Every second of every day, millions of frames of video clips are being captured, streamed, and analyzed from high-resolution movie clips to police bodycams. Video isn’t just content anymore; it’s valuable data. In fact, video data already makes up over 82% of global internet traffic, and it keeps increasing. As the digital world is becoming more and more visual, artificial intelligence (AI), more specifically computer vision, is being tasked to analyse, understand, and act on what it sees.
But computer vision systems don’t automatically know what’s happening in a video. They need context, structure, and guidance. That’s where video annotation and video annotation tools become crucial. These tools can help turn raw video footage into information that AI models can learn from. By tagging people, objects, actions, or speech across frames, video annotation guides AI models trying to detect patterns, follow movement, and interpret real-world events with clarity.
By doing so, video annotation enables AI solutions in industries like autonomous driving, media, security, and entertainment. It makes it possible for machines to analyze complex video content and provide insights that support better decision-making. With the computer vision market all set to surpass $63.48 billion by 2030, video annotation software is more relevant now than ever.
In this article, we’ll learn about video annotation, how it works, and its applications. We’ll also explore some of the best practices related to video annotation.
When it comes to both image and video annotation, we add labels to pictures or video frames to help teach computers how to make sense of the visual data, but there are some stark differences between the two.
Image annotation is all about labeling a single, still image, like drawing a bounding box around a dog in a photo or tagging different objects. Video annotation is a bit trickier as it deals with lots of images (frames of the video) shown one after another, like in a movie. Here, you not only label what’s in each frame, but you also keep track of how the contents move and change over time. Since images don’t move, labeling them is usually easier. With videos, you have to take this motion into account and how objects interact from one frame to the next, which makes it more complex.
