Due to AI technologies like generative AI showcasing impressive results, it’s easy to assume that data challenges are a thing of the past. However, the reality is that trying to build an AI model without the right data can still be incredibly frustrating.
In some cases, you might have the data but not enough, which can end up bringing down the accuracy of your AI model. To solve these issues, new learning techniques like zero-shot learning and few-shot learning can be used.
Zero-shot learning makes it possible for AI models to use their previous experience to tackle tasks they’ve never seen before. It’s like an avid board game player who can quickly figure out the rules of a new game by drawing on insights from games they’ve played in the past. Others might need to watch a few rounds of gameplay before they get the hang of it. This is similar to few-shot learning. Few-shot learning helps AI models adapt quickly with minimal examples.
So, how do these learning mechanisms work? The basic idea behind zero-shot learning is teaching AI models to identify the similarities between different classes, the same way we humans notice differences naturally. On the other hand, few-shot learning trains the model on a small variety of similar tasks so that it learns how to learn. This way, when it faces a new task with only a few examples, it can still perform well.
In this article, we’ll explore both zero-shot learning and few-shot learning in more detail. We’ll also see how they both compare and when they can be used. Let’s get started!
Before we dive into looking at zero-shot vs few-shot learning, let’s walk through both machine learning paradigms separately.
Zero-shot learning is used in image and speech recognition systems to identify objects or sounds the model hasn’t seen or heard before. It’s also applied in natural language processing (NLP) tasks like translation and sentiment analysis. On top of that, recent research shows this technique has been used to build recommendation systems to suggest new items and autonomous vehicles to identify unknown road signs or obstacles.
Compared to most machine learning paradigms, zero-shot learning is unique because it aims to apply learned knowledge to predict unknown results without training. Basically, it’s like a seasoned chef creating a new dish on the fly by drawing on years of culinary experience, even without a set recipe.
Simply put, zero-shot learning works by the principle of using patterns and knowledge from what it has already learned. For example, if you’ve seen a horse but never a zebra, and someone tells you a zebra looks like a horse with black and white stripes, you’ll probably recognize a zebra when you see one.
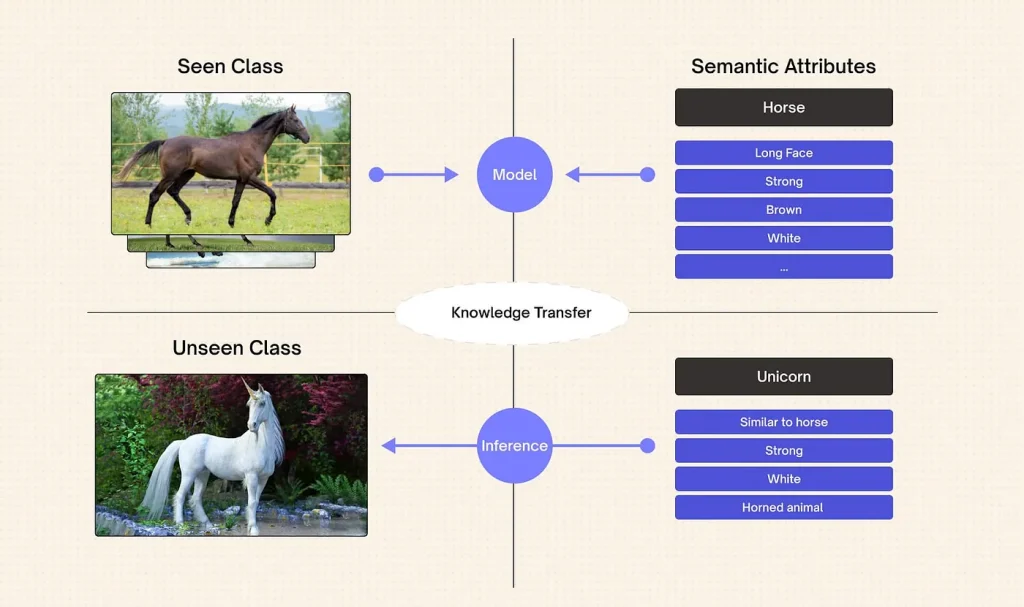
An Overview of Zero-Shot Learning (Source)
This leads to the question: How does zero-shot learning connect what the AI model has seen to what it hasn’t? It uses a technique called semantic embedding, which maps both known and unknown classes into the same space. When the model is trained on known classes, it learns how these classes relate to one another. Later, when the model encounters an unseen class, it uses this shared space to link the new class to the known ones and make a prediction.
