As humans, we go through thousands of movements every day without thinking about them. Climbing a staircase, pouring a glass of water, or catching a set of keys all involve constant adjustments in balance, timing, and muscle coordination that happen unconsciously.
For robots, that same coordination is hard to achieve. For instance, take the Ghost Rabona, a cross-leg trick soccer kick that takes serious balance to land. Ahead of the FIFA World Cup 2026, Boston Dynamics’ humanoid robot Atlas pulled it off, but it didn’t learn the move on its own.
Researchers first used a motion capture system to record a real soccer player performing the kick. They then retargeted that movement to fit Atlas’s body, since a robot’s joints and range of motion differ from a human’s, and used reinforcement learning to let Atlas practice it thousands of times in simulation.

Atlas Performing the Ghost Rabona Kick (Source)
So before any of that training began, everything started with recording exactly how a human moves. That recording process was done using motion capture technology, or mocap.
The same idea applies far beyond a trick kick. Movements that feel natural to us often take a lot of training before a machine can do them reliably, so engineers are increasingly turning to human demonstrations.
There are a few ways to capture those demonstrations, and one of the most detailed is mocap, which tracks the exact position and movement of a person’s body and turns it into structured motion capture data robots can learn from. As robots move into factories, warehouses, hospitals, and public spaces, teaching them physical skills is becoming critical.
Motion capture is one key way to bridge the gap between how humans move and how robots learn. Let’s explore how motion capture works, the technologies behind it, and why it’s becoming an important part of next-generation robotics and physical AI.
Motion capture, commonly known as mocap, is the process of recording how a person moves and converting it into structured digital data. Instead of capturing what a movement looks like, it tracks the exact position and motion of the body over time, producing data that machines can analyze and learn from.
An interesting example comes from researchers at Stanford University, who used Rokoko Smartgloves to capture detailed hand-motion data for training autonomous robots.
The system recorded how human hands approached, grasped, and manipulated objects, creating a mocap dataset that robots could learn from. Rather than simply observing a task, a robot can learn from the movements that made the task possible.

Human Demonstration Captured and Replicated by a Robot (Source)
That movement data doesn’t come from a standard video recording. Mocap systems use specialized cameras, wearable sensors, markers, or markerless computer vision systems to track movement with a high degree of precision. Depending on the setup, they can capture information such as joint positions, limb angles, movement trajectories, and timing.
The main difference between video footage and motion capture is the type of information they record. A video captures what an action looks like, while mocap captures how that action is performed.
A camera may show a person picking up an object, but motion capture reveals how the shoulder, elbow, wrist, and fingers moved throughout the task, including the position, trajectory, and timing of each movement. That level of detail is what makes motion capture technology impactful for robotics and embodied AI systems.
Motion capture works by tracking how different parts of a body move through space and converting those movements into digital data that computers can analyze.
While the exact setup can vary, the overall process follows a few basic steps. Here’s a quick look at how it works:
Through these steps, a mocap session produces more than a visual record. It generates structured data, such as joint angles, motion paths, and precise timestamps, that tie each position to a specific moment in time.
For example, researchers have used motion capture systems to record the position, orientation, and movement patterns of surgical instruments during laparoscopic procedures, creating mocap data that could be analyzed for training and skill evaluation.