In a nutshell, annotating an image is like planting a flag on a still map, while annotating a video is like charting a moving river. Also, image and video annotation are used to train computers for different tasks. Image annotation is great for assisting self-driving cars in recognizing road signs or teaching facial recognition systems to tell people apart. Video annotation, on the other hand, is used for tasks like spotting important moments in sports games or noticing unusual behavior in security footage.
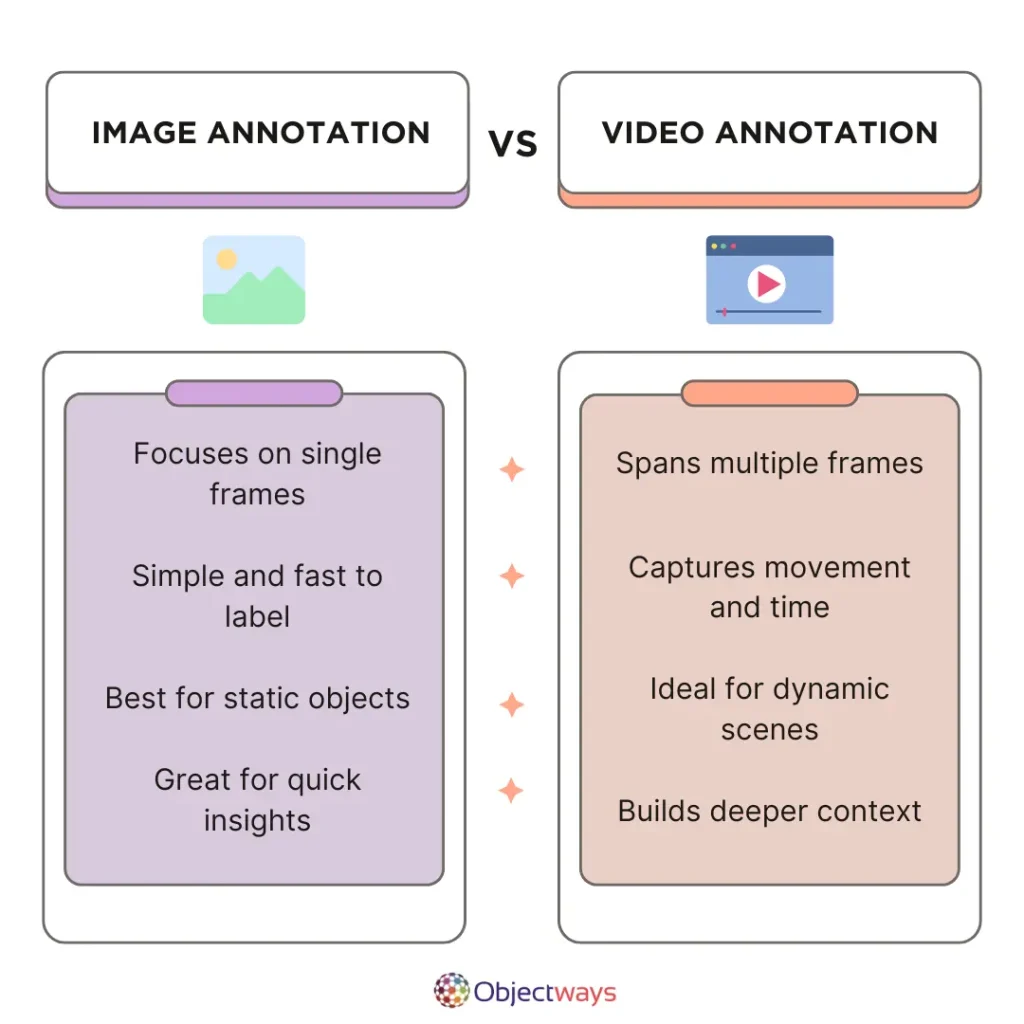
Key Differences Between Video and Image Annotation
Now that we’ve discussed the key differences between image and video annotation, let’s walk through some of the use cases of video annotation in media. Video annotation is crucial for many media and entertainment platforms. These use cases showcase how labeled video data can help AI systems make content easier to access, organize, and understand.
Content moderation and topic tagging are vital parts of ensuring video content is organized and easy to evaluate. The process generally involves analyzing videos and labeling them with the right topics, using an industry-standard taxonomy. This process helps sort content properly, making it easier to find specific videos among a large collection.
In particular, in topic tagging, videos and films are labeled with detailed categories, such as adventure, musical, action, and more, using an official set of standards like IAB (Interactive Advertising Bureau). Contents can also be tagged as “sensitive” to flag videos that might need to be monitored because of their content.
Together, content moderation and topic tagging build a reliable, trustworthy dataset. These types of datasets can also be used to train and test video analysis AI tools that need to be ready to meet the needs of the fast-changing media industry. Platforms like Netflix and YouTube are already doing this.
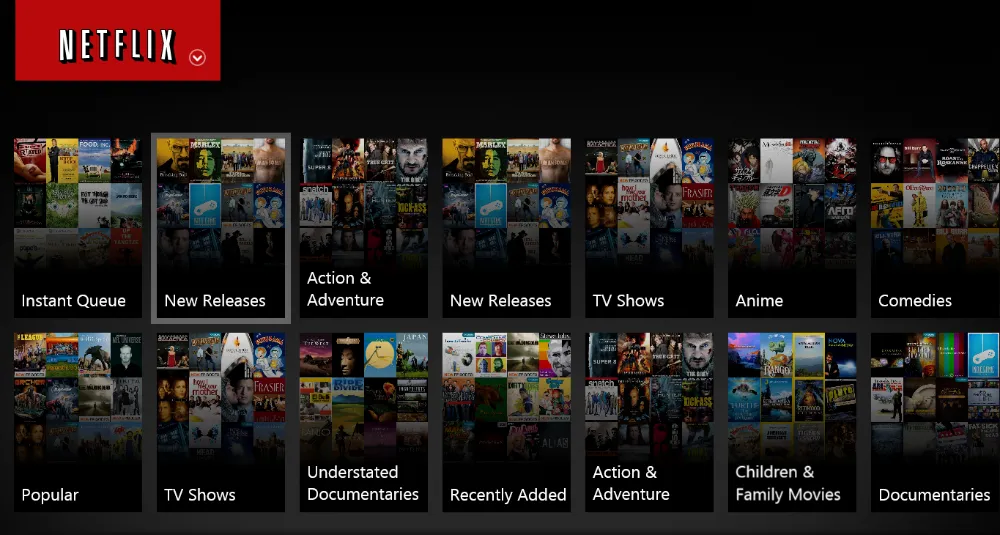
Netflix’s Topic-Tagged Content in Action (Source)
Media platforms like YouTube often need to create accurate subtitles and captions for their videos. To help AI systems do this automatically, audio needs to be carefully labeled with word-for-word transcriptions and tags. This is done using Automatic Speech Recognition (ASR), which helps teach machines to understand and extract text from speech.