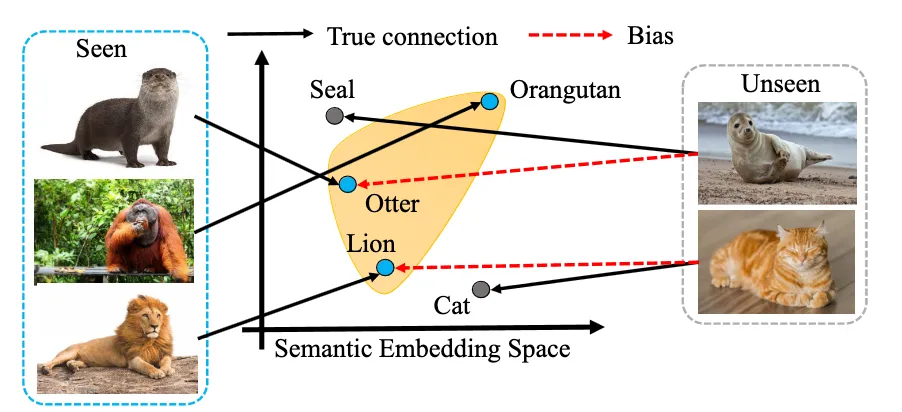
How Zero-Shot Learning Works. (Source)
An advantage of using zero-shot learning is that it reduces the need for labeled data by using what the model already knows to predict new unseen classes. It also helps AI models recognize patterns, spot unusual data, expand knowledge without retraining (which takes more resources), and even create art or music.
Despite these advantages, there are also certain drawbacks. It can be less accurate when handling complex tasks, depends on good-quality auxiliary information, and requires a substantial amount of computing power. Predictions can also be hard to explain and might reflect biases from the training data.
Another concept related to zero-shot learning is zero-shot prompting, and it is crucial for AI models like large language models (LLMs).
LLMs such as GPT-4o and Claude 3 can perform tasks in a “zero-shot” manner, helping them handle new tasks without examples. With zero-shot prompting, you can give the model direct instructions instead of showing it examples. The model uses what it has already learned to understand the prompt and respond correctly, even if it hasn’t seen that exact task before.
However, there are some challenges. If the prompt lacks clarity or context, the model might misinterpret it, similar to guessing game rules incorrectly without enough information.
Including some examples along with the prompt is a good solution to these challenges. That’s exactly what few-shot prompting does. Few-shot prompting helps the model improve by including a few examples in the prompt to guide its response.
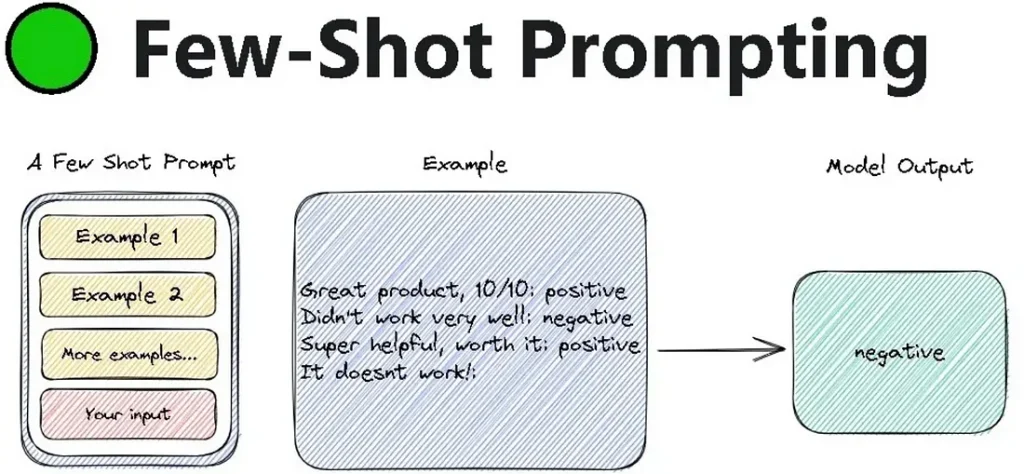
How Few-Shot Prompting Works. (Source)
Next, let’s take a look at few-shot learning in more detail.
