is the process of adding labels to recordings so machines can understand them. This can include marking who is speaking, what emotions are present, or whether there are background sounds like traffic or music. These labels turn raw sound into structured data that can be used to train AI models.

See how ground truth data powers accurate machine learning models, reduces bias, and strengthens trust in AI systems across industries.
Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.
