Recently, researchers at Toyota showed it’s possible for a humanoid robot to learn to walk on its own in just one to two hours. They never programmed it with step-by-step instructions.
Instead, it learned through trial and error, was rewarded for staying near a target speed, and was penalized whenever a foot slipped. With thousands of copies practicing in parallel in simulation, it picked up the skill remarkably fast.
This learning method is called reinforcement learning. Rather than telling a robot exactly what to do, engineers define a goal and a set of rewards. The robot then experiments with different actions and gradually learns which behaviors lead to success, all based on the rewards it receives.
A Look at Toyota’s Humanoid Robot Using Reinforcement Learning to Bounce a Basketball (Source)
Reinforcement learning in robotics is becoming crucial because many physical skills are simply too complex to program by hand. Walking, grasping objects, balancing, and moving through unpredictable spaces all involve countless variables that are difficult to consider in advance. Reinforcement learning lets robots pick up these skills from experience instead.
In this article, we’ll explore how reinforcement learning in robotics works and how robots learn from rewards and feedback. We’ll also look at why high-quality teleoperation and demonstration data are critical for building robots that can perform reliably in the real world. Let’s get started!
Similar to a baby learning to crawl through trial and error, robots can learn by interacting with their environment and adapting based on the results of their actions. This approach, known as reinforcement learning, enables robots to improve through experience rather than relying on a fixed set of instructions.
Typically, it involves a robot taking an action (directly or in simulation), observing the outcome, and receiving feedback in the form of a reward or penalty. Over time, it learns which choices lead to better results and adjusts its behavior accordingly.
The reinforcement learning process works by repeating actions that gain rewards. Actions that move the robot closer to its goal are reinforced, while actions that lead to failure become less likely to be repeated. Through thousands, or even millions, of attempts, the robot gradually develops a strategy for completing a task.
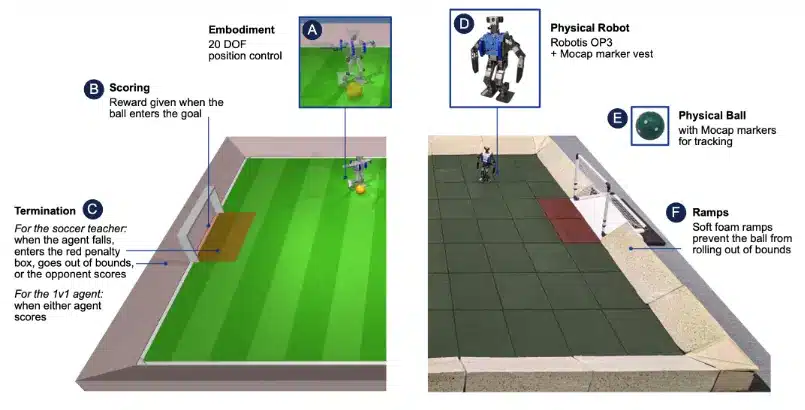
Researchers often use soccer as a testbed for reinforcement learning applications in robotics because it combines many of the challenges robots face in the real world, especially handling a wide variety of motions.
An interesting example is DeepMind’s 2023 research on robot soccer. They used reinforcement learning to teach a humanoid robot how to walk, chase a ball, recover from falls, and score goals. By training using millions of simulated interactions, the robot gradually learned these individual skills and combined them into a complete soccer-playing strategy.
The robot first practices through trial and error in simulation (left), then the learned skill is transferred to the physical robot in the real environment (right). (Source)
Reinforcement learning in robotics follows a simple feedback loop. The robot observes its current situation, takes an action, receives a reward or penalty based on the outcome, and then adjusts its behavior. By repeating this cycle, the robot gradually works out which behaviors bring it closest to its goal.
Most of this type of robot learning takes place in simulation rather than on physical hardware. This is because training a real robot in real space through trial and error can be slow, expensive, and sometimes risky.
On the other hand, virtual environments let robots practice far faster and more safely, while experiencing scenarios that would be difficult or costly to recreate in the real world. For example, in Toyota’s 2026 demonstration, thousands of virtual copies of the same humanoid robot were trained simultaneously, speeding up the whole process.

Toyota’s Humanoid Robot Improved Over the Course of Training (Source)
However, there is a catch. Success in simulation doesn’t guarantee success in the real world. Real environments are unpredictable. Researchers refer to this as the sim-to-real challenge. It is key to ensure that skills learned in simulation continue to work reliably when transferred to a physical robot.
Another critical component of reinforcement learning in robotics is the reward function, which defines what success looks like. Rewards may be given for maintaining balance, reaching a goal, or completing a task efficiently. A well-designed reward encourages desired behaviors, while poorly designed rewards can lead robots to exploit loopholes and maximize rewards without truly solving the task.
Although reinforcement learning lets robots learn from experience, learning entirely on their own can take a long time. Real human demonstration data (recordings of a person performing the task, used to show the robot what success looks like) helps speed up the process.
A robot with no prior knowledge has to explore every possibility at random, making countless mistakes before it discovers even basic skills. For complex tasks, this trial-and-error process can be lengthy.
To speed up learning, robots can learn from human demonstrations. One common approach is teleoperation, where a person controls the robot while its movements and sensor data are recorded. These demonstrations show the robot how to perform a task successfully, giving it a strong starting point and cutting down the trial and error it would otherwise need.
An advantage of teleoperation data is that it’s recorded directly on the robot being trained, so the movements already fit the robot’s body. Whereas other robotics data, like motion-capture data, is captured from a person, so it has to be retargeted to the robot before it can be used.
Most cutting-edge robot learning systems today combine demonstrations with reinforcement learning. Demonstrations provide an initial foundation, while reinforcement learning allows the robot to refine its skills through experience and often improve beyond the original examples.
A well-known example is Google’s QT-Opt system, which used reinforcement learning and more than 580,000 real-world grasp attempt demonstrations to train robotic arms. Through repeated practice, the robots learned advanced behaviors, including recovering from slipping objects, repositioning items for easier pickup, and adapting to unexpected disturbances.

