Despite data being the foundation of AI, it’s easy to overlook how important it is when building AI models that actually work in the real world. A lot of the recent excitement in AI has focused on breakthroughs in model architectures and increasingly powerful systems.
New models appear every few months, each claiming better reasoning, faster responses, or stronger performance across benchmarks. Over the past two years, the number of large-scale AI language models released has increased by more than 420%. However, simply using better models doesn’t automatically guarantee better AI systems.
In a recent interview, Satya Nadella, CEO of Microsoft, pointed out that groundbreaking innovation in AI models quickly loses its edge. Satya notes, “You may have done all the hard work and unbelievable innovation, except it’s one copy away from being commoditized. The person who has the data for grounding and context engineering can then take that checkpoint and train it.”
In other words, the real advantage comes from the data that grounds these models in reality. Enter ‘ground truth data’ – the verified data that represents the correct outcomes used to train models and evaluate.
When this high-quality ground truth data is missing, AI projects struggle to succeed. Studies suggest organizations will abandon 60% of AI projects that are unsupported by AI-ready data in the coming months.

High-quality data is essential for AI models to perform reliably.
Let’s take a closer look at ground truth data and why it plays such a critical role in machine learning and AI.
Ground truth data is accurate and verified data used to train, validate, and test AI models. A ground truth dataset represents the most reliable reference for what is considered the ‘correct’ outcome based on real-world observations.
By comparing a model’s outputs with ground truth data, data scientists and AI teams can evaluate whether machine learning and AI systems are producing results that are accurate in real-world scenarios. This helps teams see how well the model performs and where it needs improvement.
So what does this look like in an AI application people interact with every day? Consider a computer vision system that performs image segmentation, a task commonly used in smart photo editing tools. In this task, an AI model analyzes an image and separates different objects or regions within it.
For example, many photo editing apps let users quickly select a person, background, or specific object in an image. Behind the scenes, segmentation models identify the boundaries of each element in the photo so the tool can isolate them. This makes it possible to blur backgrounds, remove objects, or apply edits to specific parts of the image without affecting the rest.
To train these systems, human annotators first create the ground truth by labeling images and marking exactly which pixels belong to each object or region. These labeled images form the ground truth dataset that teaches the model what the correct segmentation should look like.
Once the model is trained, it generates its own segmentation when it analyzes a new image. This prediction is then compared with the ground truth labels to measure how closely the model’s output matches the correct result.

Comparison of an Input Image, the Ground Truth Segmentation, and the Model’s Predicted Segmentation (Source)
Even when the ground truth and predicted segmentation look almost identical, small differences often appear along object edges or fine details. These subtle errors can have serious consequences in real applications.
Next, let’s walk through how ground truth data supports model validation. Model validation is an important stage in developing an AI model, alongside model training and model testing. These stages typically use different splits of the same dataset, commonly known as the training set, validation set, and test set.
Each split has a different purpose during the model development process. The training set is used to teach the model patterns in the data, the validation set helps refine and optimize the model during development, and the test set is used to evaluate how well the model performs on completely unseen data.