While pre-trained ASR models perform well, they can sometimes cause mistakes or bias. That’s why properly labeling speech data is important. It helps these AI models better understand real-world language, recognize different ways people speak, and reduce errors.
Once a trained ASR model extracts text from audio, Natural Language Processing (NLP) steps in to help the system understand the meaning behind the words. Speech synthesis (also known as text-to-speech or TTS) can also be used in these AI systems to turn text back into human-like speech (if needed).
By carefully annotating audio, we make speech-to-text models smarter and more reliable. In turn, smarter speech-to-text models lead to faster and more scalable captioning in multiple languages. This makes videos more accessible to a broader audience and improves features like voice search and content discovery.
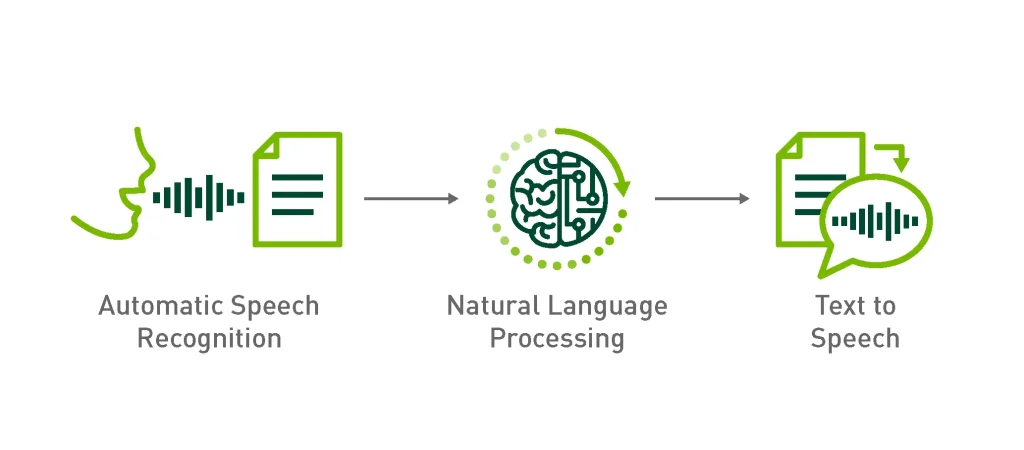
Labeling using speech data is crucial for video and audio analysis. (Source)
Images and videos are often labeled with tags about their quality, such as how sharp the picture is (resolution), how clear or blurry it looks (clarity), and how bright or dark it appears (brightness). These tags can be used to train AI models to identify low-quality images and automatically enhance media without much manual effort. For instance, if a video is too dark or blurry, AI tools trained on this labeled data can automatically brighten it, sharpen it, and make it easier to watch.
Interestingly, leading Hollywood studios are using AI systems to upgrade the quality of older films. AI can clean up noise, boost resolution to 4K or even 8K, and make sure the film looks great according to present-day standards.
A great example of this is movies like Avatar and Titanic, which were remastered into 4K with HDR and higher frame rates (HFR). The director, James Cameron, and his team used AI tools for upscaling, smoothing out grain, color correction, and frame interpolation to make the movies sharper and clearer, all without reshooting a single scene.

A Still From the Remastered Movie: Avatar. (Source)
Computer vision tasks like object detection and tracking can be used to identify people, objects, actions, and locations. Labels of objects can help AI systems understand what’s happening in each part of a video.
Specifically, using object detection and tracking, AI models can learn to track the movement of objects, spot when scenes change, and recognize how objects or characters interact with each other. Such techniques can support features like content-based search, scene-specific recommendations, highlight reel generation, and even interactive video experiences.
Scene and object detection are also crucial for handling huge media libraries. AI models can automatically tag videos with details like busy streets, soccer matches, or famous landmarks, making it much easier to search, organize, and use large collections. Instead of tagging videos manually (which is time-consuming), media companies can quickly find the right clips for making new content, suggesting videos to viewers, or letting users search by event or location.
BBC is an interesting case study of how an organization is using this technology. They’ve trained AI models to scan their massive archive and automatically tag scenes and objects like landmarks, faces, emotions, and activities across thousands of hours of news, documentaries, and shows. Now, editors, journalists, and even the public can search for specific news clips, like every clip showing the Eiffel Tower or a protest march.
