Typically, AI solutions in self-driving cars, facial recognition apps, and security systems rely on computer vision models trained to analyze and extract meaningful information from images and video footage. It’s similar to how humans can walk into a room and instantly recognize a chair, a person, or a pet.
One key task that a computer vision model can be trained for is object detection, which enables it to recognize and locate specific items in an image or video. From spotting a pedestrian to identifying a cup on a table, this task relies on object detection datasets, which provide labeled examples that teach the model how to recognize objects in different scenes.
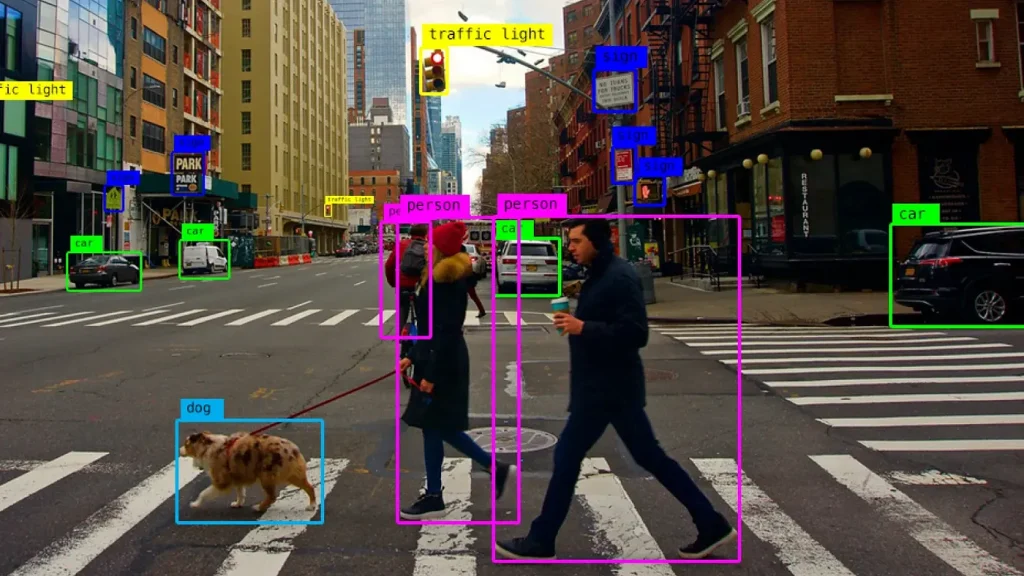
Object detection being used to detect various objects in an image. (Source)
You can picture object detection datasets like the labeled diagrams in a textbook, pointing out and naming each part so the model can learn to recognize them on its own. While useful, building these datasets from scratch can take a lot of time and effort – it generally involves collecting thousands of images and carefully annotating each one.
Fortunately, the AI community has already created many open-source datasets that are freely available. These are great for getting started with general-purpose object detection.
Some of the most widely used object detection datasets include MS COCO, NuScenes, PASCAL VOC, KITTI, and Open Images. In this article, we’ll take a closer look at these popular datasets and explore how they support various object detection applications across different domains. Let’s get started!
The Microsoft Common Objects in Context (MS COCO) dataset is a large-scale resource designed for object detection, segmentation, and captioning. This dataset was created and released by Microsoft in 2014. It focuses on real-world images with multiple objects and includes over 330,000 images, with more than 200,000 labeled to help AI models learn.
The dataset also covers 80 common object categories like people, cars, animals, and household items. Each image comes with rich annotations, such as bounding boxes to show where objects are, segmentation masks to outline their shapes, keypoints to mark body parts, and descriptive captions. What makes MS COCO really impactful is that it shows objects in their natural settings, helping models learn how things appear in real-life scenes.
Apart from object detection, the dataset can also be used for many other computer vision tasks. For instance, it can help train and test AI models to understand the shapes or outlines of objects (segmentation), estimate the pose of an object (pose estimation), and even write short captions describing what’s happening in a picture (image captioning).

Detection Outcomes From A Model Trained Using The MS COCO Dataset. (Source)
The NuScenes dataset was created by Motional in 2019 and is designed specifically for self-driving cars. Unlike traditional image-based datasets, NuScenes provides a multimodal, 360-degree view of the environment around a car by incorporating inputs from a variety of sensors, like LiDAR (Light Detection and Ranging), RADAR, and digital cameras. It captures everyday driving scenes like busy streets, intersections, and different weather conditions, making it useful for real-world autonomous driving tasks.
Since the dataset was put together to help improve self-driving car technology, it includes thousands of short driving images and clips, each about 20 seconds long, recorded in four different cities: Boston, Las Vegas, Pittsburgh, and Singapore. The dataset covers 23 types of road-related objects, like cars, people, traffic signs, bicycles, and cones. Its strength lies in the detailed 3D bounding box labels, which show where each object is and also include information about its depth.
Using these labels, the NuScenes dataset can be used to train and test AI models for computer vision tasks like 3D object detection and tracking, and understanding road scenes; all of which play a key role in helping self-driving cars become smarter and safer.