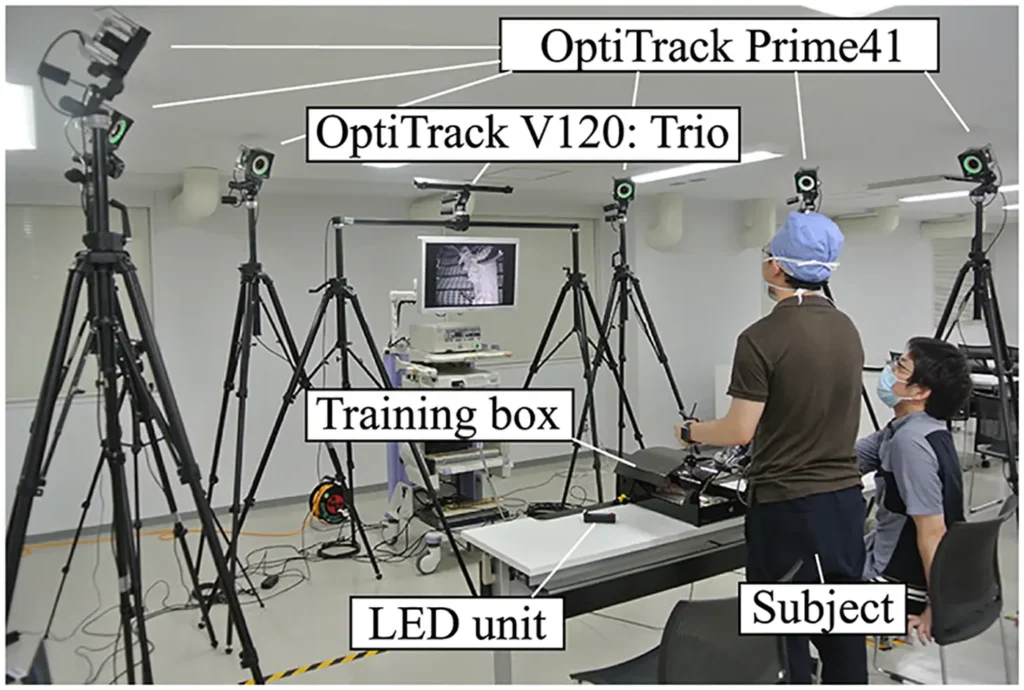
An Optical Motion Capture System Used to Record Surgical Instrument Movements (Source)
Capturing this type of data can involve various types of mocap systems. Some rely on external cameras to track motion from the outside, while others use wearable sensors that record movement directly from the body. Both capture detailed motion data but differ in how they collect it and which environments they suit best.
Motion capture isn’t a one-size-fits-all technology. There are several ways to capture human movement, and each approach offers different advantages depending on the environment, level of accuracy required, and intended application.
In robotics, the type of mocap system used affects both the quality of the movement data collected and how practical it is to deploy in real-world settings.
Next, let’s look at some common mocap approaches.
Marker-based optical mocap is one of the most precise ways to capture motion today.
In this method, reflective markers are placed on key points of a person’s body, and a network of cameras tracks those markers as the person moves. By recording their positions frame by frame, the system captures highly accurate movement data.
This precision makes optical mocap useful in robotics applications where accuracy is critical. In one example, an AR-based robot programming system used a laser-based optical setup to track a handheld teaching device as an operator guided an industrial robot through complex tasks. Those movements were then turned into robot-executable instructions, letting the robot learn directly from a human demonstration.
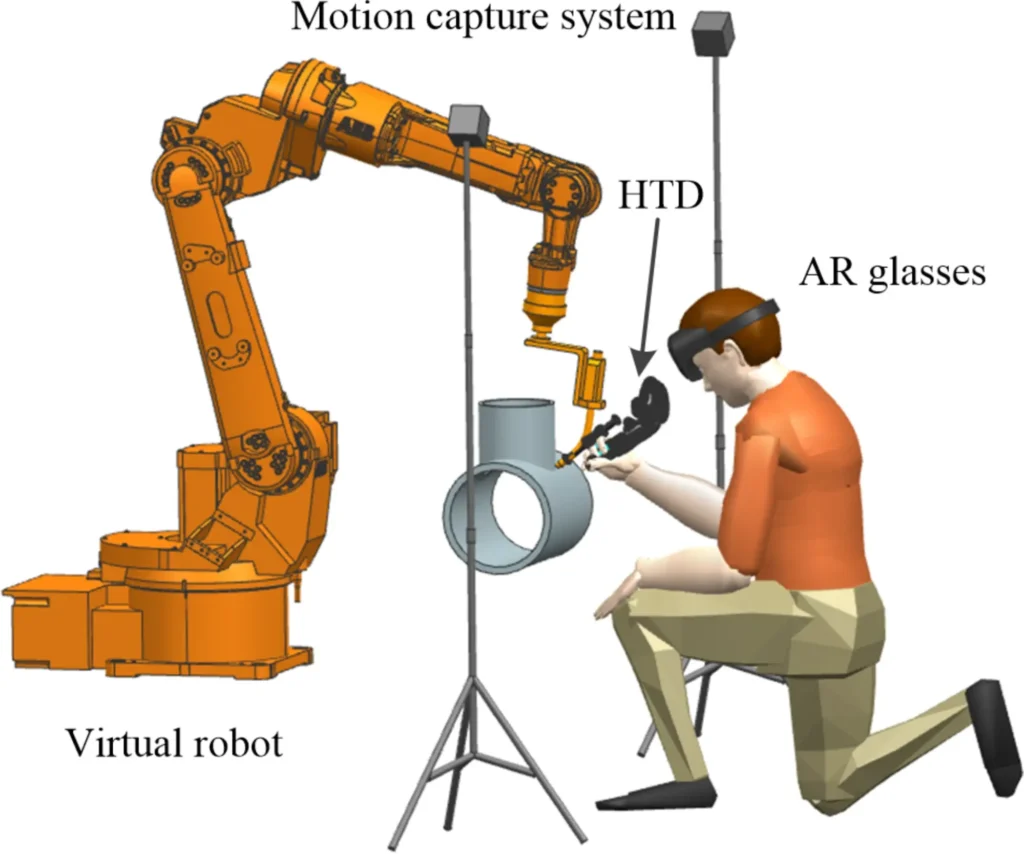
Teaching an Industrial Robot Through Motion Capture (Source)
The tradeoff is the setup. These systems need a controlled environment, careful camera placement, and consistent lighting. They’re also prone to occlusion, where tracking breaks down if something blocks the markers from the cameras’ view.
Markerless optical mocap removes the need for physical markers entirely. Computer vision and AI algorithms analyze video footage to estimate the positions of body joints and their movement, without any sensors attached to the person.
The process is relatively straightforward. Multiple cameras capture a person from different angles. AI models identify key body points in each frame, and these detections are combined to reconstruct movement in three-dimensional space.