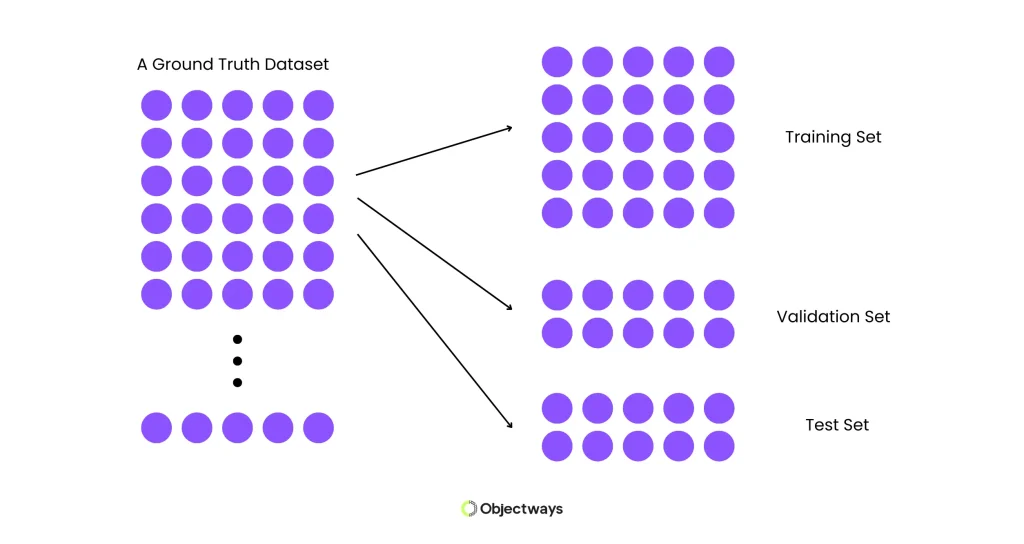
Splitting a Dataset Into Training, Validation, and Test Sets
Ground truth data is crucial during model validation. After a model has learned patterns during training, it generates predictions on the validation dataset. These predictions are then compared with the ground truth labels, which represent the correct outcomes for each example.
By comparing predictions with these verified labels, AI development teams can measure how accurately the model is performing and identify areas where it may be making mistakes. This process helps developers tune model parameters, adjust training strategies, and detect issues such as overfitting, where a model performs well on training data but struggles with new inputs.
Once the model has been refined through validation, the test set is used to evaluate its final performance. Like the validation stage, predictions are compared against ground truth labels to measure how well the model generalizes to new, unseen data.
To quantitatively compare a model’s predictions with the correct outcomes, AI developers use performance metrics. These metrics measure how closely a model’s predictions match the ground truth labels during validation and testing. Common evaluation metrics include accuracy, precision, recall, and the F1 score.
Accuracy measures the percentage of predictions that are correct when compared with ground truth data. While it provides a quick overview of performance, accuracy alone can sometimes be misleading, especially when datasets contain imbalanced classes, where one category appears far more often than others.
To gain deeper insight, precision and recall can be used. Precision measures how many predicted positive cases were actually correct, and recall measures how many of the real positive cases the model successfully identified.
Going a step further, the F1 score combines precision and recall into a single metric, helping balance false positives and false negatives. A false positive occurs when the model incorrectly predicts a positive result, while a false negative occurs when the model fails to identify a case that should have been positive.
Another useful model evaluation tool is the confusion matrix, which breaks down predictions into true positives, true negatives, false positives, and false negatives visually. This allows teams to clearly see where the model is making mistakes.
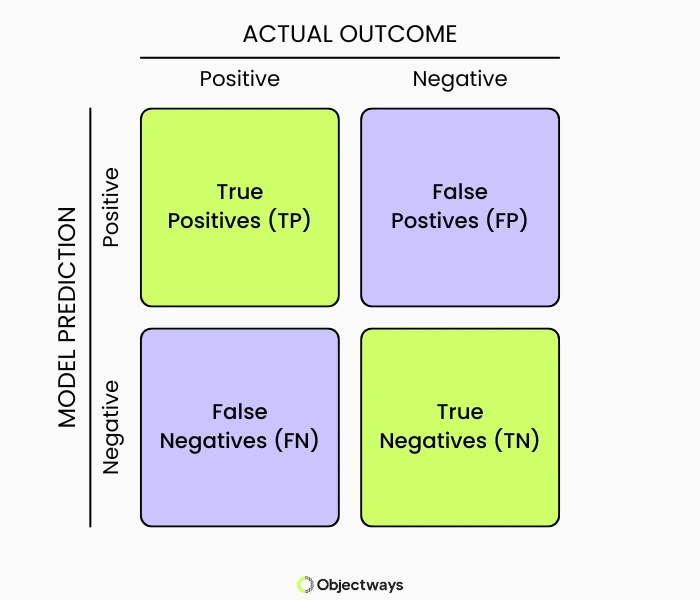
An Example of a Confusion Matrix (Source)
All of these evaluation metrics rely on ground truth data. If the ground truth labels are incorrect or biased, the resulting accuracy, precision, recall, and F1 scores will also be misleading.