An Example of the 3D Bounding Box Annotations Supported by the NuScenes Dataset. (Source)
Pattern Analysis, Statistical Modelling and Computational Learning (PASCAL) Network created the PASCAL VOC (PASCAL Visual Object Classes Challenge) dataset in 2005. It is one of the earliest datasets created for object detection that is still available today.
At its launch, the dataset included four classes: Bicycle, Cars, Motorbikes, and People. Over the years, the dataset has been expanded to include more categories. By 2012, it contained around 20 classes. Though many of the other datasets offer larger-scale images and advanced annotations, PASCAL VOC is a milestone in AI that remains relevant for its simplicity, clarity, and historical importance.
The PASCAL VOC dataset contains about 11,000 images with 27,000 labeled objects across 20 common categories, such as people, cars, animals, and household items. Each object in the images is marked with bounding boxes to show where it is and segmentation masks for more precise outlines.
PASCAL VOC is often used as a starting point for learning about object detection and image segmentation. It’s also a popular choice for testing out new ideas and benchmarking different AI models because of its clear labels and manageable size.

Object Classes Supported by the PASCAL VOC Dataset. (Source)
The KITTI dataset was created by Karlsruhe Institute of Technology and Toyota Technological Institute of Chicago in 2012. Like NuScenes, it’s designed for driving-related research and was one of the first datasets to include 3D bounding boxes for real-world traffic scenes. The data was collected in Karlsruhe, Germany, using a car equipped with several sensors.
KITTI includes different types of data, such as stereo image pairs (two images taken from slightly different angles), motion flow between video frames, and 3D views of objects. It focuses on common road objects like cars, pedestrians, cyclists, traffic signs, and trams. Each object is labeled with both 2D and 3D bounding boxes, along with movement information. The dataset captures scenes from urban and semi-urban areas, giving a realistic view of different driving environments.
KITTI is still widely used today as a benchmark for building and testing self-driving systems. It’s especially helpful for tasks like tracking moving objects, understanding road scenes, combining camera and LiDAR data, and creating detailed maps.

A Look at Segmentation Using KITTI (Source).
Open Images is a large-scale, open-source dataset introduced by Google. The first version of Open Images was released in 2016. As an open-source dataset, it has become a vital resource for various computer vision tasks. In fact, the Open Images dataset is one of the largest and most detailed collections used in computer vision.
It contains over 9 million images, with approximately 16 million labeled objects across more than 600 categories, ranging from animals and vehicles to tools and everyday items. Many images in the dataset include detailed annotations like bounding boxes, object outlines (segmentation masks), relationships between objects, and textual captions. Because of its size and variety, Open Images is used in a wide range of real-world applications like automatic image tagging, visual search, retail product recognition, and content moderation.
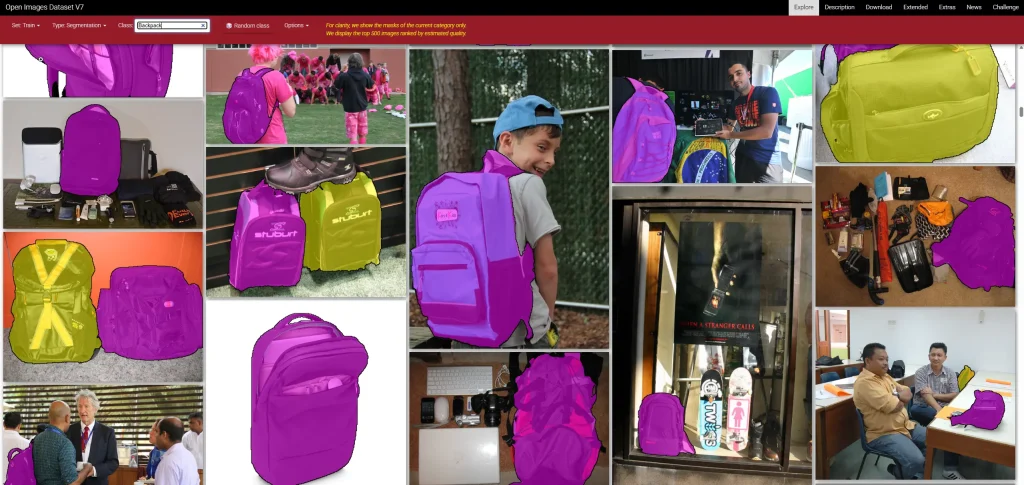
Examples of Images Labelled to Identify Backpacks in the Open Images Dataset (Source).
When you’re building a computer vision model for object detection, choosing the right dataset is one of the most important steps. The dataset you use can have a big impact on how well your model performs and how useful it is in real-world situations. Since not all datasets are the same, it’s important to pick one that fits your specific needs.
Here are a few key factors to consider:
These are just a few essential factors to keep in mind when choosing a dataset for object detection. If you need help finding the right fit or creating a custom dataset, Objectways is here to help.
We offer expert support to integrate AI and computer vision into your business, from selecting high-quality datasets to building custom solutions when off-the-shelf options fall short. Reach out to Objectways to create well-labeled, reliable datasets tailored to your needs.
The success of any object detection model begins with selecting the right dataset. Whether the task involves detecting pedestrians, vehicles, or everyday objects, the quality and relevance of the dataset have a direct impact on model accuracy and performance.
Datasets like MS COCO, NuScenes, PASCAL VOC, KITTI, and Open Images each have their own strengths depending on what you’re working on. Some are better for general object detection, while others are designed for things like self-driving cars or large-scale image recognition.
Getting the most out of these datasets depends on several factors, like choosing the right one for your project, training your model effectively, and making sure everything integrates smoothly. At Objectways, we provide the expertise to help you choose, optimize, or build the dataset that best fits your needs. Contact us to scale your AI solutions with confidence.