Few-shot learning is used to teach a model to make accurate predictions with a minimal number of examples (training data). This differs from supervised learning, where a model learns from a large dataset before applying its knowledge to new data. It is helpful for applications like language translation, image classification, and anomaly detection.
In particular, few-shot learning focuses on understanding the similarities and differences between objects. It’s similar to a toddler watching you sort their toys into groups. After observing you separate the toys based on shape, color, or size, the toddler starts noticing which toys are alike and which are different, and soon, they’re able to sort them on their own.
How exactly does this work? First, few-shot learning uses an embedding module (a neural network like ResNet for images or BERT for text) to convert data into a set of features. Then, it creates prototypes by averaging these features for each class. Finally, when a new piece of data comes in, the model compares its features to the prototypes using cosine similarity – a way to measure how similar two sets of features are – to predict its class.
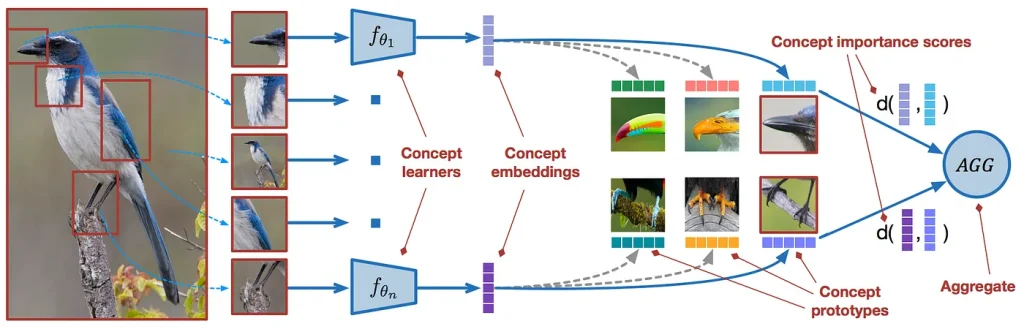
Understanding Few-Shot Learning. (Source)
For example, instead of training a model to recognize a cat or a dog specifically, the goal is to teach it how to tell animals apart based on their similarities and differences. After training, if you show the model two animal pictures, it won’t need to have seen those animals before; it will be able to tell if the animals in the image are similar or not based on the patterns it learned.
Here’s a closer look at how zero-shot and few-shot learning compare:
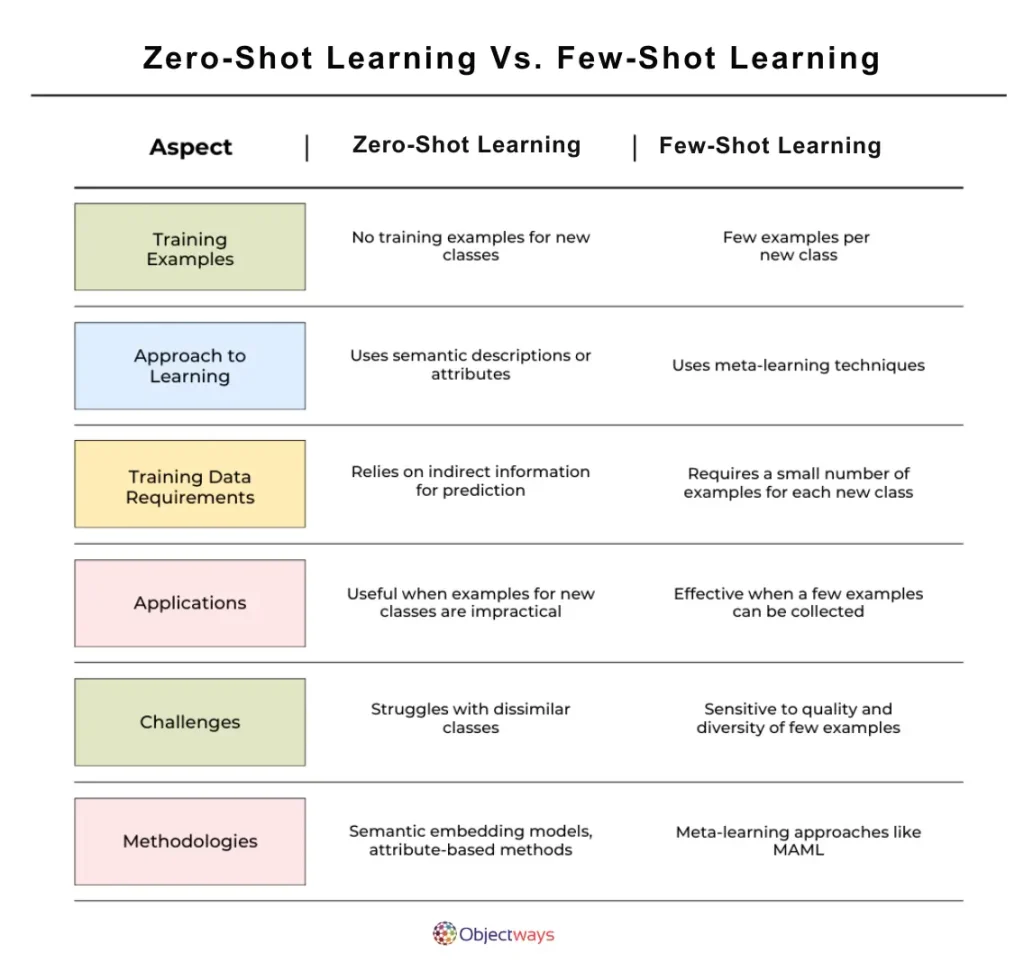
Zero-Shot Vs. Few-Shot Learning
A key reason to compare these two techniques is to understand when to use each one. The decision largely depends on factors like the nature of the task and the availability of training data for the AI model.
Zero-shot learning is useful when there are no direct examples for a new task, but the model can use related knowledge from similar tasks. It relies on patterns from previous data or extra information (like descriptions) to make predictions. This approach is the best choice if you don’t have any training data for your AI model. Examples of applications include translating a new language by using similarities to known languages, classifying new products using descriptive features, and identifying unseen objects based on their labels.