This can create a false sense of confidence in a model’s performance and hide weaknesses that may appear in real-world use. That’s why high-quality ground truth datasets are essential for building reliable AI systems.
Research shows that data scientists can spend anywhere from 60% to 80% of their time preparing and cleaning data before building models. Much of this effort goes into creating reliable ground truth data.
When data is accurately labeled, consistent, and well structured, AI models can learn the right patterns and relationships within the data. This directly improves model accuracy. Clean and reliable datasets reduce noise during training and enable models to make more precise predictions with fewer mistakes.
High-quality ground truth data also supports models with generalization. When datasets include diverse and representative real-world scenarios, models are more likely to perform well on new, unseen data instead of overfitting to a limited set of examples.
For example, an object detection model trained only on images captured in clear daylight may struggle to recognize objects at night or in poor weather conditions. When the ground truth dataset includes a wide range of lighting conditions, environments, and perspectives, the model can learn patterns that transfer more reliably to real-world situations.
In addition to these benefits, reliable ground truth data builds trust in AI systems. When models are trained and evaluated using accurate data, their results are more consistent, transparent, and fair. Without trustworthy data, even advanced models can produce unreliable or biased outcomes.
Now that we have a better understanding of how ground truth data makes a difference in AI systems, let’s explore a few real-world applications.
High-quality ground truth is vital for training computer vision models to detect medical conditions such as tumors in radiology scans. These ground truth annotations are typically created by trained medical professionals who carefully mark or label areas of concern within medical images.
Accurate annotations make it easier for AI models to learn clinically meaningful patterns rather than noise or visual artifacts. As AI systems increasingly support doctors in diagnosing medical conditions, even small labeling errors can influence patient safety and treatment decisions.
However, creating ground truth data for medical imaging is not always straightforward. Different medical experts may interpret the same scan in slightly different ways, particularly in complex tasks such as tumor segmentation. These differences in clinical judgment can introduce inconsistencies into the dataset.
To handle differences between annotators, researchers have developed methods that combine multiple expert labels to estimate the most accurate result. By analyzing where experts agree or disagree, these approaches can produce more reliable ground truth data and improve the accuracy of medical imaging models.
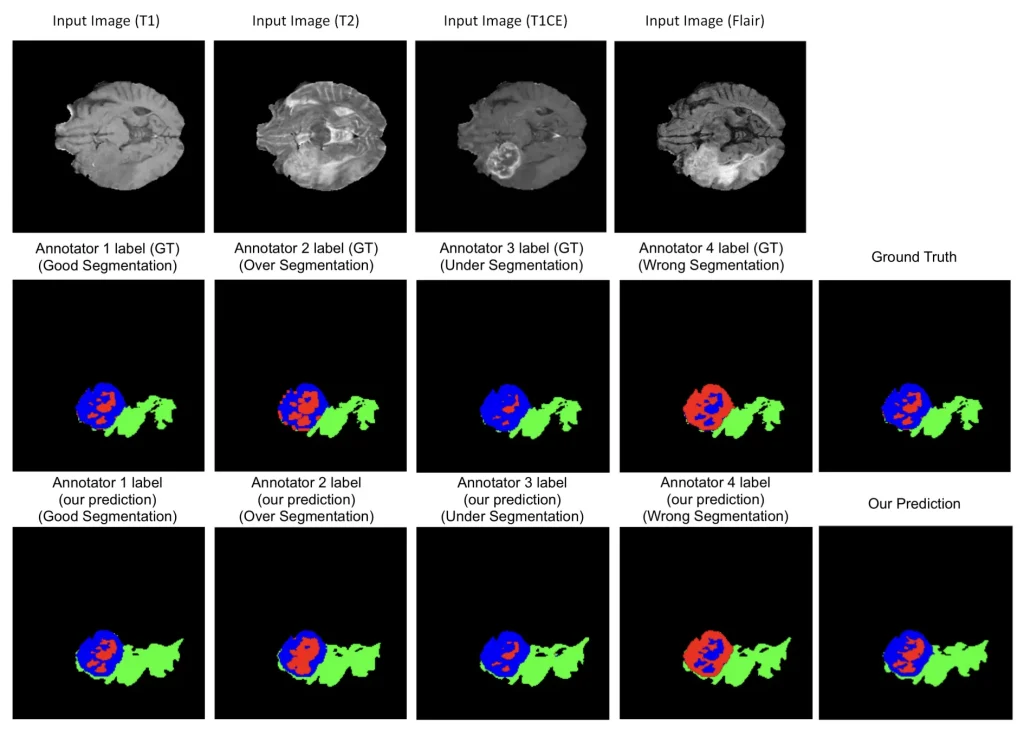
Considering Annotator Variability Leads to More Accurate Ground Truth and Predictions (Source)
Sentiment analysis is used to understand how people feel about products, services, or events by analyzing written text. Businesses often apply sentiment analysis to customer reviews, social media posts, and survey responses to identify whether feedback is positive, negative, or neutral.
