

1. Fit Your Object Detection Dataset to Your Project Domain
An object detection model generally will perform best when it’s trained on data that reflects the environment it’s going to be used in. That means using labeled examples from places like busy streets, retail stores, warehouses, or indoor settings - wherever the model needs to make decisions in the real world.
For instance, the MS COCO dataset includes over 300,000 labeled 2D images of everyday objects like people, vehicles, and household items. It’s widely used for general-purpose object detection tasks such as product recognition or pedestrian tracking. However, since it lacks in-depth information or sensor data, it’s not ideal for applications that require spatial understanding.
The nuScenes dataset, on the other hand, is built specifically for autonomous driving. It provides 3D annotations and multi-sensor data from cameras, LiDAR (measures distance using laser pulses), and radar, which uses radio waves to detect object speed and position. These inputs give the model a deeper understanding of depth, motion, and spatial context.
It includes detailed HD maps that provide rich contextual information such as road layouts, traffic signs, and lane boundaries. This makes nuScenes ideal for training models that operate in dynamic environments.
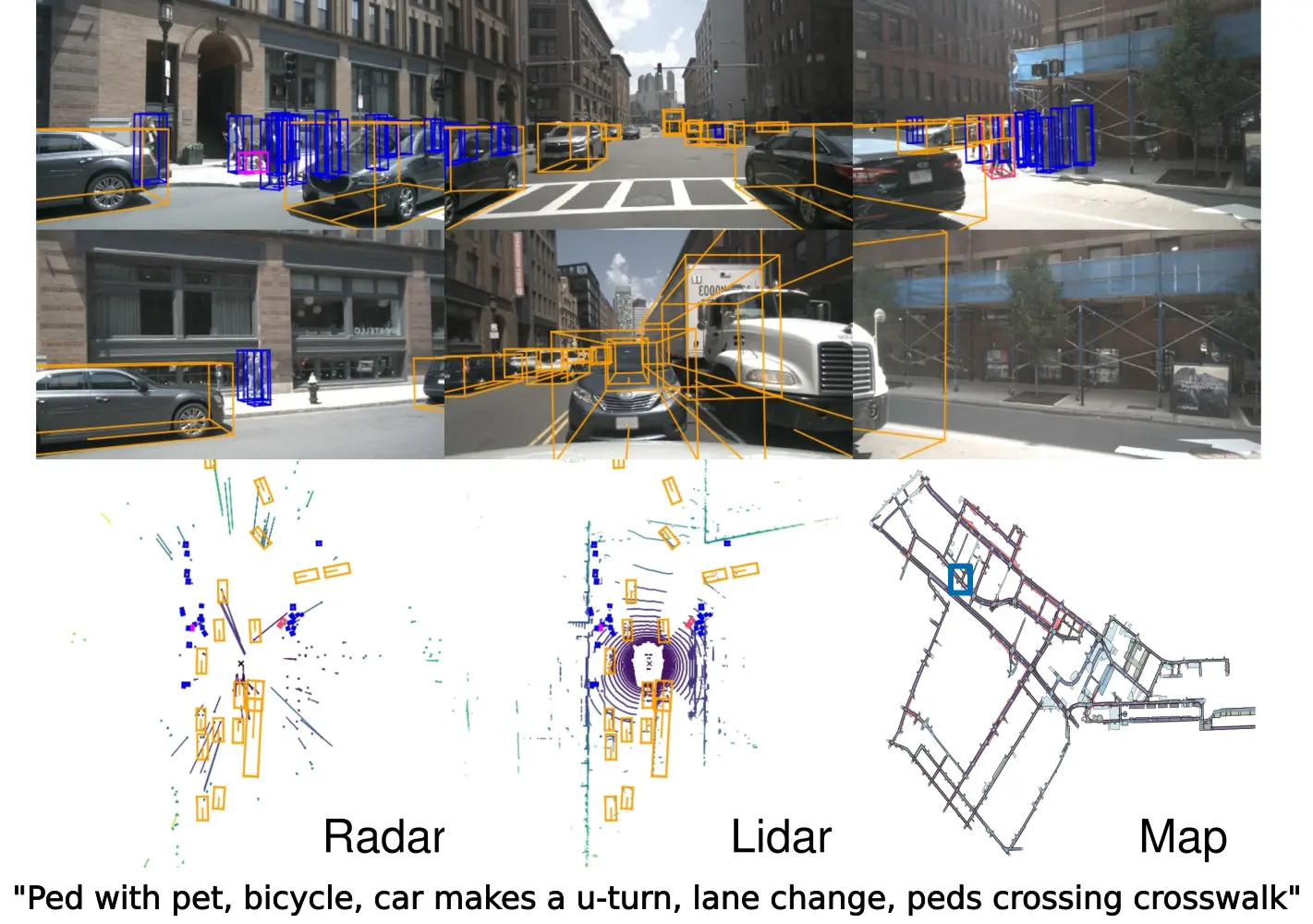
A Look at the nuScenes Dataset for Autonomous Driving. (Source)
2. Consider Bounding Box Types and Label Quality
When it comes to object detection, bounding boxes are used to mark the location of objects within an image. The accuracy and annotation type plays a key role in how well the model learns. Most datasets use 2D bounding boxes, which draw rectangles around visible objects. It works well for many use cases, but in more complex environments, like drone footage or self-driving cars, rectangles may not be enough.