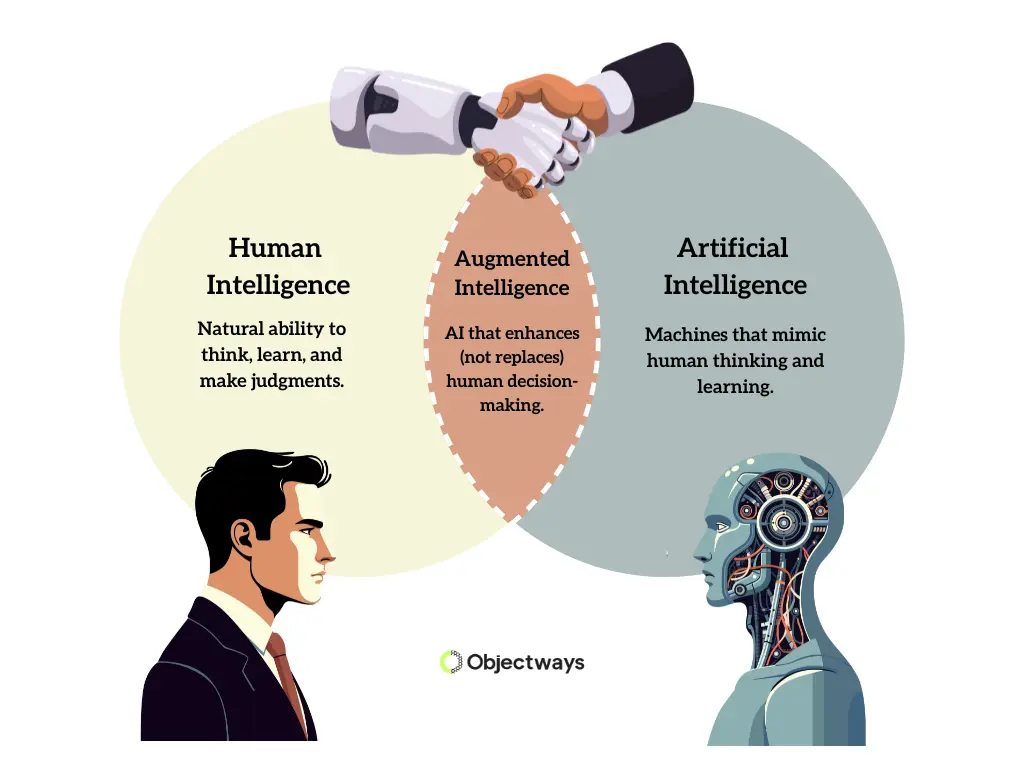
Augmented AI refers to AI systems designed to work alongside people, helping them make better decisions. These systems analyze data, pull in relevant information, and...
As humans, we often learn new tasks by building on skills we already have. If you can ride a bicycle, picking up how to ride...