Research has shown that this approach can scale to real applications by using deep learning-based pose estimation across multiple synchronized camera views to build a fully automated markerless motion-capture workflow. The system reconstructs 3D joint positions and produces lower-limb joint angle measurements that closely align with the accuracy range of traditional marker-based systems.

Markerless Motion Capture Used to Reconstruct a 3D Skeleton. (Source)
While the performance of these systems can be affected by lighting conditions or body occlusion, markerless systems require a simpler setup than marker-based approaches. This makes them practical for capturing movement outside controlled studio environments.
Meanwhile, inertial mocap systems take a completely different approach. They use wearable sensors called inertial measurement units (IMUs) attached directly to the body. These sensors measure acceleration and rotation at each joint, building a continuous record of movement in real time.
A mocap suit places these IMU sensors at key points across the body, including the shoulders, arms, legs, and feet. More broadly, the suit is what holds sensors or markers in place in any mocap setup, whether the system uses cameras or wearable IMUs. The technology changes, but the suit’s job stays the same: keeping everything positioned so the body’s motion is captured accurately and consistently.

A Mocap Suit with IMU Sensors Used to Track Full-Body Movement (Source)
Since tracking doesn’t depend on cameras, motion can be recorded in a wide range of environments, including outdoor and industrial settings. To maintain consistency during longer sessions, the system is periodically recalibrated to keep the motion data aligned throughout the capture process.
What if you didn’t have to choose between the precision of cameras and the freedom of wearable sensors? That’s the idea behind hybrid motion capture systems, which combine inertial and optical tracking to capture movement more reliably across a range of conditions.
Optical cameras track precise body positions when everything is in view, while IMU sensors continue recording motion even when parts of the body move out of sight. Together, they help maintain both accuracy and continuity in the recorded movement.