Some applications require more than just simple object location; they also need information about shape, orientation, and spatial positioning. In these cases, alternative bounding box formats like 3D and oriented boxes offer better spatial context.
3D bounding boxes include depth and rotation, helping models understand how far objects are and how they are positioned in space. Oriented boxes capture the angle of objects, which improves precision in aerial imagery or when objects are tilted or off-axis.
Besides the type of box, the quality of your labels is crucial. Things like missing objects, sloppy box placement, or incorrect labels can confuse the model and hurt performance. On the flip side, clean and consistent annotations help your model learn the right patterns and make better predictions.
The KITTI dataset is a good example of high-quality annotations that use 2D and 3D bounding boxes. It includes objects such as cars, pedestrians, and cyclists. Each label contains object dimensions, position, orientation, occlusion level, and truncation status.

2D and 3D Annotations from the KiTTi Dataset. (Source)
3. Assess the Object Detection Dataset Size
The size of your dataset can have a big impact on your model’s performance and your workflow. Larger datasets usually help models learn more general and flexible patterns because they include a wider variety of objects and scenes. But they also take more time, storage, and computing power to train.
Smaller datasets are easier to manage and faster to work with, which makes them great for early development or when resources are tight. The right size really depends on what your model needs to do and the tools you have to train it.
Large-scale datasets like Objects365 offer over 2 million annotated images across many categories. These datasets are used to train models for high-accuracy detection in varied scenarios. These models often perform well in new categories, even without additional fine-tuning. This makes them useful for open-world detection or zero-shot learning tasks.

Models Trained on Objects365 Can Detect New Objects without Fine-Tuning. (Source)
In contrast, small datasets like the Oxford-IIIT Pet Dataset contain about 7,400 images covering 37 pet breeds. It provides bounding boxes and pixel-level masks with clean annotations, making it a good fit for quick testing, prototypes, or learning projects where you want clean data but don’t need massive scale.
4. Use the Right Type of Data for Your Task
In computer vision, modality refers to the type of data your model processes, such as red, green, and blue (RGB) images, thermal imagery, depth maps, LiDAR, or radar. Each one captures different details about the environment, so it’s important to pick a dataset that matches how your model will be used in the real world.
For many object detection tasks, standard RGB images are enough. But in more specialized situations, like detecting people at night, inspecting equipment in low-light conditions, or helping in search and rescue, RGB alone might not cut it. That’s where thermal or infrared data comes in. It can pick up on details that normal cameras miss.
A great example is the FLIR Thermal Dataset, which has over 26,000 labeled images showing vehicles, pedestrians, and traffic signs, all captured using thermal cameras. It combines thermal and visible data, giving models a better chance to detect objects in tough conditions like darkness, glare, or fog.

An Example of Thermal Object Detection. (Source)
5. Check the License, Updates, and Support Around the Dataset
A good dataset isn’t just about the images and labels - it’s also about how it’s licensed, maintained, and supported. These often overlooked details can have a big impact on how easy (and legal) it is to use the data in your project.
Licensing governs how freely you can use and share the data, directly impacting whether a dataset is suitable for commercial use or limited to research. Active maintenance and documentation are equally important; they keep the dataset relevant, accurate, and aligned with evolving technologies and use cases.
Selecting an open-source dataset with clear licensing, active maintenance, and a well-supported ecosystem can accelerate development cycles and keep your model reliable over time.