To train these systems, reliable ground truth data is critical and typically consists of text that has been accurately labeled with the correct sentiment. Clear and consistent annotations help models learn to recognize tone, context, and subtle language cues such as sarcasm or emphasis.
If the ground-truth labels are inconsistent or subjective, a model may struggle to generalize across different writing styles or content types. The insights generated from a model can become unreliable for tasks like analyzing customer feedback or guiding business decisions.
In cities like San Francisco and Phoenix, self-driving vehicles like Waymo’s are already operating on public roads. Such vehicles rely on AI systems that constantly analyze their surroundings to safely navigate complex traffic environments.
For such autonomous applications, ground truth data is key. Labeled images and sensor data help AI systems learn to distinguish between people, vehicles, traffic signs, and other obstacles. Large benchmark datasets used in autonomous driving research highlight how important this labeled data is.
For instance, datasets such as the Waymo Open Dataset and the nuScenes dataset consist of detailed annotations from multiple sensors such as cameras, LiDAR, and radar, capturing objects and scenes in complex urban environments.

A Glimpse of the nuScenes Dataset (Source)
Studies using these datasets show that precise and diverse ground truth labels significantly improve object detection, tracking, and scene understanding. With better data, autonomous systems can interpret their surroundings more clearly and make safer decisions on the road.
Here are some best practices to keep in mind while creating ground truth datasets:
Despite using the best practices, creating high-quality ground truth data can still be tricky. As datasets grow larger and labeling tasks become more complex, several challenges can pop up during the annotation process.
Here are some of the challenges related to ground truth data labeling:
Working with experienced data annotation partners can make this process easier. Providers like Objectways bring structured workflows, domain expertise, and scalable processes to support the creation of reliable ground truth data.
Creating high-quality data involves more than just ground truth labeling. It requires clear processes, experienced annotators, and careful quality control at every stage.We know better than anyone how important reliable data is when building AI systems that actually work in the real world. If you are looking for support with ground truth dataset creation or large-scale data annotation, our teams are here to help.
At Objectways, we turn raw data into meaningful annotations that power smarter AI models.
We work with a wide range of data types, including images, video, text, and sensor data. Our trained annotators and domain experts follow structured workflows designed to maintain accuracy and consistency across every dataset.
With layered quality checks, scalable annotation teams, and flexible workflows, Objectways helps organizations manage large volumes of data without compromising quality.
Need support building high-quality ground truth data for your AI project? Contact our team today!
Ground truth data might not always get the spotlight, but it quietly plays one of the most important roles in building reliable AI systems. From training models to evaluating their performance, it provides the foundation that helps AI understand the real world.
As AI continues to move from research labs into everyday applications, the quality of the data behind these systems matters more than ever. Accurate, well-labeled ground truth datasets let models learn the right patterns, perform reliably in new situations, and produce results that people can trust.
Ground truth in a dataset is the verified information that represents the correct answer for each data point. It acts as a trusted reference used to train AI models and evaluate how accurate their predictions are.

Explore how medical data annotation enables smarter healthcare AI applications, powering imaging analysis, risk prediction, and clinical documentation.

Understand how a data annotation specialist improves AI performance through expertise, consistency, and domain-specific data labeling.