In contrast, few-shot learning is best used when only a small amount of training data is available. It allows the model to quickly improve and adapt by learning from just a few data points. For instance, an AI system that struggles to classify customer emails can perform better after seeing a few labeled examples.
As AI continues to evolve and make its way into nearly every industry, zero-shot and few-shot learning are vital concepts that are driving innovations. These techniques let us build AI models with very little data, making the whole process more flexible and efficient.
Consider a small business setting up an online virtual assistant. With few-shot learning, the model can start responding to customer queries after seeing just a few examples. Similarly, with zero-shot learning, the AI chatbot can even handle questions it hasn’t been directly trained on – like understanding slang or cultural references – without needing extra data.
Both zero-shot and few-shot learning play a key role in facilitating affordable AI solutions by reducing the need for larger datasets and making AI more accessible. Choosing the right learning approach for a specific AI application depends on weighing the pros and cons of each technique.
Also, combining zero-shot and few-shot learning with multimodal AI (which processes text, images, and audio) will likely make models more accurate and versatile, improving tasks like language processing and image recognition.
If you’re looking for the expertise to integrate such AI technology into your solution, you’re in the right place. At Objectways, we provide precise data labeling and custom AI solutions designed to boost performance across a range of applications. Whether you need zero-shot learning for broad, flexible understanding or few-shot learning for quick adaptation with minimal data, we have the expertise to meet your business needs.
Transform your AI strategy with our expertise. Contact us today.
Zero-shot learning predicts outcomes for new tasks without any direct examples by leveraging existing knowledge. In contrast, few-shot learning adapts quickly by using just a few labeled examples to learn new tasks.


Explore AI data governance and how quality, security, privacy, and availability in training data define the reliability and compliance of next-gen AI systems.

Explore what NVIDIA GTC 2026 revealed about physical AI, the data gap in robotics, and how egocentric data improves real-world performance.