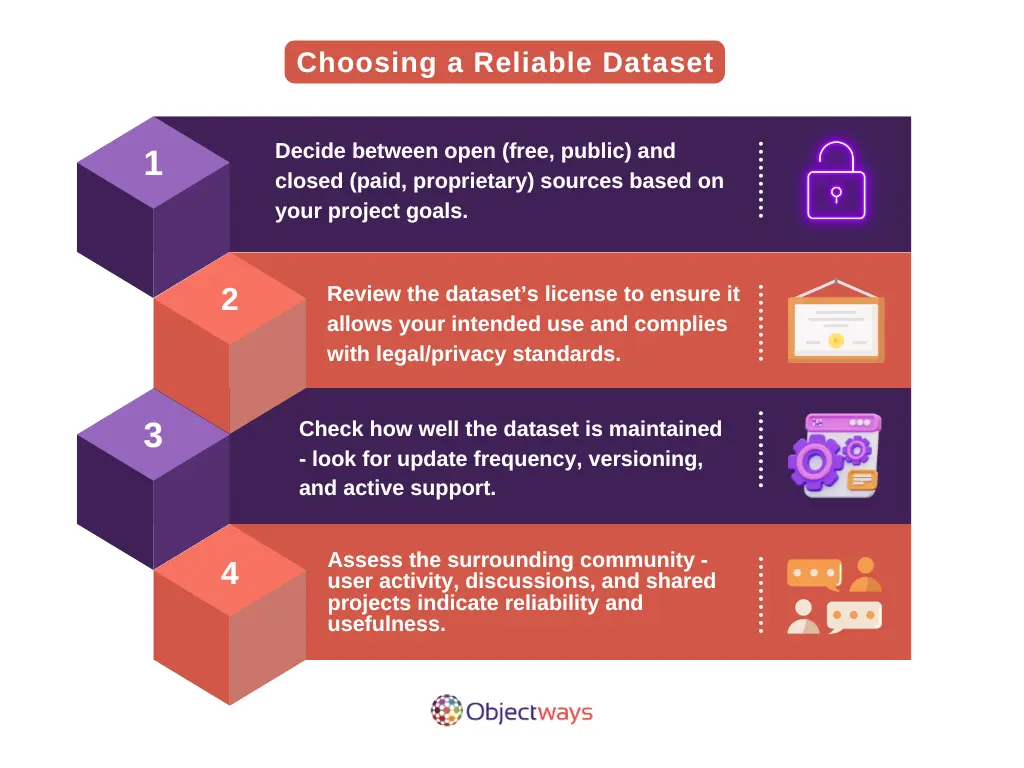
Choosing a Reliable Object Detection Dataset
How Objectways Helps You Get the Right Dataset
Building a reliable AI model starts with selecting the right dataset, but that’s often where teams get stuck. There’s not always enough time to compare options, check label quality, or sort out licensing and readiness for production.
That’s where we can step in - Objectways works closely with AI teams to remove these obstacles. We help select or create datasets that align with specific project goals and deployment needs.
Every dataset we deliver is carefully sourced, clearly labeled, and tested to make sure it performs well in the real world. We handle everything, from checking annotations and formatting the data to supporting different input types like images, thermal scans, or point clouds.
Beyond data sourcing and annotation, Objectways also supports end-to-end AI development. We help with everything from model training and deployment to more specialized needs like content moderation and generative AI solutions.
The Right Dataset Can Make All the Difference
State-of-the-art model performance results from using the right combination of algorithms and well-matched data. The best datasets are the ones that truly fit your project’s goals, domain, and real-world conditions.
Taking the time to evaluate your options carefully matters because default datasets often aren’t the best fit for every use case. Since no single dataset works for every project, it helps to explore your options or team up with experts who can provide data that’s tailored to your use case. For instance, at Objectways, we create high-quality, well-annotated datasets that are built to support real-world AI applications and empower your models to perform at their best.
Ready to build impactful AI models with the right data? Contact us, and let’s get started today!
Frequently Asked Questions
- What is an object detection dataset?
- It’s a collection of images or videos where objects are labeled to help AI models learn how to recognize and locate them. These labels typically include bounding boxes that show exactly where each object appears in the image.
- What makes the MS COCO dataset popular?
- MS COCO includes a large variety of everyday scenes and objects, with 2D bounding boxes and segmentation annotations across 80 categories. It's great for general object detection tasks, though it doesn’t include 3D data.
- How is the nuScenes dataset different from others?
- nuScenes is designed for autonomous driving and includes data from cameras, LiDAR, and radar sensors. It provides 3D bounding boxes and sensor fusion, helping models understand complex traffic and urban environments.
- Why are bounding box types important in object detection?
- Bounding boxes define where objects are in an image. Different types, like 2D, 3D, or oriented boxes, capture different details, such as depth and rotation. Choosing the right type improves accuracy, especially in real-world or 3D tasks.