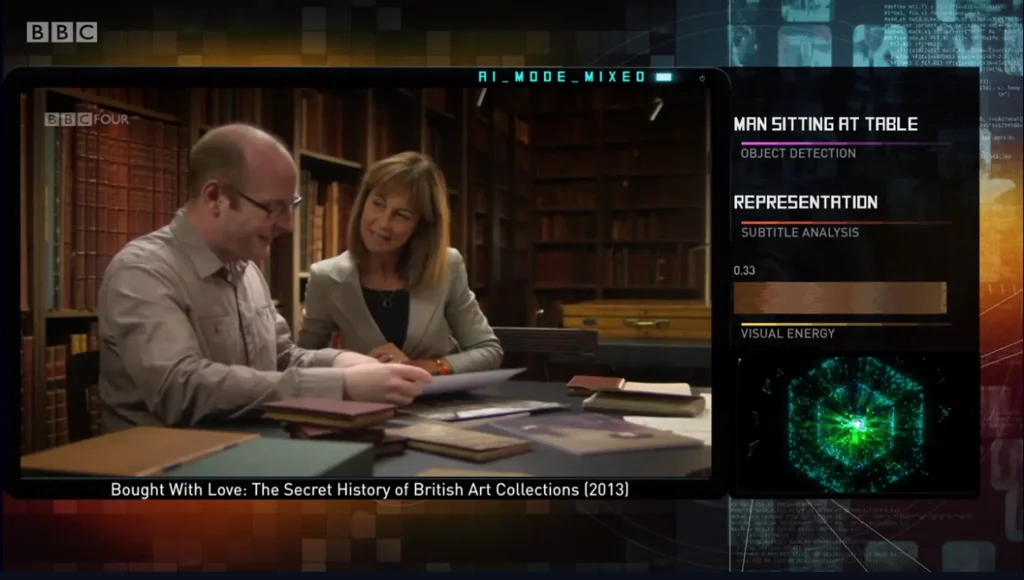
An example of using AI to analyze BBC video content. (Source)
Choosing the right video annotation tool is just as important as having a good dataset. As AI projects grow and become more complex, teams are looking for new platforms that can keep up with the need for speed, accuracy, and teamwork.
Here are a few important things to consider when choosing a video annotation platform:
Video annotation tools like TensorAct Studio are designed for high-speed video annotation tasks. TensorAct can support frame-by-frame tagging, tracking moving objects, segmenting scenes, and classifying content, even for large-scale projects.
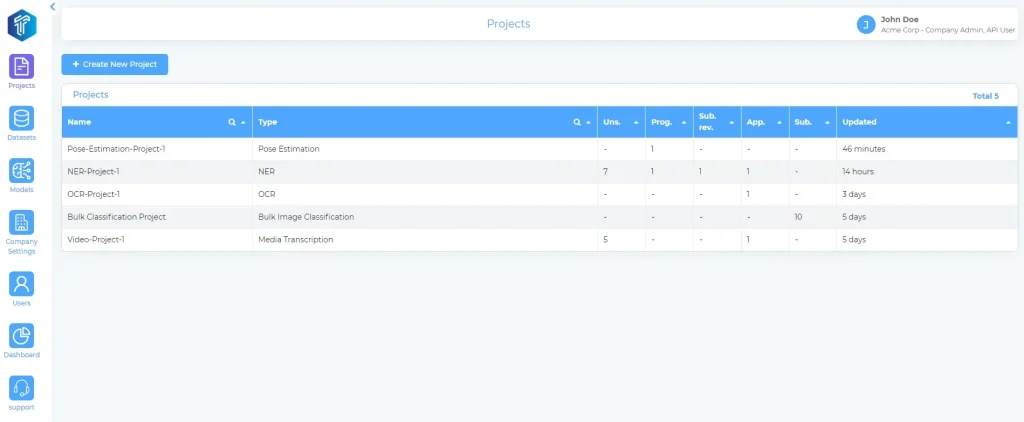
A Look Inside TensorAct Studio’s Interface. (Source)
TensorAct can also facilitate better team collaborations by letting you assign tasks, set roles, and track progress all in one place, keeping projects organized and consistent. It even supports active learning to label video clips automatically. In addition to this, the platform runs securely on the cloud, private servers, or fully on-site, with features like single sign-on and encrypted storage to protect sensitive content.
Now that we’ve gotten a better understanding of popular use cases and video annotation tools, let’s take a closer look at how video annotation actually works.