Google’s QT-Opt system trains robotic arms to grasp objects through repeated practice. (Source)
We’ve seen that human demonstrations are impactful, but how do they actually work alongside reinforcement learning? Instead of turning a robot loose to learn everything on its own, engineers usually seed it with demonstrations first, examples of the task done right, before reinforcement learning takes over.
For instance, consider a robot stationed beside a conveyor belt, picking up packages as they roll past and placing them onto a sorting shelf. This is what’s known as a pick-and-place task, where the robot has to identify each package, grasp it, and move it to the right spot. Harder tasks, like bagging groceries, raise the bar further, since the robot has to handle multiple items and perform each step in the correct order.

An Example of a Robot Picking Up a Package (Source: Pixabay)
To collect the data for a task like this, a human operator controls the robot through teleoperation while cameras and sensors record everything. Along with video, the system captures the robot’s state, things like joint positions, gripper movements, and force measurements.
These recordings train an initial policy that imitates successful behavior. Reinforcement learning then refines that policy through practice, helping the robot improve beyond what the demonstrations showed.
The quality of that data is critical. If different operators perform the same task in different ways, say, one reaching for each package from above and another from the side, the robot gets conflicting signals about what success actually looks like. That inconsistency slows training and leads to less reliable performance.
Not every recorded demonstration is worth keeping, either. Some have failed grasps, incomplete runs, sensor glitches, or timing problems. So development teams spend a good chunk of time cleaning up their datasets before training, tossing out the runs that just aren’t good enough.
Reinforcement learning for robotics is often described as a problem of learning, but it is just as much a problem of data quality. Even the most advanced algorithms can struggle if the demonstrations they learn from are inconsistent, incomplete, or poorly recorded.
Creating useful training data requires a consistent data collection process. Robot demonstrations are typically recorded from multiple camera angles while capturing robot state information such as joint positions, gripper movements, and force measurements. These data streams must be accurately synchronized and sensors properly calibrated to ensure the robot learns from reliable observations.
Collecting the data is only the start. The raw recordings then need to be annotated, with the useful segments labeled, successful actions marked, objects and grasp points identified, and failed or low-quality episodes flagged for removal.
This labeling or data annotation process is what turns hours of raw footage and sensor logs into structured examples a robot can actually learn from. Teams also review demonstrations for failed attempts, missing sensor data, synchronization problems, and other errors that could confuse the learning process. In many cases, removing poor-quality examples improves performance more than collecting additional data.
Once a policy has been trained, the next challenge is validation. The robot has to be tested on real hardware and across a variety of conditions to confirm that it can perform the task reliably. If performance falls short, the root cause may be the demonstrations, the quality of the data, the reward design, or the training process itself.
Ultimately, data shouldn’t be considered complete simply because it has been collected. The true measure of quality is whether it enables the robot to perform consistently in the real world.
Reaching that reliability consistently is hard, which is why many robotics teams turn to specialists rather than running the whole data pipeline in-house. The right data partner handles collection, annotation, and validation, turning raw demonstrations into training-ready data far more reliably.
Objectways was built to be that partner. We treat teleoperation data as a pipeline with quality gates, not a one-time recording session. Every dataset moves through collection, scoring, filtering, annotation, and validation in a fixed order, and if a stage doesn’t clear its quality threshold, the work stops and gets fixed rather than passed along.
Here are a few of the steps we take that make the biggest difference, the ones teams often overlook:
We then validate the finished dataset by training a policy on it and testing it on real hardware. The result is clean, validated data that can bootstrap policies, accelerate reinforcement learning, and hold up in the real world.
Reinforcement learning for robotics is redefining how robots learn complex skills. Rather than relying solely on hand-coded instructions, robots improve through experience, using rewards and feedback to refine their behavior. In these robotic training settings, high-quality human demonstrations often provide the foundation that makes reinforcement learning efficient and reliable.
As robots take on more advanced tasks in warehouses, factories, homes, and other real-world environments, the combination of reinforcement learning and well-curated demonstration data is essential. The most successful robotic systems will be built on powerful learning algorithms and clean, consistent, and high-quality training data.
Want help building the data behind your next physical AI or robotics project? Our team at Objectways would love to talk.
Reinforcement learning is an alternative approach to manually coding robots that instead optimizes the strategy (i.e., the controller or policy) through trial-and-error in a simulator.


Discover how warehouse robots learn from teleoperation data to handle real-world warehouse automation

Learn what a mocap suit is, how wearable motion capture works, and why suit-captured movement has become crucial training data for robots