This combination is especially useful for complex actions where the body is constantly changing position or moving across different spaces. Instead of relying on a single tracking method, the system fills in gaps from one source using data from the other, creating a more complete motion record.
For years, motion capture has been a staple of film, animation, video games, and sports biomechanics, used to build realistic digital characters and to break down human movement with precision.
Now it’s taking on a bigger role in robotics and physical AI. As robots move out of controlled labs and into warehouses, hospitals, construction sites, and homes, teaching them physical skills matters more than ever.
Programming every possible movement by hand isn’t practical, and rule-based systems fall apart when conditions change. What robots really need is a direct reference for how tasks are done in the real world, and captured human movement gives them exactly that.
That shift is changing how motion capture is used and what kind of data matters most. So, how does that captured movement actually become something a robot can learn from?
It comes down to how the data is structured. Mocap doesn’t just show what a movement looks like; it records the precise mechanics behind it, giving robots a reference they can actually train on.
Unlike language models, which can learn from huge amounts of internet text, robots need real demonstrations of physical skills. Actions such as balancing, grasping, and coordinated movement can’t be learned from just documents. Mocap is one of the most precise ways to record those demonstrations.
What makes it so useful is that it captures the mechanics behind a movement, not just the end result. It records joint movements, positional changes, and timing, giving robot learning systems a structured reference for how a skill is performed. This data can then be used as a foundation for reinforcement and imitation learning.
The Atlas Ghost Rabona is a good example. Motion capture data from professional footballers was retargeted to Atlas’s body and used as the starting point for reinforcement learning in simulation. From there, Atlas worked out its own balance, coordination, and force transfer through repeated practice. The mocap data set the initial reference, but the robot learned to perform the skill on its own.
That mix of precision and consistency is what makes mocap so valuable. Video data shows what a task looks like, and teleoperation data records how a robot was guided through one, but mocap captures the detailed movement data needed for fine, full-body actions.
As robots take on harder tasks, that kind of high-quality motion data is becoming a real bottleneck. In a lot of cases, building better robots comes down to building better datasets of human movement.
Here are some common challenges teams face when working with mocap data:
Solving these challenges takes more than the technology itself. Teams also need dependable workflows for data collection, quality assurance, and validation.
At Objectways, we support these workflows through structured data operations that help organizations prepare high-quality motion datasets for robotics and physical AI applications.
Building reliable physical AI systems starts with high-quality movement data, and that’s exactly what Objectways delivers.
We collect and annotate motion capture data alongside other robotics data types, including teleoperation, egocentric, UMI gripper, and RGB-D data. That makes us a single data partner for the full range of training datasets smart physical AI systems need.
One of our key strengths is multimodal data alignment. Motion data, visual inputs, depth information, and sensor signals have to be synchronized accurately to create datasets that support effective robot learning. Every dataset we produce goes through expert human review and robotics-grade quality control to ensure accuracy, consistency, and scalability across projects of any size.
Whether you’re building humanoid robots, autonomous mobile robots, or robotic manipulation systems, we deliver training-ready datasets that hold up in real-world deployment. Reach out to our team to talk through your motion capture data needs.
Motion capture turns human movement into a structured reference that robots can learn from. Whether it’s a World Cup trick kick or a task on a factory floor, the process starts the same way. A human performs the action, motion capture records it, and that data becomes the foundation for robot learning.
As physical AI systems become more capable and move into increasingly complex environments, mocap is becoming an important part of the broader robotics data stack. Alongside teleoperation, egocentric data, and sensor data, it helps provide the high-quality movement data that robots need to learn and adapt in the real world.
Motion capture is used to record the movement of people or objects and convert it into digital motion data. It is widely used in film, animation, and video games to create realistic character movements. Beyond entertainment, mocap is also used in sports analysis, healthcare, and robotics, where detailed movement data helps train AI systems and study how tasks are performed in the real world.


Discover how warehouse robots learn from teleoperation data to handle real-world warehouse automation

Learn what a mocap suit is, how wearable motion capture works, and why suit-captured movement has become crucial training data for robots