You can think of building a computer vision dataset like assembling a circuit board, where every connection must be accurate and purpose-driven. If one part is placed incorrectly or a wire is misaligned, the entire board can malfunction, just as poor data labeling can weaken an AI model’s performance.
Here are the general steps taken to build structured, high-quality data:
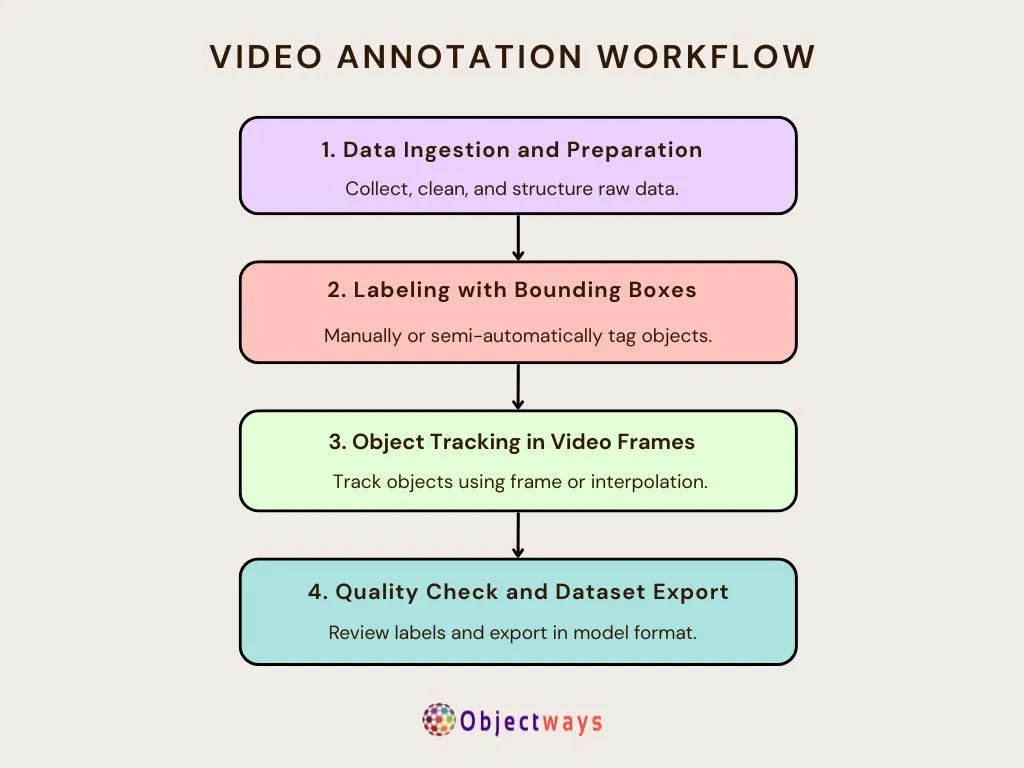
A Basic Video Annotation Workflow.
As AI innovations get smarter, the way we annotate visual data is also changing. It’s not just about drawing simple boxes around objects anymore. Now, annotators are also using 3D bounding boxes to show depth, and pixel-level tools like instance segmentation to separate objects that overlap. In some cases, keypoints are used, like body joints or facial features, kind of like dropping pins on a map to mark exactly where things are.
These advanced data annotation techniques don’t just teach AI models what something is – they help them understand how things move, behave, and interact with everything around them.
To keep up with this growing complexity, a lot of teams are using AI-driven tools that can speed up the process. These tools are similar to how your phone suggests the next word while you’re texting – it sees the pattern and gives you a head start.
On top of this, tools like AI-based frame interpolation can help fill in the blanks between frames, cutting down manual work. However, at the end of the day, humans-in-the-loop are still a critical part of reviewing everything to catch mistakes.
Selecting and setting up advanced video annotation tools is just step one; the next and most important step is deciding how you are going to create high-quality annotations across huge volumes of video data.
Without a clear plan, even the best tools can cause confusion. Following a few simple but best practices can help you and your team stay on the same page, avoid mistakes, and keep the annotation process running smoothly. Let’s take a look at some of them:
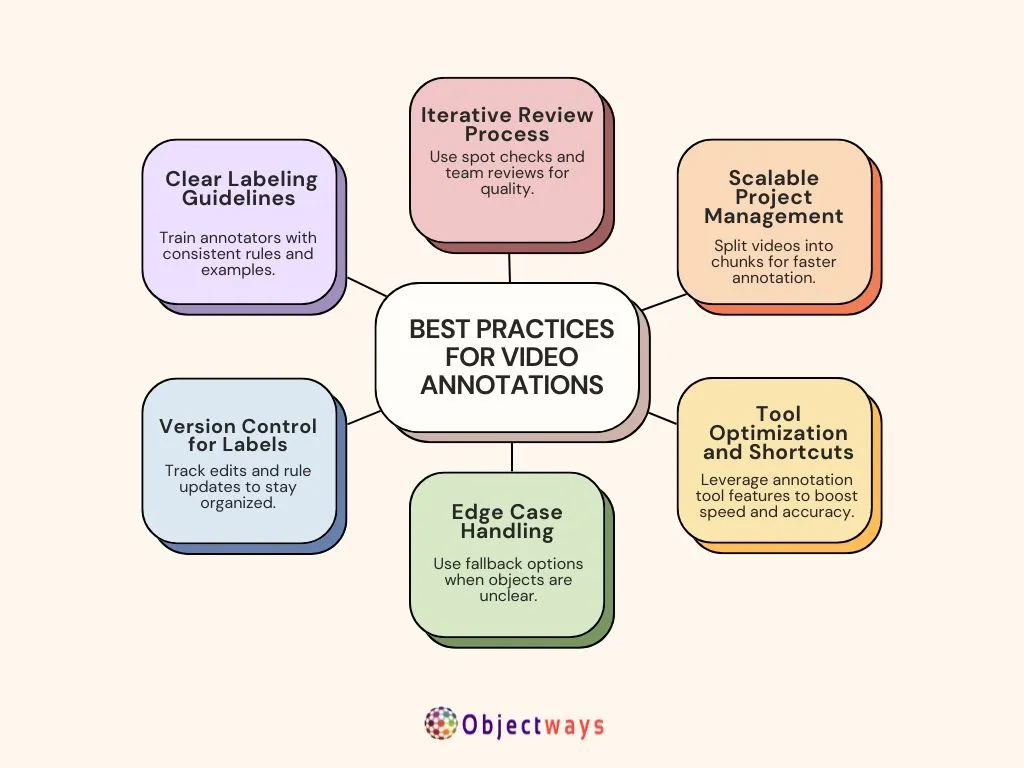
Best Practices for Video Annotations.
Working on video annotation can get tricky, especially when things like motion blur, bad lighting, or weird camera angles come into play. These issues can make it tough to spot objects clearly in each frame. When that happens, teams often have to take extra steps to make sure they’re not missing anything important.
Another common challenge is dealing with large video files or high frame rates. These can slow down annotation tools or create problems when breaking videos into individual frames. Teams need a solid plan to manage all that data without sacrificing speed or organization. It’s also important to strike a balance between working quickly and keeping the labels accurate, because rushing can lead to mistakes that might impact how well the final AI model performs.
That’s where experienced data annotators can make a big difference. At Objectways, we specialize in collaborating closely with teams by providing skilled annotators, optimized workflows, and human-in-the-loop support exactly when it’s needed most. If you’re looking to build AI models with video data, reach out to us, and we can help you move faster and get better results.
As AI is more widely adopted in various industries, the need for better and faster data labeling increases. It’s likely that in the future, industries like self-driving cars, security, and live video monitoring will rely on tools that can tag objects instantly as new video data comes in. Real-time annotation is becoming a key part of building impactful AI solutions.
Data labeling driven by AI tools is also growing fast. About 42% of large companies (with over 1,000 employees) are now using AI in their daily work, meaning that more sectors are making AI a core part of their operations.
High-quality video annotation can teach AI models to understand how things move and change in the real world. As video data becomes a more significant part of AI projects in the future, it’s important to have the right tools and methods to label it accurately. Using reliable video annotation software can make a substantial impact, helping teams work faster and smarter, especially on complicated AI projects.
If your team is handling large volumes of video data or needs help achieving better results, Objectways offers flexible tools and expert support to help you succeed. Whether you’re just starting out or aiming to improve your current process, contact us today!
An annotation is a labeled tag on an object within data, like drawing a box around a car in a video frame. It helps AI models recognize and learn from real-world elements.


Learn how computer vision for quality inspection helps detect defects, improve product accuracy, and maintain quality control in production lines.

Learn how computer vision in transportation enhances safety, efficiency, and sustainability through real-time traffic insights and smart mobility systems.
